Introduction
Modern data ecosystems are experiencing an unprecedented surge in complexity. Organizations no longer rely on a single, isolated relational database to power their business intelligence. Today’s data platforms are intricate webs of distributed systems, incorporating cloud data warehouses, real-time streaming engines, multi-layered transformation frameworks, and decentralized data mesh architectures. While this evolution enables companies to process vast volumes of information, it simultaneously introduces a massive liability: the hidden point of failure. When an upstream API silently updates its payload structure, or an orchestration job finishes successfully despite processing zero records, the entire downstream consumption layer crumbles.
To explore deep structural blueprints, architectural frameworks, and peer discussions surrounding modern data ecosystems, visit TheDataOps, a dedicated platform providing technical resources and operational paradigms for data engineering teams worldwide. By shifting from a reactive posture to a proactive, observability-driven model, organizations can definitively eliminate silent data corruption and build trust across the entire business intelligence lifecycle.
Featured Snippet
What Are DataOps Observability Tools?
DataOps observability tools are specialized software platforms that continuously monitor, track, and analyze the health, state, and performance of data pipelines. By capturing end-to-end metadata across ingestion, storage, and transformation layers, these tools automatically detect anomalies in data quality, schema changes, freshness delays, and lineage, allowing engineering teams to resolve pipeline failures before they impact downstream business operations.
Understanding DataOps
What Is DataOps?
DataOps is an automated, process-oriented methodology used by data managers and engineers to improve the quality and reduce the cycle time of data analytics. Inspired by DevOps and Agile development practices, DataOps brings rigorous software engineering principles—such as automated testing, continuous integration, continuous delivery (CI/CD), version control, and infrastructure as code (IaC)—to the data lifecycle. It represents a cultural and technical shift designed to foster collaboration among data engineers, data scientists, analytics professionals, and business stakeholders.
Evolution of Modern Data Operations
Historically, data management operated within rigid, siloed environments. Data warehouses were updated through monolithic batch processes that ran overnight, managed by centralized IT teams using legacy ETL (Extract, Transform, Load) software. When a pipeline broke, finding and fixing the error took days or weeks due to a lack of documentation, opaque architectures, and minimal automation.
The rise of cloud computing, affordable distributed storage, and the modern data stack transformed this paradigm into ELT (Extract, Load, Transform), where raw data is dumped into cloud data lakes or warehouses and transformed in place using tools like dbt. While this accelerated development speed, it also dramatically increased architectural complexity. Pipelines became distributed networks with hundreds of data sources, multiple transformation steps, and real-time streaming integrations. This rapid evolution rendered manual governance impossible, giving birth to modern DataOps as a necessary discipline to manage data infrastructure reliably at scale.
Why Data Reliability Matters
Data reliability represents the degree to which data can be trusted as accurate, complete, and up to date for operational and analytical decision-making. In a data-driven enterprise, low data reliability triggers a cascading sequence of organizational failures:
- Erosion of Executive Trust: When dashboards present conflicting or incorrect figures, leadership stops relying on automated reports and reverts to making decisions based on intuition.
- Wasted Engineering Velocity: High-value data engineers spend a significant percentage of their working hours on data firefighting—hunting down broken fields and manually reconstructing historical states.
- Compliance and Legal Liabilities: In highly regulated fields such as finance and healthcare, a failure to validate data accuracy or trace its lineage can lead to severe regulatory fines and data privacy violations.
Challenges in Modern Data Pipelines
The modern data pipeline is vulnerable to a wide array of operational failures that elude traditional infrastructure monitoring. Chief among these is silent data degradation, where a system processes information successfully from an infrastructure standpoint, but the underlying data payload becomes corrupted, incomplete, or structurally altered.
Furthermore, data pipelines suffer from operational opacity. As data flows across multi-cloud infrastructure, various messaging queues, and complex transformation models, identifying the exact root cause of a downstream anomaly requires tracing dependencies across dozens of disconnected tools. Without a centralized method to track data lineage and state transitions, pinpointing where an error was introduced becomes a lengthy, error-prone manual investigation.
In Simple Terms
Imagine running a massive regional water utility network. Traditional IT monitoring tells you if the water pumps have electrical power and if the primary pipes are physically intact. DataOps observability, however, is like having digital sensors inside the water itself—continuously testing the water’s purity, chemical balance, and flow speed at every single junction, ensuring that what flows out of a customer’s kitchen tap is perfectly safe to drink.
Real-World Example
A high-growth e-commerce platform relies on a pipeline that ingests inventory updates from thousands of third-party sellers. During a holiday weekend sale, an upstream vendor updates their product management system, replacing an integer field for available_units with a text string containing OUT_of_STOCK. The ingestion pipeline handles the data without crashing, but default processing logic casts the invalid text strings to 0. Without DataOps observability, the platform immediately delists thousands of highly profitable items, resulting in significant revenue losses before anyone notices the error.
Common Mistake
Many engineering teams mistakenly assume that adding rigid assert statements or basic NULL-value checks inside their orchestration workflows constitutes a complete DataOps strategy. In practice, hardcoded assertions lack scalability; they break when business rules change slightly and fail to capture systemic anomalies, such as a subtle drift in statistical averages across a dataset.
Key Takeaways
- DataOps is not just a toolset: It is an organizational methodology that brings DevOps rigor, automated workflows, and continuous testing to the data development lifecycle.
- Infrastructure health does not equal data health: A cloud server can run at optimal CPU efficiency while processing entirely corrupted or empty data files.
- Proactive validation saves reputations: Detecting data anomalies at the ingestion boundary protects downstream business trust and preserves engineering resources.
Understanding Observability in DataOps
What Is Observability?
Observability is a measure of how well the internal states of a system can be inferred from knowledge of its external outputs. Derived from linear control theory, observability in software and data engineering means collecting rich telemetry—such as metrics, logs, traces, and metadata—to build a comprehensive understanding of system behavior. This deep transparency allows teams to diagnose not just when an anomaly occurs, but why it happened, even in highly complex systems experiencing unprecedented edge-case failures.
Monitoring vs. Observability
While the terms are frequently used interchangeably, monitoring and observability represent fundamentally distinct operational methodologies:
| Operational Dimension | Traditional Data Monitoring | Modern Data Observability |
| Operational Core | Tracks predefined metrics to identify known failure modes (“Is the database server online?”). | Explores the internal state of a system to diagnose novel, unexplained anomalies (“Why did this column’s distribution change?”). |
| System Philosophy | Reactive: Alerts the engineering team only when a hardcoded threshold or binary rule is broken. | Proactive: Leverages statistical modeling to detect subtle behavioral deviations and complex system dependencies. |
| Primary Telemetry | System logs, CPU usage, memory utilization, and basic query execution success rates. | Comprehensive metadata, structural changes, column statistics, data lineage, and read/write patterns. |
Why Traditional Monitoring Is Not Enough
Traditional monitoring systems excel at tracking hardware and infrastructure health, such as whether a server is running out of memory or a network connection has dropped. However, they are completely blind to the content of the data payload.
For instance, if an AWS Lambda function executes successfully, your infrastructure monitoring tool flags it green. It has no way of knowing that the function processed an empty JSON payload, resulting in a blank table in your cloud data warehouse. Traditional monitoring tracks the health of the container holding the data, whereas data observability evaluates the integrity of the data itself.
┌────────────────────────────────────────────────────────┐
│ TRADITIONAL MONITORING │
│ [CPU: 22%] [Memory: 45%] [Process Status: OK] │
└───────────────────────────┬────────────────────────────┘
│ (System looks perfect, but...)
▼
┌────────────────────────────────────────────────────────┐
│ DATA OBSERVABILITY │
│ ⚠️ Freshness: 4 hours late ⚠️ Null Rate: Spiked 85% │
└────────────────────────────────────────────────────────┘
Core Goals of Data Observability
The implementation of an observability strategy within DataOps targets four core operational objectives:
- Eliminating Silent Data Failures: Detecting subtle errors—such as corrupted values, truncated strings, or missing data records—the moment they manifest anywhere in the pipeline.
- Drastically Reducing Time to Resolution (MTTR): Providing engineers with instantaneous root cause analysis, clarifying whether an issue stemmed from an upstream schema alteration, an orchestration bug, or a cloud infrastructure failure.
- Mapping End-to-End Dependency Lineage: Tracking data visually from its raw origin through every intermediate transformation, enrichment stage, and BI reporting tool.
- Optimizing System Resource Allocations: Monitoring query performance, storage trends, and data pipeline execution paths to eliminate wasteful cloud spending and streamline operational workflows.
In Simple Terms
Monitoring is like a warning light on your car dashboard that glows when the engine temperature crosses a dangerous threshold. Observability is like having a real-time diagnostic system that analyzes fuel-to-air ratios, spark plug timing, and exhaust composition, showing you exactly why the engine is beginning to run hot before any warning lights turn on.
Real-World Example
A fintech enterprise processes millions of loan applications daily. Their traditional system monitoring confirms that all Kubernetes pods running their processing microservices are completely healthy and handling traffic smoothly. However, their newly deployed data observability platform flags an anomaly: the average value in the credit_score column dropped from 720 to 0 over a trailing 30-minute window. Investigation reveals that an upstream software release introduced a bug that stripped the credit scoring object from the API request payload, generating valid JSON but missing crucial underwriting data.
Common Mistake
A frequent architectural pitfall is relying exclusively on logs generated by data orchestrators (like Apache Airflow) to gauge pipeline health. Orchestrator tasks track execution flows and exit codes, but they cannot assess whether the data loaded into a table is structurally sound or contextually accurate.
Key Takeaways
- Monitoring tells you something failed: Observability provides the rich context needed to understand why it failed and how to prevent it.
- Infrastructure tracking is insufficient: Data health must be verified independently of hardware, network, or container status.
- Context speeds up resolution: Pairing data alerts with precise metadata and system context eliminates hours of manual troubleshooting.
Why DataOps Teams Need Observability Tools
Pipeline Visibility
Modern data operations frequently involve cross-functional pipelines that span multiple organizational boundaries, cloud provider networks, and execution environments. Without purpose-built observability tools, these environments behave like an operational black box. Data enters at the ingestion perimeter, passes through various systems, and appears in business dashboards. When a discrepancy surfaces, tracking down the source requires manual verification across multiple systems. Observability tools shine a light inside this box, providing continuous, granular visibility into every step of the processing lifecycle.
Faster Issue Detection
When a data failure occurs, the clock starts ticking against business operations. If an anomaly takes days to surface, the cost to remediate the corrupted data escalates exponentially, often requiring resource-intensive database rollbacks and complex reconciliation procedures. Observability platforms use automated statistical modeling to set dynamic thresholds for metrics like freshness and volume. This ensures that when an anomaly occurs—such as a data volume drop or an unexpected schema alteration—the on-call engineering team is alerted within minutes, preventing corrupted data from compounding down the line.
[Data Failure Occurs]
│
├─► (Without Observability): Detected by CEO 3 days later ──► Cost: Extreme ($$$$) + Lost Trust
│
└─► (With Observability): Alerted within 4 minutes ─────────► Cost: Minimal ($) + Clean Fix
Improved Data Quality
Data quality is not a static milestone; it is an active operational state. While static, rule-based data quality checks help validate standard conditions (such as ensuring an ID field is never NULL), they cannot account for complex, shifting data trends. Observability tools continuously analyze the underlying distribution of data payloads, flagging issues like data drift—where the statistical profile of incoming data shifts unexpectedly—or anomalies in column variations. This continuous validation keeps data clean and accurate as it moves through the enterprise ecosystem.
Better Collaboration
Data operations involve multiple technical and business teams with varying priorities. Data engineers focus on pipeline uptime, analytics engineers care about model logic, data scientists require reliable features, and business stakeholders demand accurate metrics.
When data breaks, these teams often default to finger-pointing. Data observability platforms serve as a single, objective source of truth. By providing a shared map of data health, data lineage, and clear incident logs, these tools help cross-functional teams collaborate effectively to resolve incidents and maintain high operational standards.
Increased Trust in Analytics
An enterprise data platform is only as valuable as the trust it commands. If a business unit loses faith in their core dashboards due to frequent quality incidents, they will abandon automated data solutions and rebuild manual reporting processes in isolated spreadsheets.
Implementing comprehensive DataOps observability builds systemic confidence. It allows data teams to establish formal Data Service Level Agreements (SLAs). When an issue does arise, the engineering team can proactively post data health notices on status dashboards, proving to stakeholders that the platform is tightly managed, verified, and continuously maintained.
Reduced Operational Risk
Operating blind in a modern regulatory landscape poses a significant corporate risk. Data observability platforms mitigate this risk by acting as a continuous governance engine. By automatically documenting structural mutations, security access records, and data movement maps, these platforms provide teams with clear verification capabilities for audits and compliance. Furthermore, by identifying underutilized datasets, redundant storage blocks, and inefficient queries, observability tools help optimize resource use and reduce unnecessary cloud expenditure.
In Simple Terms
Think of a data observability tool as an automated quality control inspector in a high-tech manufacturing plant. Instead of waiting for a customer to receive a defective product and complain, the automated inspector flags misaligned parts, structural defects, and material anomalies right on the assembly line, stopping the conveyor belt to fix issues immediately.
Real-World Example
A global ride-sharing application processes billions of location coordinates and payment events daily. Their analytics team relies on this data to adjust dynamic surge pricing algorithms in real time. When an external telecommunications provider experiences a network hiccup, location metadata packets from iOS devices are corrupted, causing coordinates to swap latitude and longitude values.
The data engineering team’s observability platform instantly flags this geographical distribution anomaly, automatically routing traffic to a backup data stream and saving the company from severe pricing errors across its major metropolitan markets.
Common Mistake
A frequent mistake made by growing organizations is delaying the adoption of observability tools until after a catastrophic data incident occurs. Building an engineering platform without observability is like driving a vehicle at high speeds at night without headlights; you are guaranteed to crash eventually, and the cost of recovery will vastly exceed the price of prevention.
Key Takeaways
- Manual verification fails at scale: Automated pipelines require automated quality validation and anomaly detection engines.
- Trust is fragile and costly to rebuild: Proactive alerts keep downstream business reports reliable and preserve stakeholder confidence.
- Observability lowers operational risk: Comprehensive lineage tracking and metadata visibility protect the business against both compliance gaps and systemic engineering failures.
The Five Pillars of Data Observability
To manage large data systems effectively, engineers break down data platform health into five core dimensions, known as the Five Pillars of Data Observability.
┌─────────────────────────────────────────────────────────────────────────┐
│ FIVE PILLARS OF DATA OBSERVABILITY │
├─────────────┬─────────────┬──────────────┬──────────────┬───────────────┤
│ FRESHNESS │ VOLUME │ SCHEMA │ DISTRIBUTION │ LINEAGE │
│ Is the data│ Did we get │ Did columns │ Are values │ Where did it │
│ up to date?│ all of it? │ change type? │ shifting? │ come from? │
└─────────────┴─────────────┴──────────────┴──────────────┴───────────────┘
1. Freshness
Definition
Freshness defines how up to date your data assets are and describes the age of the records relative to the physical passage of time.
Importance
Business operations require timely updates to maintain operational accuracy. If a data asset does not refresh on schedule, downstream decisions will be based on stale, outdated information.
Real-World Example
An automated financial trading algorithm ingests market ticker files every sixty seconds. If an ingestion container stalls and data delivery falls five minutes behind schedule, the algorithm will make high-risk trades based on outdated pricing data, creating significant financial risk.
Typical Issues Detected
- Stalled orchestration schedules or hung ETL pipelines.
- Upstream API delivery delays.
- Slow query executions causing cron schedule overruns.
2. Volume
Definition
Volume measures the quantity of data arriving within a dataset, typically tracked by total row count, file sizes, or byte volumes.
Importance
Volume tracks whether your datasets are complete. An unexpected drop or surge in row counts usually indicates an underlying ingestion failure, duplicate records, or a broken upstream source.
Real-World Example
A streaming media platform expects roughly 10 million telemetry rows per hour from its global web applications. If an infrastructure update accidentally detaches the analytics tracker from the web client, the hourly volume will plunge to 1.5 million rows, an anomaly that requires immediate engineering attention.
Typical Issues Detected
- Empty source files loading successfully due to loose constraints.
- Accidental Cartesian joins creating millions of duplicate rows.
- Partial data transfers caused by unhandled network timeouts.
3. Schema
Definition
Schema monitors the structural organization of your database tables, including column names, data type classifications, nesting levels, and primary key constraints.
Importance
The applications that consume data are highly sensitive to structural mutations. If an upstream team modifies a column from an integer to a string, or drops a field entirely, downstream SQL transformations and BI models will fail immediately.
Real-World Example
A logistics firm relies on a column named postal_code formatted as an alphanumeric string. An upstream software engineer refactors the source database, renaming the column to zip_code and casting it as an integer. This structural change breaks all downstream analytics models that rely on the original column name.
Typical Issues Detected
- Unexpected column deletions or modifications.
- Data type changes that trigger runtime errors during casting.
- The drift of undocumented parameters into unstructured JSON elements.
4. Distribution
Definition
Distribution tracks the statistical profile and variance of values contained within a specific dataset field, observing patterns like averages, null rates, and standard deviations.
Importance
Even if a pipeline is on time, matches expected volumes, and maintains its schema, the values themselves can still be completely incorrect. Monitoring distributions ensures that data stays within acceptable, realistic parameters.
Real-World Example
A health insurance provider processes claims data where the patient_age column historically ranges from 0 to 105, with an average value of 42. Following a corrupt database migration, a system bug writes the default value -1 into this field for thousands of rows. While the pipeline runs without throwing structural errors, the average age drops to 12, alerting the team to a major data quality issue.
Typical Issues Detected
- A sudden spike in the frequency of
NULLor empty values. - Numeric values falling outside logical or physical boundaries.
- Text fields failing regex validation or country code constraints.
5. Lineage
Definition
Lineage maps the end-to-end journey of your data, documenting every upstream source, intermediate pipeline, database table, and downstream dashboard asset.
Importance
Lineage provides the structural context that makes the other four pillars actionable. When an anomaly is detected, lineage allows engineers to trace upstream to find the root cause and look downstream to see exactly which reports are affected.
Real-World Example
An analyst notes that a key revenue metric in a Looker dashboard looks wrong. By using an interactive data lineage map, the on-call engineer can instantly track the metric back through three layers of dbt models, an incremental Snowflake table, and an external Fivetran connector, identifying the exact raw table where the error originated.
Typical Issues Detected
- Orphaned database tables that consume processing resources but serve no downstream assets.
- Unintended dependencies where critical tables rely on unverified test environments.
- Cascading failure zones, showing exactly which teams will be hit by an upstream pipeline delay.
In Simple Terms
Think of the Five Pillars like checking a shipment of medication to a pharmacy. Freshness ensures the medicine was delivered today, not last month. Volume confirms all one thousand bottles arrived safely. Schema verifies that the bottles are labeled with the correct sections for ingredients and expiration dates. Distribution ensures each pill contains exactly 50mg of the active compound, not 0mg or 500mg. Finally, Lineage provides a complete audit trail tracing the batch from the delivery truck all the way back to the manufacturing laboratory.
Real-World Example
An international aviation carrier tracks flight performance data. Their observability platform works across all five pillars simultaneously: it verifies that flight log records arrive every fifteen minutes (Freshness), confirms that the count of logged flights matches actual air traffic control handoffs (Volume), guarantees that the latitude and longitude fields maintain their decimal data types (Schema), checks that flight speeds stay within realistic aerodynamics limits (Distribution), and maps this entire flow directly into the safety and compliance dashboards used by operations teams (Lineage).
Common Mistake
A common architectural mistake is prioritizing the implementation of deep statistical distribution tracking before establishing reliable basic monitoring for freshness and volume. Teams that do this often find themselves overwhelmed by complex statistical alerts while missing simple, critical pipeline delays.
Key Takeaways
- The pillars form an interdependent framework: You need coverage across all five dimensions to ensure comprehensive data reliability.
- Lineage turns data alerts into actionable insights: Knowing where data flows is essential for efficient troubleshooting.
- Distribution monitoring stops silent data corruption: Tracking the statistical characteristics of your data catches errors that slip past structural checks.
Core Features of DataOps Observability Tools
Automated Monitoring
Modern observability tools minimize the need for manual configuration by automatically scanning your data environment. Upon connection to a data warehouse or orchestration layer, these systems analyze historical metadata to establish a baseline for standard operational behavior. The platform then automatically configures threshold metrics for freshness, volume variations, and structural changes without requiring engineers to write custom validation scripts for every new table.
Data Quality Validation
Beyond baseline anomaly detection, observability tools feature declarative data quality validation frameworks. These modules allow engineers to implement explicit, rule-based tests on critical data fields. Teams can define exact validation parameters—such as checking that field values fall within an allowed list, ensuring primary keys are strictly unique, or validating format patterns with regular expressions—guaranteeing that data meets specific business requirements before reaching production.
Root Cause Analysis
When an engineering team is woken up by a pipeline failure alert at midnight, they don’t want to spend hours running manual SQL queries to locate the issue. Advanced observability platforms feature automated root cause analysis engines that immediately isolate the source of trouble. By correlating infrastructure logs, orchestrator states, code deployments, and data structural shifts, the platform can pinpoint the exact cause of an incident, such as a specific dbt model update that dropped an essential indexing tag.
┌───────────────────────────────┐
│ Data Observability Engine │
└───────────────┬───────────────┘
│
┌────────────────────────┼────────────────────────┐
▼ ▼ ▼
[Infrastructure Logs] [Orchestrator States] [Code Deployments (git)]
│ │ │
└────────────────────────┼────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Automated Root Cause Diagnosis Output │
└─────────────────────────────────────────┘
Alerting and Notifications
An observability tool is only as effective as its integration into an engineering team’s operational workflow. These platforms provide highly configurable alerting engines that route notifications based on severity, data ownership, and incident context. Rather than blasting generic alert emails to the entire engineering department, notifications can be precisely routed—such as sending a critical distribution anomaly alert to a dedicated Slack channel or triggering an automated PagerDuty incident for the on-call team.
Metadata Management
At the core of data observability is the continuous collection and analysis of unified metadata. These systems systematically read, catalog, and store structural logs, database catalogs, query execution patterns, and compliance classifications from across your entire data infrastructure. This creates a centralized, highly accessible record of data operations, breaking down the information silos that often develop between disparate cloud warehouses, streaming platforms, and business intelligence applications.
Lineage Tracking
Observability platforms use automated SQL parsing technology to construct and maintain live data lineage diagrams. By analyzing compilation records, query histories, and transformation logs, the platform automatically maps the relationships between upstream tables, views, intermediate datasets, and downstream reporting assets. This automated mapping eliminates the need for teams to manually maintain static architecture diagrams, keeping dependency maps accurate in real time.
[Raw Ingestion Table] ──(SQL Parse)──► [dbt Staging Model] ──(SQL Parse)──► [BI Reporting View]
Incident Investigation
When an alert is triggered, observability platforms provide dedicated incident response workspaces to streamline troubleshooting. These interactive dashboards compile all relevant context for the issue into a single view, including historical variance charts, sample lines of anomalous records, affected downstream assets, and assigned team ownership. This central workspace prevents engineers from having to hunt through multiple tools, allowing them to assess scope and begin remediation immediately.
Dashboarding and Reporting
To support long-term data strategy, observability tools offer comprehensive reporting capabilities designed for technology leadership and compliance officers. These dashboards track macro-level operational metrics over time, including overall system uptime, mean time to detection (MTTD), mean time to resolution (MTTR), and data quality compliance trends across different business units. This high-level visibility helps engineering managers justify infrastructure investments, optimize resource allocation, and track data team efficiency.
In Simple Terms
Consider these features like the automated flight management computer on a modern passenger jet. It doesn’t just display your current airspeed; it continuously scans all engine subsystems, maps your flight path against changing weather patterns, alerts the pilots to specific mechanical anomalies, and documents every flight parameter for maintenance audits, ensuring the aircraft operates safely and efficiently.
Real-World Example
A large streaming platform uses an observability system to manage its real-time recommendation data. When an engineering team deploys a buggy update to a consumer-facing application, the application begins sending invalid empty arrays for user interest tags.
The observability platform’s Automated Monitoring flags the drop in tag volume, its Lineage Tracking immediately identifies which downstream recommendation algorithms are affected, its Root Cause Analysis links the issue directly to the recent application deployment, and its Alerting Engine sends an urgent ticket directly to the mobile development team for an immediate rollback.
Common Mistake
A frequent implementation mistake is allowing an observability tool to broadcast alerts to generic communication channels without defining clear ownership boundaries. This lack of routing quickly causes alert fatigue, leading engineers to mute notifications and inevitably miss critical system failures.
Key Takeaways
- Unified metadata powers deep insight: Centralizing your operational metadata is essential for accurate system troubleshooting.
- Automation keeps pace with scaling pipelines: Manual testing strategies cannot handle the speed and complexity of modern data stacks.
- Smart routing prevents alert fatigue: Ensuring alerts are context-rich and sent directly to the responsible team keeps incident response efficient.
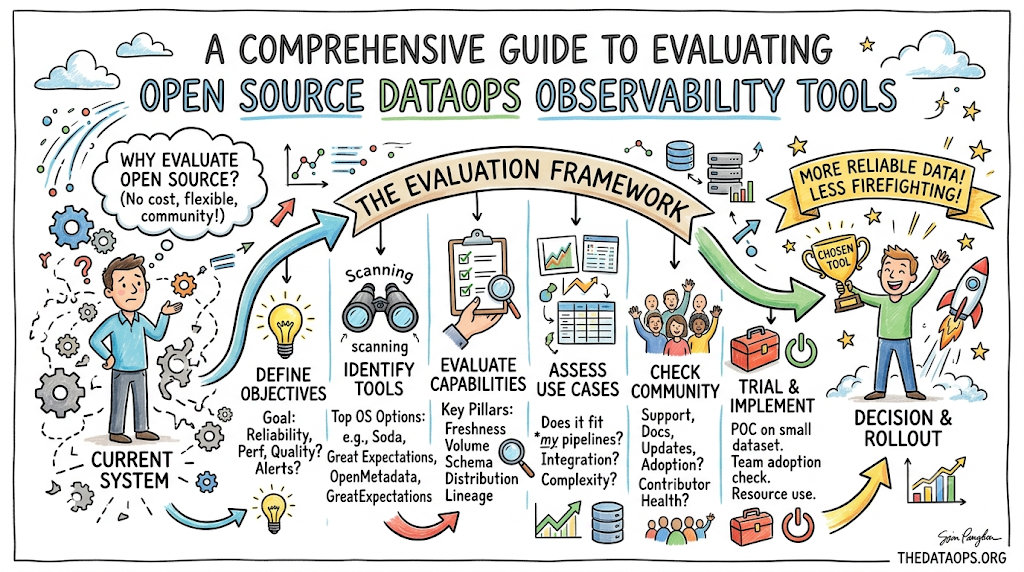
Leading DataOps Observability Tools
Selecting the right platform requires an understanding of the strengths, architecture types, and ideal operational use cases for the top options in the market.
Monte Carlo
Overview
Monte Carlo is an enterprise-grade data observability platform known for popularizing the “Five Pillars of Data Observability.” It operates as a fully managed, commercial SaaS solution designed to provide end-to-end data reliability across complex, cloud-native environments.
Key Features
- An end-to-end lineage mapping engine that links data assets from raw ingestion sources down to individual Business Intelligence elements.
- Automated, machine learning-driven anomaly detection thresholds that adapt to historical metadata without manual coding.
- A centralized data incident management studio built for cross-functional engineering collaboration and remediation.
Strengths
- Rapid onboarding: Connects to standard cloud data stacks using secure, metadata-only API integrations.
- Excellent UX/UI: Offers intuitive interfaces suitable for both deeply technical engineers and business analysts.
- Strong cross-tool integration: Connects natively with tools like Snowflake, dbt, Airflow, and Looker.
Limitations
- Premium pricing structure: Can be cost-prohibitive for early-stage startups or smaller data teams.
- Black-box algorithms: The inner workings of its proprietary machine learning anomaly models are not visible to users.
Best Use Cases
Enterprise organizations running large-scale cloud data warehouses with hundreds of tables, multiple business units, and extensive BI consumption layers.
Ideal Team Size
15+ Data Professionals.
Learning Curve
Low to Moderate.
Bigeye
Overview
Bigeye is a commercial, enterprise-focused data observability platform designed for deep data quality tracking. It excels at helping teams define, monitor, and enforce granular data reliability metrics at scale.
Key Features
- An automated metric recommendation engine that analyzes database columns and suggests relevant quality thresholds (e.g., null ratios, string formats).
- A flexible data profiling engine that monitors statistical distributions across historical timelines.
- Customizable alerting logic designed to integrate with corporate messaging platforms and ticketing workflows.
Strengths
- Granular mathematical tracking: Highly effective at identifying subtle distribution anomalies within massive tables.
- Deep analytical interface: Ideal for teams that want to dive deep into statistical metrics and historical variance trends.
- User-friendly dashboarding: Simplifies tracking compliance against corporate data SLAs.
Limitations
- High configuration requirements: Achieving deep coverage requires more intentional setup compared to fully automated platforms.
- Ecosystem focus: Designed primarily for structured data warehouses, with fewer features for unstructured or streaming raw data lakes.
Best Use Cases
Data teams managing complex financial models, regulatory reporting, or advanced machine learning training pipelines that require precise data quality validation.
Ideal Team Size
10–50 Data/Analytics Engineers.
Learning Curve
Moderate.
Databand
Overview
Acquired by IBM, Databand is an execution-focused data observability platform built to optimize pipelines and orchestration systems, particularly for teams using Apache Airflow.
Key Features
- Deep integration with orchestrators (Airflow, Argo) to track task runtimes, failure states, and execution histories.
- Cross-system metadata correlation that links data state changes directly to specific code execution steps.
- An automated lineage framework centered around dataset processing jobs and computational tasks.
Strengths
- Orchestration visibility: Provides exceptional troubleshooting insights for complex, multi-stage DAG workflows.
- Proactive engineering alerts: Catches pipeline stalls, task bottlenecks, and infrastructure drops before they impact data tables.
- Strong support for open-source tools: Integrates smoothly into custom Python, Spark, or Kubernetes execution environments.
Limitations
- Operational focus: Primarily tracks process and orchestration metrics, with less focus on deep data value distribution statistics.
- Setup complexity: Requires integrating custom libraries and tracking agents directly into pipeline codebase repositories.
Best Use Cases
Engineering-centric data teams running large, complex orchestrations, distributed Spark tasks, or custom data applications.
Ideal Team Size
8–40 Engineers.
Learning Curve
Moderate to High.
Acceldata
Overview
Acceldata is an enterprise data observability platform designed to provide comprehensive visibility across data compute infrastructure, pipeline operations, and underlying data quality.
Key Features
- Comprehensive compute environment monitoring that tracks queries, memory use, and resource allocation across systems like Snowflake and Databricks.
- Automated data quality tracking across hybrid environments, including both cloud data warehouses and on-premise Hadoop/Spark clusters.
- An enterprise-grade asset catalog featuring automated data discovery, structural logging, and lineage mapping.
Strengths
- Cost and compute transparency: Excellent tool for identifying expensive, inefficient queries and optimizing cloud warehouse spend.
- Hybrid architecture support: One of the few platforms that monitors both legacy on-premise infrastructure and modern cloud systems.
- Highly scalable architecture: Built to ingest and process massive volumes of operational telemetry.
Limitations
- Complex deployment footprint: Setting up full-stack compute and quality tracking requires significant initial effort and access permissions.
- Interface complexity: The broad feature set can feel overwhelming for small teams focused solely on basic data quality.
Best Use Cases
Large Fortune 500 enterprises navigating hybrid cloud migrations, running massive big-data clusters, or managing multi-million dollar cloud data warehouse budgets.
Ideal Team Size
25+ Infrastructure and Data Engineers.
Learning Curve
High.
Soda
Overview
Soda provides an open-source framework (Soda Core) combined with a commercial cloud interface (Soda Cloud). It allows engineering teams to implement developer-centric, code-driven data quality testing and observability.
Key Features
- SodaCL (Soda Check Language): A human-readable, declarative language used to define data quality checks in simple YAML files.
- A programmatic testing engine designed to run seamlessly inside developer CI/CD workflows and orchestration steps.
- A cloud dashboard that aggregates test results, alerts teams to historical anomalies, and manages incident workflows.
Strengths
- Developer-first design: Integrates naturally with standard git-based development workflows, making it popular with analytics engineers.
- Highly customizable: SodaCL allows teams to write precise, complex quality rules without writing verbose SQL code.
- Flexible open-source tier: Soda Core is completely free and open-source, lowering the barrier to entry for early-stage teams.
Limitations
- Manual configuration required: Relies on explicitly defined checks rather than out-of-the-box machine learning automation.
- Lineage scope: Lineage tracking is less automated compared to enterprise-focused SaaS platforms.
Best Use Cases
Agile data teams that prefer code-based configuration, value open-source tools, and want to integrate data quality tests directly into their dbt pipelines and deployment workflows.
Ideal Team Size
4–30 Analytics Engineers.
Learning Curve
Moderate.
Great Expectations
Overview
Great Expectations (GX) is the most widely adopted open-source Python framework for parsing, validating, and documenting data. It serves as a foundational data quality testing standard for modern data teams.
Key Features
- Expectations: A highly expressive Python API providing hundreds of predefined validation assertions (e.g.,
expect_column_values_to_be_between). - Data Docs: Automatically generated, clean HTML dashboards that display test results and describe expectations as plain-english validation rules.
- Automated Profiling: Tools that evaluate existing database tables and automatically generate a baseline set of expectations.
Strengths
- Extensive community and ecosystem: Massive community support with native integrations across almost all major orchestration and execution platforms.
- Total architectural control: Because it is a code-native Python library, it can be customized to fit any internal platform requirements.
- Zero licensing costs: The core framework is completely open-source, making it accessible to any organization.
Limitations
- No real-time observability UI: Lacks live, interactive alerting dashboards out of the box (requires setting up their newer commercial platform or external tools).
- High maintenance overhead: Managing large suites of expectations across hundreds of production tables requires substantial engineering time and code organization.
Best Use Cases
Data engineering teams that want complete control over their validation logic and need to embed programmatic tests directly into Python pipelines, Spark jobs, or Airflow workflows.
Ideal Team Size
2–50+ Python-proficient Engineers.
Learning Curve
Moderate to High.
Datafold
Overview
Datafold is a developer-centric data observability tool built specifically to optimize the code deployment and regression testing phases of the analytical lifecycle.
Key Features
- Data Diff: A specialized processing engine that compares billions of rows between two database tables and highlights every modified, missing, or new value.
- Automated CI/CD integration that presents data diff summaries directly inside developer pull requests on GitHub or GitLab.
- Automated impact analysis that shows exactly how a modified dbt transformation model will change downstream BI reports before merging code.
Strengths
- Prevents bugs in production: Stops data quality issues from being introduced in the first place by shifting validation to the development phase.
- Developer efficiency: Saves hours of manual QA work by instantly showing engineers the exact downstream impact of code changes.
- Blazing fast diff engine: Optimized to compare massive development environment tables against production datasets in seconds.
Limitations
- Specific operational scope: Built primarily to optimize development workflows and deployment QA, rather than serving as a general-purpose, production-wide anomaly detection platform.
- Requires modern setup: Maximizing its value requires a mature development pipeline, including dbt use, git version control, and automated CI/CD practices.
Best Use Cases
Fast-moving data and analytics teams using dbt who want to implement automated regression testing and prevent breaking updates from ever reaching production dashboards.
Ideal Team Size
5–30 Analytics Engineers.
Learning Curve
Low to Moderate.
Metaplane
Overview
Metaplane is a fast-deploying commercial data observability solution tailored specifically for high-growth startups and mid-market organizations using modern cloud data stacks.
Key Features
- An automated anomaly detection system that tracks freshness, volume variations, and schema mutations using machine learning models.
- Deep integrations with business intelligence platforms (such as Looker, Tableau, and Sigma) to map end-to-end data dependencies.
- A collaborative Slack application interface that allows teams to receive alerts, claim incidents, and log notes without leaving their workspace.
Strengths
- Fast time-to-value: Can be connected to a standard cloud stack (e.g., Fivetran, Snowflake, dbt, Looker) and begin monitoring in less than thirty minutes.
- Intuitive UI/UX: Simplifies data observability for smaller teams that do not have dedicated reliability architects.
- Clear business context: Excellent lineage mapping into downstream BI systems helps show exactly how pipeline issues affect executive reports.
Limitations
- Customization limits: Offers less control over specialized statistical testing logic compared to enterprise data quality frameworks.
- Ecosystem limitations: Optimized for cloud data warehouses, making it less suitable for legacy on-premise systems or complex streaming data setups.
Best Use Cases
Fast-growing data teams using modern cloud data warehouses who need comprehensive, automated observability with minimal setup overhead and deep BI tracking.
Ideal Team Size
2–15 Data Professionals.
Learning Curve
Very Low.
Anomalo
Overview
Anomalo is an enterprise-grade data quality and observability platform that relies on advanced unsupervised machine learning to detect deep data anomalies without manual configuration or rule writing.
Key Features
- An automated data profiling engine that monitors statistical distributions across every column in a table, tracking multi-variant trends.
- Automated root cause analysis that isolates specific segments of data (e.g., identifying that an error occurs only for iOS users in Germany) to pinpoint systemic issues.
- An integrated documentation system that automatically captures data patterns, valid ranges, and structural changes over time.
Strengths
- Deep statistical detection: Highly effective at finding subtle, complex data errors that simple rules-based checks miss entirely.
- Actionable insights: Instead of just sending an alert that an average dropped, it isolates the exact cohort of records causing the change.
- Minimal manual upkeep: The platform’s automated models handle configuration and maintenance, minimizing manual testing work.
Limitations
- High compute footprint: Deep statistical profiling requires running complex queries on your cloud warehouse, which can increase compute costs if not carefully managed.
- Enterprise focus: The platform’s feature set and pricing model are designed for larger organizations, making it a heavy lift for small teams.
Best Use Cases
Enterprises managing large, complex datasets where finding data issues requires deep multivariate analysis, such as consumer transaction tracking or user behavioral analytics.
Ideal Team Size
15+ Data Architects and Scientists.
Learning Curve
Moderate.
OpenMetadata
Overview
OpenMetadata is an open-source data governance and metadata platform that includes built-in capabilities for data collaboration, lineage tracing, and data quality profiling.
Key Features
- A centralized, open-standard metadata repository that unifies data discovery, data lineage, and data quality tracking under a single architecture.
- An integrated workflow system that allows teams to run profiling tasks, define quality test suites, and track data health scores across assets.
- A user-friendly web UI designed to help data teams discover, document, collaborate on, and govern data assets across the enterprise.
Strengths
- Unified operational view: Combines data observability, data cataloging, and data governance into a single open-source solution.
- Open standards: Built on a standardized metadata schema, preventing vendor lock-in and allowing teams to extend the platform via APIs.
- Strong collaboration features: Includes built-in messaging feeds, task tracking, and data ownership tools right alongside dataset profiles.
Limitations
- Operational overhead: Running, scaling, and hosting the open-source platform requires dedicated internal infrastructure management.
- Specialized feature depth: While it offers broad capabilities across governance, discovery, and observability, it may lack the specific deep anomaly detection features found in dedicated SaaS platforms.
Best Use Cases
Organizations seeking an open-source solution that unifies data governance, data asset discovery, metadata management, and pipeline observability into a single platform.
Ideal Team Size
10+ Platform and Governance Engineers.
Learning Curve
Moderate to High.
DataOps Observability Tools Comparison Table
| Tool | Data Quality Monitoring | Lineage | Alerting | Ease of Use | Open Source / Commercial | Best For |
| Monte Carlo | Automated + Manual | End-to-End | Advanced (Slack, PagerDuty) | High | Commercial | Full-stack enterprise data reliability and lineage visibility. |
| Bigeye | High-Granularity Metrics | Basic | Flexible Routing | Moderate | Commercial | Deep statistical monitoring for critical financial and ML data. |
| Databand | Orchestration Centric | Pipeline Focused | Immediate Alerts | Moderate | Commercial | Engineering teams optimizing Airflow workflows and complex compute tasks. |
| Acceldata | Compute + Quality | Hybrid Maps | Enterprise Engine | Complex | Commercial | Large corporations managing hybrid data environments and cloud costs. |
| Soda | Code-Native Checks | Moderate | Cloud Alerts | Moderate | Open Source + Cloud | Analytics engineering teams looking for code-defined quality checks in CI/CD. |
| Great Expectations | Comprehensive Validation | None (Manual) | Requires Extension | Developer Focused | Open Source | Programmatic, code-driven data asset testing within Python frameworks. |
| Datafold | Regression Testing | BI Impact Maps | PR Integrated | High | Commercial | Teams looking to automate QA and catch breaking data mutations in code reviews. |
| Metaplane | Automated Anomaly | Warehouse to BI | Slack Centric | Very High | Commercial | Fast-growing teams needing quick setup and clear visibility from data to BI dashboards. |
| Anomalo | Unsupervised ML | Basic | Context-Rich Alerts | High | Commercial | Deep multivariate anomaly detection on massive web or app transaction tables. |
| OpenMetadata | Unified Profiling | Governance Map | Native Tasks | Moderate | Open Source | Organizations looking to unify data discovery, governance, and quality in one tool. |
Data Observability vs. Traditional Data Monitoring
To clarify how these methodologies operate in practice, this framework details how traditional monitoring and modern data observability handle identical pipeline challenges.
| Operational Area | Traditional Infrastructure Monitoring | Modern Data Observability Platforms |
| System Visibility Scope | Limited to system processes, tracking whether database connections are open, servers are online, and scripts exit without errors. | Comprehensive system and data tracking, mapping metadata, data schemas, value distributions, and full asset lineage. |
| Root Cause Analysis | Requires manual inspection, forcing engineers to check individual server logs and trace system configurations step-by-step. | Automated root cause analysis, instantly isolating incidents by linking data drift to specific upstream schema changes or deployments. |
| Automation Capabilities | Relies on manual rules, requiring engineers to explicitly define static performance thresholds (e.g., Alert if CPU utilization exceeds 85%). | Leverages adaptive machine learning to automatically establish baseline operational metrics and detect anomalies without code. |
| Data Quality Coverage | Non-existent; cannot read data payloads or detect structural mutations inside processing containers. | Built-in data quality tracking, continuously monitoring values for missing fields, schema changes, and statistical distribution drift. |
| Alert Intelligence | Can cause high alert noise by broadcasting generic system failures without providing business context or indicating downstream impact. | Context-rich alerting that routes notifications based on data asset ownership and maps exactly which business dashboards are affected. |
| Business Impact | Reactive stance; failures are often only discovered after broken infrastructure causes downstream reports to break or go offline. | Proactive prevention; identifies data health anomalies early in the pipeline, allowing engineers to fix errors before they reach business users. |
Data Quality and Observability
Missing Data Detection
Data missing from a system can be subtle and difficult to detect. A pipeline may execute without errors while transferring only a fraction of the expected data records.
Observability platforms continuously evaluate incoming data volume against historical baseline expectations for that specific day and hour. If an ingestion task loads only 40,000 rows when historical trends predict 120,000 rows, the system flags a volume anomaly, allowing teams to catch partial data losses immediately.
Data Drift Detection
Data drift occurs when the statistical properties of an incoming dataset change unexpectedly over time, even while the data structure remains perfectly intact. This is particularly problematic for machine learning and predictive analytics models.
Observability tools track changes in data distributions by calculating statistical scores (such as the Kolmogorov-Smirnov test) across columns. If a feature’s median, variance, or value distribution shifts beyond normal operating parameters, the platform alerts the team, preventing model degradation.
[Historical Ingest Baseline] ───► Median Value: 42.0 (Stable Variance)
│
▼ (Sudden Data Drift Occurs)
[Anomalous Live Ingest] ───► Median Value: 11.5 (⚠️ Anomaly Flagged)
Schema Changes
In fast-moving engineering organizations, upstream application developers frequently modify database structures to support new product features. If these changes are deployed without notifying the data team, downstream transformation models and pipelines will break immediately.
Observability tools actively monitor the structural catalog of your databases. The moment a column is dropped, an attribute data type is modified, or a new parameter is added to a table, the tool logs the schema change and alerts the team, reducing the time spent troubleshooting mysterious pipeline failures.
Anomaly Detection
Traditional testing frameworks rely on hardcoded rules to catch known errors, but they are blind to unexpected edge-case failures.
Observability platforms address this by using machine learning models to analyze multiple metadata attributes simultaneously—including ingestion timing, row volumes, null counts, and query performance. This allows the system to detect complex, unpredicted anomalies that would slip past standard rule-based tests, providing comprehensive protection for your data infrastructure.
Data Consistency Validation
Large enterprise architectures often copy and move critical data assets across multiple cloud storage zones, operational databases, and centralized warehouses. Ensuring that data remains accurate and consistent across these different systems is a significant challenge.
Observability tools use automated metadata comparisons and row hashing to verify data consistency across environments. If an aggregate revenue total in an operational database diverges from the corresponding record in the reporting warehouse, the observability tool highlights the mismatch, helping teams maintain a reliable, unified source of truth.
In Simple Terms
Think of data quality monitoring as checking a food package to confirm it has an expiration date printed on it. Data observability is like having a digital laboratory system that tests the food’s actual nutritional value, texture, and ingredient balance over time, ensuring the product is genuinely safe and high-quality before it hits store shelves.
Real-World Example
A global property rental application stores booking transactions in an un-indexed document database. An upstream software team deploys an update that alters the structure of the checkout payload, changing the nested field user_payment_info.billing_currency from an uppercase ISO string (e.g., "USD") to a lowercase format ("usd").
The platform’s data observability engine instantly flags this structural shift as a schema mutation and flags the unexpected lowercase values as a distribution anomaly. This early warning allows analytics engineers to update their transformation models before the morning business intelligence reports run.
Common Mistake
A frequent architectural mistake is relying entirely on static, manual data tests to maintain data quality. While explicit tests are helpful for verifying fixed business rules (like ensuring an ID field is never null), relying on them exclusively forces engineers to spend excessive time writing and updating hundreds of code-based constraints as the platform grows.
Key Takeaways
- Static validation has limits: Relying solely on hardcoded rules creates blind spots for unexpected, complex data failures.
- Data drift distorts analytics: Changes in value distributions can corrupt business insights and machine learning models even if pipelines run without errors.
- Schema mutations require immediate alerts: Automating the detection of structural changes prevents breaking failures from cascading through downstream models.
Observability Across the Data Pipeline
To ensure complete reliability, an observability strategy must track data as it moves through every stage of the lifecycle, from initial ingestion to end-user reporting.
[Data Ingestion] ──► [Data Transformation] ──► [Data Warehousing] ──► [Analytics / BI]
• Verify Volume • Code Regression QA • Schema Tracking • Lineage Context
• Ingestion Timeliness • Execution Telemetry • Cost Optimization • End-User Trust
Data Ingestion
The ingestion layer is the perimeter of your data architecture, pulling raw data from application databases, third-party APIs, and streaming queues via tools like Fivetran or Kafka. Implementing observability at this boundary allows teams to check data volume completeness and delivery timeliness immediately upon arrival. Catching anomalies here prevents corrupted or incomplete data from entering the warehouse, keeping early-stage processing clean.
Data Transformation
Once loaded, raw data goes through cleaning, aggregation, and modeling stages, typically managed by frameworks like dbt or Apache Spark. Observability during transformation tracks code changes, regression testing results, and model runtimes. By comparing data outputs before and after code changes, teams can prevent breaking data models from being deployed, keeping transformation logic stable and dependable.
Data Warehousing
The cloud data warehouse (such as Snowflake, BigQuery, or Databricks) serves as the central data repository for the enterprise. Observability at this layer focuses on monitoring schema health, tracking storage patterns, and analyzing query execution performance. By continuously monitoring warehouse catalogs and query logs, observability systems help protect structural integrity while highlighting inefficient queries to optimize cloud compute spend.
Analytics Layers
The analytics layer translates structured warehouse tables into business-ready metrics, semantic definitions, and feature stores for machine learning models. Observability tools maintain data consistency here by verifying that calculation logic, data formats, and access permissions stay uniform across different models. This keeps core business definitions aligned, ensuring that different teams generate consistent insights from the same underlying data.
Reporting Systems
Reporting systems and BI platforms (such as Looker, Tableau, or PowerBI) represent the final consumption layer where data is delivered to business decision-makers. Observability tools extend clear visibility into this layer by using data lineage to map backend warehouse tables directly to specific dashboard components. This end-to-end connection allows engineers to immediately identify which reports are affected by an upstream issue, ensuring business users are proactively notified before making decisions based on inaccurate data.
In Simple Terms
Imagine managing a modern food processing facility. You need to inspect the quality of raw ingredients as they arrive at the loading dock (Ingestion), monitor the mixing and cooking temperatures in the vats (Transformation), check the storage conditions in the central freezer (Warehousing), verify the packaging line accuracy (Analytics), and inspect the final product boxes before they load onto delivery trucks (Reporting).
Real-World Example
A digital healthcare enterprise tracks patient health trends across its platform. Their observability architecture monitors the entire data lifecycle: it validates the daily volume of encrypted records arriving from clinic networks (Ingestion), checks for calculation errors within dbt models that aggregate patient metrics (Transformation), monitors table access patterns inside BigQuery to ensure data security compliance (Warehousing), maintains uniform metrics within the semantic layer (Analytics), and uses data lineage to map updates directly to patient-facing wellness dashboards (Reporting).
Common Mistake
Many organizations implement observability only within their central data warehouse while ignoring the ingestion perimeter and final BI layers. This partial visibility creates operational blind spots, making it difficult to trace whether a data error stemmed from a broken upstream API or an internal transformation bug.
Key Takeaways
- End-to-end visibility is essential: Achieving true data reliability requires tracking data health across every stage of the pipeline.
- Boundary validation simplifies troubleshooting: Catching errors at the ingestion layer prevents bad data from corrupting downstream tables.
- Lineage protects the consumption layer: Connecting backend warehouse tables directly to front-end BI dashboards allows teams to manage data incidents proactively.
Real-World DataOps Observability Use Cases
Financial Services
Data Challenge
A multinational banking platform processes millions of credit card transactions every hour across various microservices. The core data team struggled with silent data corruption caused by mid-day API updates, which introduced missing values into customer transaction logs and led to inaccurate balance calculations on customer dashboards.
Observability Approach
The team deployed an automated data observability platform connected to their Snowflake warehouse and Apache Airflow orchestrators, setting up automated freshness and distribution tracking on all core transaction ledgers.
Business Benefits
The platform reduced the mean time to detection (MTTD) for data anomalies from three days to under five minutes, allowing teams to catch and resolve ingestion failures before they could affect consumer-facing account balances.
Lessons Learned
In highly transactional, high-consequence environments, waiting for manual user complaints to identify data errors introduces significant operational and reputational risk; automated boundary monitoring is essential.
Healthcare
Data Challenge
A health insurance provider relies on complex analytics pipelines to track patient claims, update clinical metrics, and generate regulatory compliance reports. Subtle variations in diagnostic code formats frequently caused downstream aggregation models to drop key records, creating compliance risks.
Observability Approach
The team implemented a developer-centric data quality and observability framework, embedding automated validation checks directly into their dbt transformation pipelines and CI/CD deployment routines.
Business Benefits
The data engineering team eliminated reporting compliance violations by automatically catching and isolating misformatted diagnostic data records before they reached production warehouses.
Lessons Learned
Maintaining data quality in regulated industries requires a proactive approach that catches and addresses format mutations early in the transformation process.
E-Commerce
Data Challenge
A fast-growing retail platform manages an inventory framework with thousands of product categories. Upstream inventory updates regularly introduced data anomalies, such as negative stock values or zeroed price fields, which led to incorrect pricing on the consumer website.
Observability Approach
The team implemented an automated anomaly detection platform that uses machine learning to monitor data distributions, tracking value variations across inventory metrics in real time.
Business Benefits
The system prevented pricing incidents by automatically flagging and pausing suspicious updates, protecting profit margins and maintaining a reliable customer checkout experience.
Lessons Learned
Automated distribution monitoring is critical for protecting e-commerce operations from silent, disruptive pricing errors caused by broken upstream data.
Telecommunications
Data Challenge
A telecommunications provider manages massive streaming pipelines that ingest network performance data from millions of IoT routers. The data infrastructure team struggled to isolate whether network drops were caused by hardware failures or ingestion errors.
Observability Approach
The team integrated a pipeline-focused observability tool into their distributed Kafka and Spark computing environments to capture real-time execution metadata.
Business Benefits
The engineering team minimized system troubleshooting time by instantly correlating data volume drops with specific cluster infrastructure events, reducing overall operational downtime.
Lessons Learned
Managing high-volume streaming data requires tracking both infrastructure performance and data characteristics simultaneously to maintain system reliability.
SaaS Platforms
Data Challenge
A B2B SaaS platform provides embedded customer analytics dashboards directly within its software application. Subtle pipeline failures frequently caused client dashboards to display stale or blank metrics, leading to increased customer support tickets.
Observability Approach
The platform integrated automated observability tools to map data lineage from backend infrastructure directly to their customer-facing embedded dashboards.
Business Benefits
The engineering team substantially reduced customer support tickets by using proactive status notices to alert users to data delays before clients noticed issues themselves.
Lessons Learned
Proactive notification of data issues builds user trust and protects engineering teams from being overwhelmed by repetitive support tickets.
Manufacturing
Data Challenge
A global automotive manufacturer monitors supply chain data across multiple regional enterprise resource planning (ERP) platforms. Frequent unannounced modifications to inventory schemas regularly broke central logistics models, delaying factory production schedules.
Observability Approach
The data team deployed an open-standard metadata and governance platform to automate schema change tracking and map dependencies across all regional data assets.
Business Benefits
The factory floor avoided costly supply chain bottlenecks by providing logistics teams with immediate visibility into structural data modifications, allowing updates to be handled smoothly.
Lessons Learned
Managing data across decentralized business units requires an automated, centralized system to track schema updates and maintain operational stability.
In Simple Terms
Think of these real-world use cases like installing advanced security and diagnostic systems across different types of buildings. A bank needs vault sensors to protect transactions, a hospital requires life-support monitors to ensure safety, a retail store needs inventory tracking to manage stock, and a factory requires automated assembly line monitoring to keep production running smoothly.
Real-World Example
An international ride-sharing platform tracks driver payment metrics. They combine multiple industry approaches: using automated monitoring to audit financial transactions, validating data formats to meet transit regulations, tracking fare distributions to prevent pricing errors, monitoring real-time streaming pipelines, and using automated data lineage to map backend metrics directly to driver app dashboards.
Common Mistake
A common mistake organizations make during adoption is trying to implement comprehensive observability across all company datasets simultaneously. This overly broad approach often overwhelms teams with alerts and dilutes focus, rather than prioritizing the critical data pipelines that directly drive business operations.
Key Takeaways
- Observability solves specific industry problems: Tailoring your tool configuration to address your primary operational risks ensures maximum value.
- Proactive detection protects user trust: Identifying errors before they reach end users preserves system credibility across all industries.
- Incremental rollout yields better results: Focusing implementation on your highest-value data assets allows teams to build momentum and refine operational workflows.
Benefits of DataOps Observability Tools
Improved Data Reliability
Implementing purpose-built observability tools establishes a reliable operational environment for your data infrastructure. By continuously validating data quality, monitoring ingestion timelines, and tracking schema updates, these platforms ensure that the data flowing through your enterprise remains accurate, complete, and trustworthy, turning data into a dependable corporate asset.
Faster Incident Resolution
When a pipeline failure occurs, observability tools eliminate the need for manual, time-consuming troubleshooting. By providing clear data lineage maps, detailed metadata histories, and automated root cause analysis, these systems show engineers exactly where and why an issue occurred, drastically reducing the time needed to fix errors and restore normal operations.
[Incident Triggered]
│
├─► Legacy Manual Search: Query logs, check code, call teammates ──► Avg: 14 Hours
│
└─► Observability Platform: Unified Root Cause Diagnosis Map ──► Avg: 11 Minutes
Reduced Downtime
Data pipeline downtime can disrupt business operations and cause significant financial losses. Observability platforms mitigate this risk by using predictive anomaly detection to catch issues early in the pipeline, allowing teams to resolve processing glitches and data mutations before they can cascade downstream and knock critical business intelligence systems offline.
Better Decision-Making
When business executives, operational managers, and data analysts can trust that their dashboards are accurate and up to date, corporate decision-making improves. Reliable data enables organizations to optimize inventory levels, target marketing campaigns effectively, and manage financial risk with confidence, eliminating the guesswork caused by untrustworthy metrics.
Operational Efficiency
Data observability tools improve engineering efficiency by automating routine data validation and quality control tasks. This automation frees highly skilled data engineers from spending their days troubleshooting broken code and manually cleaning data, allowing them to focus on building scalable architecture, designing features, and delivering high-value data products.
Compliance Support
In an increasingly strict regulatory environment governed by frameworks like GDPR, CCPA, and HIPAA, maintaining clear visibility into your data operations is an operational necessity. Observability platforms help meet these requirements by automatically documenting data lineage, tracking structural changes, and logging data access histories, providing a reliable audit trail for compliance verification.
In Simple Terms
Think of these benefits like upgrading a city’s manual security patrol with an integrated, automated smart-grid system. The city benefits from instant incident detection, faster emergency response times, reduced crime rates, lower operational costs, and comprehensive documentation for public safety analysis.
Real-World Example
A digital media company with over 50 million active users integrated an automated data observability platform into its operations. Over a twelve-month period, the platform helped the data engineering team reduce production data incidents by 85%, cut average incident resolution time from twelve hours to less than fifteen minutes, saved over $120,000 in unnecessary cloud warehouse compute fees, and provided verified data lineage records that simplified their annual security and privacy compliance audits.
Common Mistake
A frequent corporate error is evaluating the return on investment (ROI) of an observability tool solely by counting the number of alerts it generates. The real business value lies in the reduction of engineering time spent firefighting, the prevention of costly operational errors, and the preservation of business trust in company data.
Key Takeaways
- Observability enhances engineering velocity: Automating data validation allows engineering teams to focus on building new platform capabilities.
- Proactive monitoring lowers operational costs: Catching data anomalies early prevents expensive downstream data cleanups and warehouse rollbacks.
- Comprehensive lineage simplifies compliance audits: Automated dependency mapping provides a clear, reliable record of how data is managed and moved.
Common Challenges in Implementing Observability
Data Silos
Large enterprises often store data across fragmented infrastructure, including disconnected cloud platforms, legacy on-premise databases, and third-party SaaS applications. This structural fragmentation makes implementing end-to-end observability challenging, as data teams must establish secure metadata connections across disparate systems that lack standardized logging formats.
The Solution
Data teams should prioritize the adoption of observability tools that rely on open metadata standards and offer broad, native API integration with a wide variety of data technologies, helping to unify tracking across different platforms.
Tool Sprawl
The rapid growth of the modern data stack has led to an explosion of specialized tools for ingestion, transformation, storage, and analysis. Managing observability telemetry across an disconnected mix of tools can overwhelm engineering teams, leading to fragmented visibility where distinct teams use different monitoring dashboards.
The Solution
Establish a centralized, platform-wide observability strategy managed by a dedicated data infrastructure or DataOps team, ensuring that all data assets are monitored through a single, unified interface.
Metadata Gaps
Observability tools rely entirely on rich metadata to analyze system health and map dependencies. If an upstream data source, custom pipeline script, or legacy database does not generate or expose structural logs, the observability platform cannot monitor those assets effectively, creating visibility blind spots.
The Solution
Enforce strict development guidelines that require all custom pipeline code and data ingestion tasks to output structured execution logs and metadata to centralized repositories.
Alert Fatigue
When an observability tool is configured with overly sensitive anomaly thresholds or lacks clear alerting rules, it can bombard engineering teams with a constant stream of minor notifications. This high alert volume causes alert fatigue, leading engineers to ignore notifications and inevitably miss critical, high-priority system failures.
[Overly Sensitive Thresholds] ──► [Constant Low-Priority Alerts] ──► [Alert Fatigue] ──► [Engineers Mute Notifications] ──► ⚠️ [Critical Failure Missed]
The Solution
Implement dynamic, machine learning-driven anomaly detection thresholds and set up precise routing rules to ensure that high-priority alerts are sent only to the specific team responsible for the affected asset.
Scaling Challenges
As corporate data platforms scale to manage petabytes of information across thousands of tables, the volume of operational metadata grows rapidly. Observability systems must be architected to ingest, process, and analyze this massive stream of telemetry without introducing performance bottlenecks or increasing warehouse compute costs.
The Solution
Configure your observability platform to focus deep statistical profiling on high-priority, business-critical datasets while using lightweight metadata monitoring for lower-value, secondary tables.
Adoption Resistance
Introducing a new observability platform requires data engineers, analytics professionals, and business analysts to change their established workflows. Teams may resist adopting the new tool if they view it as an unnecessary administrative burden that adds complexity to their daily development tasks.
The Solution
Demonstrate the practical value of the tool early by showing how it automates manual troubleshooting tasks and saves engineering time during data incidents, while providing comprehensive training to ease the transition.
In Simple Terms
Imagine trying to install a modern security system across a historic university campus. You will face physical challenges like disconnected buildings built in different eras (Silos), a confusing mix of legacy locks and modern keypads (Tool Sprawl), unmapped utility tunnels (Metadata Gaps), and security guards who prefer using their old master keys (Adoption Resistance).
Real-World Example
An international logistics provider implementing data observability faced significant internal hurdles. Their legacy data warehouses generated incomplete metadata logs, which triggered frequent false alarms and caused alert fatigue across the engineering team.
The data platform lead resolved these challenges by pausing the rollout to rebuild their logging standards, configuring the system to route alerts directly to specific data owners via Slack, and conducting practical workshops that demonstrated how the platform could resolve complex data incidents in minutes.
Common Mistake
A common implementation pitfall is deploying an observability tool without first updating and standardizing your team’s internal logging and metadata processes, which often leads to inaccurate anomaly tracking and high alert noise.
Key Takeaways
- Centralized strategies prevent tool sprawl: Monitoring all data assets through a single, unified observability interface ensures consistent visibility.
- Smart alert routing eliminates fatigue: Ensuring alerts are context-rich and sent only to asset owners keeps incident response efficient.
- Standardized logging powers accurate tracking: Enforcing clear metadata guidelines across all pipeline code is essential for reliable observability.
Common Mistakes Organizations Make
Treating Observability as Basic Monitoring
Many technology teams assume that setting up standard infrastructure alerts for server availability and successful script execution completes their visibility requirements. This approach leaves organizations completely blind to silent data corruption, where empty tables or corrupted values pass through healthy infrastructure without throwing errors.
Prevention Strategy
Educate engineering leadership on the distinction between system infrastructure monitoring and data content observability, ensuring that metrics like freshness, data volume variations, and statistical distributions are monitored independently of server status.
Ignoring Data Lineage
Deploying a data quality tracking system without mapping end-to-end data lineage makes alerts difficult to act on. When an anomaly is detected in a table, engineers are forced to spend hours manually tracing upstream dependencies to locate the root cause and checking downstream reports to see what broke.
Prevention Strategy
Prioritize the adoption of observability platforms that feature automated SQL parsing to build and maintain real-time data lineage maps across your entire data stack.
[Anomalous Table Alert]
│
├─► (Without Lineage): Manual code searches across GitHub/Airflow ──► Time Lost: Hours
│
└─► (With Lineage): Automated SQL Dependency Tree Parsing ──► Time Lost: Seconds
Focusing Only on Alerts
Some data teams configure their observability platforms to function purely as emergency notification engines, ignoring the deep metadata histories, system usage trends, and query performance logs that these tools collect over time.
Prevention Strategy
Use your observability platform’s historical reports during weekly planning and architecture reviews to optimize cloud compute spend, clean up unused tables, and improve overall pipeline performance.
Lack of Ownership
When a data observability platform flags an anomaly on a shared dataset that lacks a clear owner, the alert often goes unaddressed. Without defined ownership, team members assume someone else is handling the issue, leaving critical data errors unresolved.
Prevention Strategy
Maintain a comprehensive data catalog that assigns clear team ownership to every production table, view, and pipeline workflow, and configure your alerting system to route notifications accordingly.
Incomplete Data Quality Rules
Relying entirely on automated machine learning models to catch anomalies while failing to define explicit, code-based rules for critical business constraints can leave an infrastructure vulnerable to subtle logical errors that look statistically normal.
Prevention Strategy
Implement a balanced validation strategy that combines automated anomaly tracking for structural and freshness metrics with explicit, rule-based tests for core business logic and regulatory requirements.
In Simple Terms
Imagine building a high-tech hospital but only installing monitors that check if patients have a pulse, while failing to track blood pressure or oxygen levels (Basic Monitoring), forgetting to label which doctor is responsible for which ward (Lack of Ownership), and ignoring the medical history charts during daily rounds (Focusing Only on Alerts).
Real-World Example
An international travel booking platform invested heavily in a premium data observability platform but connected it without assigning clear owners to their data assets or configuring precise alert routing. Within two weeks, the system generated thousands of automated slack notifications to a general engineering channel.
Because the alerts lacked context and ownership, engineers ignored the notifications, leading the team to miss a major schema mutation that corrupted their primary booking attribution ledger for several days.
Common Mistake
A frequent organizational mistake is deploying an observability platform and expecting it to instantly fix your data issues without dedicating engineering time to refine its settings, establish operational workflows, and integrate it into daily team routines.
Key Takeaways
- Infrastructure health does not guarantee data health: Monitoring system availability alone leaves you vulnerable to silent data corruption.
- Clear ownership makes alerts actionable: Assigning data assets to specific teams ensures that quality incidents are resolved quickly.
- Combine automation with explicit rules: Blending machine learning anomaly detection with targeted business validation provides the most reliable coverage.
Best Practices for DataOps Observability
To build a resilient, scalable, and highly effective data observability program, engineering teams should implement the following core practices.
Define Reliability Goals
Before configuring alerts across your environment, establish clear data reliability goals and Service Level Objectives (SLOs) for your critical data assets. Work directly with business stakeholders to define acceptable thresholds for data freshness, completeness, and accuracy based on actual operational needs. For example, determine whether a specific dashboard requires data that is refreshed every fifteen minutes, or if a daily update is sufficient for business operations.
Monitor Critical Data Assets
Avoid the temptation to apply intensive data quality checks to every table in your database catalog simultaneously. Instead, map your data environment and focus your deepest observability efforts on high-value, critical data assets—such as customer transaction logs, regulated compliance tables, and primary executive dashboards—ensuring maximum protection for the systems that drive business decisions.
[Entire Data Catalog: 5,000+ Tables]
│
▼ (Identify High-Value Core Paths)
[Tier-1 Critical Assets: 150 Tables] ───► Apply Deep Observability & Custom Rules
Implement Data Lineage
Ensure your observability platform is configured to automatically track and map data lineage across your entire processing lifecycle, from raw ingestion sources to end-user BI tools. Maintaining an accurate, real-time dependency map allows engineers to quickly trace the root cause of upstream failures and proactively manage the downstream impact of structural changes.
Automate Quality Checks
Integrate data quality testing directly into your continuous integration and continuous deployment (CI/CD) pipelines and orchestration routines. By automating validation checks using frameworks like dbt or Soda, you can test data transformations in staging environments and catch breaking errors before they reach production databases.
Create Incident Response Processes
An alert is only useful if your team knows how to respond to it. Establish a clear, documented data incident response workflow that defines who owns an alert, how to log and track the issue, and how to notify downstream business stakeholders. Integrating these alerts into standard team tools like Slack, Jira, or PagerDuty ensures that incidents are handled efficiently and transparently.
[Observability Alert] ──► [Slack/PagerDuty Routing] ──► [Triage & Tiers] ──► [Lineage Blast Notice] ──► [Fix & Log]
Continuously Improve Visibility
Treat your data observability setup as an evolving architecture that requires regular refinement. Review your incident history, alert sensitivity, and data quality rules during team retrospectives, adjusting thresholds and coverage patterns to adapt to changing data volumes, new business requirements, and evolving platform structures.
In Simple Terms
Think of these best practices like running a professional fire department. You don’t just buy fire trucks and wait for emergencies. You map out the city’s high-risk areas, install fire hydrants at key intersections, establish automated alarm systems, train firefighters on standard response procedures, and regularly review safety drills to improve response times.
Real-World Example
An enterprise financial platform structured its observability strategy around these best practices: they established clear data freshness goals with their risk management team, prioritized deep monitoring for their core ledger tables, automated regression testing within their GitLab deployment workflows, and set up clear incident response guidelines that cut their average time to resolve data issues from several hours to under twelve minutes.
Common Mistake
A frequent operational error is configuring data alerts to send notifications to generic, unmonitored team email inboxes. This lack of visible routing quickly leads to missed alerts and delayed response times, leaving critical data failures unaddressed.
Key Takeaways
- Align monitoring with business needs: Setting clear data goals ensures your observability strategy supports actual operational requirements.
- Focus on high-value data assets: Prioritizing your critical pipelines provides maximum protection while minimizing configuration noise.
- Establish clear response workflows: Documenting incident response procedures ensures that automated alerts lead to fast, organized remediation.
Skills Needed for DataOps Observability
Building and managing a modern data observability architecture requires a balanced mix of software engineering discipline, data analysis expertise, and cloud infrastructure knowledge.
┌────────────────────────────────────────────────────────────────────────┐
│ DATAOPS OBSERVABILITY SKILL TREE │
├───────────────────────────┬───────────────────────────┬────────────────┤
│ DATA ENGINEERING │ SQL & ANALYTICS │ PLATFORM METRICS│
│ • Pipelines & Streaming │ • Deep Analytical Queries│ • System Logs │
│ • CI/CD & Orchestration │ • Statistical Profiling │ • Cloud Costs │
└───────────────────────────┴───────────────────────────┴────────────────┘
Data Engineering Fundamentals
Data reliability professionals must possess a deep understanding of core data engineering principles, including pipeline design, batch and streaming integration architectures, and cloud storage optimization. Familiarity with development tools like Git and automated orchestration frameworks like Apache Airflow is essential for embedding observability metrics directly into data workflows.
SQL and Analytics
Advanced SQL proficiency is a foundational requirement for data troubleshooting. Engineers must be capable of writing efficient, complex analytical queries to parse system metadata, profile large datasets, and isolate anomalous records within massive database tables without impacting production warehouse performance.
Monitoring Concepts
Professionals need a solid understanding of software monitoring practices, including how to collect and analyze logs, metrics, and traces. Mastering these observability concepts allows engineers to configure intelligent alerting thresholds, manage alert routing systems, and design comprehensive monitoring dashboards that balance detailed technical data with clear business context.
Data Quality Management
Understanding how to design and implement data quality frameworks is essential. Engineers should be skilled in using testing tools like Great Expectations or Soda, writing declarative validation rules, and applying statistical models to identify data drift and anomaly patterns across complex datasets.
Metadata Management
Data architects must understand how to collect, store, and utilize metadata across the enterprise data stack. This includes mastering database catalog architectures, understanding open metadata standards, and leveraging automated lineage engines to build clear maps of data movement and dependencies.
Cloud Data Platforms
Deep technical knowledge of modern cloud data platforms—such as Snowflake, Databricks, or Google BigQuery—is critical. Engineers must understand how these platforms process queries, manage storage catalogs, and generate system logs to optimize both data observability tracking and cloud infrastructure costs.
In Simple Terms
Think of this skill set like the training required to be a modern diagnostic mechanic for high-performance electric vehicles. You can’t just rely on an old wrench; you need to understand advanced electrical engineering, know how to interpret computerized diagnostic codes, possess deep mechanical experience, and understand how to safely optimize the vehicle’s onboard software systems.
Real-World Example
A senior analytics engineer at an insurance technology company leverages this diverse skill set daily: they write Python scripts to orchestrate data pipelines in Airflow, write advanced SQL queries to profile claims data inside Snowflake, use declarative frameworks to automate quality checks, and analyze metadata logs to maintain accurate end-to-end data lineage maps for compliance audits.
Common Mistake
Many aspiring data professionals focus exclusively on learning how to use specific vendor software interfaces while neglecting the underlying foundational concepts of database indexing, SQL optimization, and structured metadata management.
Key Takeaways
- Master the architectural foundations: True data reliability engineering relies on a deep understanding of core pipeline, storage, and processing mechanics.
- SQL remains essential: The ability to write efficient queries is critical for analyzing metadata and troubleshooting complex data failures.
- Unify data and software practices: Combining traditional IT monitoring concepts with data quality management is key to scaling modern DataOps infrastructure.
Future of DataOps Observability
AI-Powered Observability
The integration of advanced artificial intelligence and machine learning models is transforming how data platforms monitor system health. Future observability engines will move beyond simple single-variable threshold alerts, using unsupervised deep learning algorithms to analyze complex data patterns across multiple systems simultaneously, identifying subtle system anomalies that are impossible to capture with manual rules.
Predictive Data Quality Monitoring
Rather than simply alerting teams after a data failure has occurred, future observability solutions will adopt a predictive posture. By analyzing upstream application updates, historical processing timelines, and cloud infrastructure variations, these systems will forecast potential pipeline bottlenecks and data quality risks, allowing engineers to address issues before they cause downstream failures.
[Upstream App Release Context]
│
▼ (Predictive Machine Learning Simulation Layer)
[Forecasted Ingest Bottleneck Risk: 92%] ───► [Proactive Warehouse Scale-Up Trigger]
Automated Incident Resolution
The next stage of DataOps maturity will see the rise of self-healing data architectures. When an observability tool detects a routine data incident—such as an unannounced schema change or a partial data load—it will automatically trigger remediation workflows, routing bad data to isolation queues, adjusting transformation scripts, and reprocessing files without requiring manual engineering intervention.
Intelligent Data Lineage
Data lineage systems will evolve to provide deeper, interactive visibility into data movement. Future lineage tools will not only map dependencies between tables, but will also track data mutations at the individual cell and value level, automatically generating natural-language documentation that explains how business metrics are altered as they move through the enterprise.
Autonomous Data Operations
In the long term, data observability will serve as the core intelligence framework for fully autonomous data platforms. These systems will continuously monitor data quality, track pipeline performance, optimize warehouse storage, and rewrite inefficient transformation code automatically, allowing data platforms to scale and adapt to changing business needs with minimal manual upkeep.
In Simple Terms
Think of this evolution like moving from a traditional vehicle with a manual dashboard to a fully autonomous self-driving car. The vehicle doesn’t just warn you that a tire is losing air; it predicts the pressure drop based on road conditions, adjusts the suspension automatically to keep you safe, reroutes your trip around upcoming traffic, and schedules its own maintenance appointment.
Real-World Example
A global financial technology enterprise is piloting an autonomous self-healing data platform. When an upstream payment processor changes its decimal formatting structure, the platform’s AI engine detects the anomaly, creates a temporary staging view to parse the new format, notifies the engineering team via an automated summary report, and reprocesses the morning transaction records without interrupting business dashboards.
Common Mistake
A common mistake made by technology leaders is delaying investments in foundational data organization and metadata hygiene while waiting for future AI tools to solve their data quality issues automatically. AI engines require clean, structured metadata baselines to operate effectively.
Key Takeaways
- Observability is shifting from reactive to predictive: Future tools will focus on forecasting risks and preventing incidents before they impact production.
- Self-healing architectures reduce engineering load: Automating routine incident remediation allows data teams to focus on high-value development.
- Clean metadata is the foundation for AI: Building a structured, accessible metadata repository today is essential for leveraging future autonomous technologies.
Case Study Section
1. Banking Data Reliability Transformation
[Legacy Infrastructure Stack] ───► High Alert Noise & Late Detection (Avg. 44 Hours)
│
▼ (Implemented Monte Carlo + Target SLOs)
[Modernized Banking Platform] ───► Automated Anomaly Detection & Routing (MTTR < 15 Min)
Problem
A regional retail bank processing over 5 million daily transaction events faced significant pipeline reliability challenges. Upstream software updates regularly introduced malformed data into customer ledger models, causing data freshness delays and leading to balance discrepancies on user dashboards that took days to locate and fix.
Observability Strategy
The bank established a dedicated DataOps reliability initiative, implementing an automated anomaly detection platform to track data freshness, volume variations, and schema mutations across all primary financial tables. They defined strict data reliability goals and integrated alerts directly into their automated on-call routing workflows.
Tools Used
Monte Carlo, Snowflake, Apache Airflow, PagerDuty.
Results
- Reduced the average time to detect data anomalies from 44 hours to under 12 minutes.
- Eliminated silent data corruption across core transaction ledgers.
- Restored business confidence in daily financial analytics reporting.
Lessons Learned
Automating data validation and establishing clear team ownership for critical assets is essential for protecting system integrity in highly regulated, high-stakes financial environments.
2. Healthcare Reporting Accuracy Initiative
Problem
A national medical analytics provider tracks patient health metrics across a network of clinics to generate regulatory compliance reports. Frequent, undocumented formatting updates to diagnostic codes broke downstream aggregation models, causing partial data losses that compromised compliance reporting.
Observability Strategy
The data team implemented a developer-centric data quality testing framework, writing explicit validation rules for diagnostic codes and embedding automated tests directly into their continuous integration (CI/CD) and staging deployment pipelines.
Tools Used
Soda, dbt Core, Google BigQuery, GitHub Actions.
Results
- Caught and isolated 100% of formatting anomalies during the staging phase before they could reach production databases.
- Reduced time spent by engineers troubleshooting data errors by 70%.
- Maintained complete accuracy for regulatory compliance reporting.
Lessons Learned
Catching formatting mutations early in the development lifecycle via automated testing is the most effective way to manage compliance risks in complex data environments.
3. E-Commerce Analytics Quality Improvement
Problem
A global retail platform ingests product availability and pricing data from thousands of third-party vendors. Upstream processing errors regularly introduced data anomalies, such as negative pricing figures or zeroed stock levels, which corrupted business dashboards and led to checkout pricing errors.
Observability Strategy
The data platform team deployed an automated observability platform that leverages machine learning to monitor value distributions, tracking statistical averages, variance, and null rates across all incoming inventory fields.
Tools Used
Anomalo, AWS Redshift, AWS Step Functions, Slack.
Results
- Automated data validation across over 12,000 active product tables with minimal manual configuration.
- Instantly flagged and paused anomalous pricing updates, preventing retail pricing errors.
- Saved the engineering team over 25 hours per week previously spent on manual data cleanup.
Lessons Learned
Automated distribution monitoring using machine learning is critical for detecting subtle, costly value anomalies that slip past standard rule-based tests.
4. SaaS Platform Data Trust Program
Problem
A software-as-a-service enterprise provides embedded analytics dashboards to its corporate clients. Subtle backend pipeline failures frequently caused user dashboards to display stale or blank data, resulting in increased customer support tickets and eroding user trust in the platform.
Observability Strategy
The engineering team integrated comprehensive data lineage tracking to map backend database tables directly to individual customer dashboard components. They set up proactive alerts and created automated data status pages to keep users informed of processing delays.
Tools Used
Metaplane, Snowflake, dbt Cloud, Looker, Microsoft Teams.
Results
- Reduced data-related customer support tickets by 80% through proactive communication.
- Provided engineers with instant root cause analysis maps, reducing average repair times to under 15 minutes.
- Improved client retention by building a transparent, dependable reporting environment.
Lessons Learned
Proactive notification of data issues based on clear lineage mapping builds customer trust and protects support teams from being overwhelmed by repetitive tickets.
5. Manufacturing Data Governance Project
Problem
A global automotive manufacturer manages supply chain logistics across multiple regional ERP environments. Unannounced mutations to inventory database schemas regularly broke central logistics models, causing planning errors that threatened to disrupt factory floor production schedules.
Observability Strategy
The manufacturer implemented an open-standard metadata and governance architecture to automate schema tracking, document asset ownership, and map end-to-end data dependencies across all regional production systems.
Tools Used
OpenMetadata, Apache Kafka, Databricks, Jira.
Results
- Centralized data asset tracking and lineage mapping across seven regional operational frameworks.
- Automated schema change notifications, giving data engineers early warning to update models.
- Prevented supply chain and production delays by ensuring logistics dashboards remained accurate and online.
Lessons Learned
Managing data across decentralized business units requires an automated, centralized metadata management platform to maintain operational stability and structural consistency.
Data Observability Maturity Model
To help organizations assess their current capabilities and plan their technical development, this framework outlines the five stages of Data Observability Maturity.
[Level 1: Reactive] ──► [Level 2: Structured] ──► [Level 3: Automated] ──► [Level 4: Predictive] ──► [Level 5: Autonomous]
• Blind to Errors • Basic Static Rules • Machine Learning • Risk Forecasting • Self-Healing
• Stakeholder Alerts • Manual Pipeline QA • Context Alerts • Cross-System Profiling• Auto-Remediation
Level 1 – Reactive Monitoring
Description
The organization has no dedicated visibility into data quality or pipeline performance. Data issues are discovered only after they break downstream reports, typically flagged by business stakeholders or executive users.
Assessment Criteria
- Data pipelines lack automated quality validation testing or monitoring checks.
- The data engineering team spends a significant portion of their week firefighting data incidents.
- There is no clear understanding of end-to-end data lineage or asset dependencies across systems.
Level 2 – Structured Visibility
Description
The team implements basic, code-based data validation testing within their transformation pipelines, focusing on catching known errors at specific points in the processing flow.
Assessment Criteria
- Static assertions and basic checks (e.g., verifying fields are not null, checking unique keys) are written into dbt models or orchestration steps.
- The team receives automated notifications when a pipeline task fails or a validation test triggers an error.
- Data architecture documentation and lineage maps are maintained manually, meaning they are often outdated.
Level 3 – Automated Quality Monitoring
Description
The organization adopts dedicated data observability tools, leveraging machine learning to automatically track baseline performance and detect anomalies across their central data environment.
Assessment Criteria
- The platform automatically monitors metrics like data freshness, volume variations, and schema mutations without manual configuration.
- Alerts are enriched with system context and routed directly to specific data engineering teams via collaboration platforms like Slack.
- Data lineage is parsed and mapped automatically from SQL history logs, providing a live view of table-level dependencies.
Level 4 – Predictive Observability
Description
The data platform monitors multi-variant statistical distributions and tracks cross-system dependencies to forecast pipeline risks and catch complex data drift before it impacts production systems.
Assessment Criteria
- Continuous statistical profiling tracks data drift and behavioral shifts across critical data assets.
- Observability extends across the entire pipeline, mapping data health from raw ingestion boundaries down to individual BI dashboard elements.
- Reliability goals (SLOs) are systematically tracked and used to prioritize data infrastructure investments and engineering work.
Level 5 – Autonomous Data Reliability
Description
The organization operates a highly resilient, self-healing data platform where automated observability tools predict, isolate, and remediate routine data quality incidents without requiring manual engineering intervention.
Assessment Criteria
- Automated workflows isolate anomalous records and trigger self-healing re-execution routines to resolve data errors instantly.
- The observability framework automatically scales compute resources, rewrites inefficient queries, and updates data assets.
- Data infrastructure operates with high reliability, allowing engineers to focus entirely on building new platform capabilities and data products.
FAQ Section
1.What is DataOps observability?
DataOps observability is the continuous practice of monitoring, tracking, and analyzing the health, state, and performance of data pipelines. By capturing metadata from across ingestion, storage, and transformation layers, it allows teams to detect and resolve issues like schema changes, freshness delays, and data quality anomalies before they impact business decisions.
2. How does data observability differ from traditional infrastructure monitoring?
Traditional monitoring tracks system metrics like server uptime, CPU utilization, and memory usage to ensure hardware is functional. Data observability focuses on the integrity of the data payload itself, monitoring for errors like missing fields, corrupted values, or data drift that pass through healthy infrastructure without throwing system errors.
3. What are the five pillars of data observability?
The five pillars of data observability are Freshness (is the data up to date?), Volume (did all expected records arrive?), Schema (has the data structure or organization mutated?), Distribution (are the specific field values statistically normal?), and Lineage (where did the data originate and where does it flow?).
4. Why is automated data lineage important?
Automated data lineage maps the end-to-end journey of data through your pipelines, showing how different assets depend on one another. When a data error occurs, lineage allows engineers to quickly trace upstream to find the root cause and look downstream to see exactly which business reports and dashboards are affected.
5. Which observability tools are most popular?
Popular commercial platforms include Monte Carlo, Bigeye, Anomalo, and Metaplane, which offer automated, machine learning-driven anomaly detection. For teams seeking open-source or developer-centric options, frameworks like Great Expectations, Soda, and OpenMetadata provide highly customizable, code-driven validation testing.
6. How does observability improve data quality?
Observability improves quality by moving from passive, periodic manual checks to continuous, automated validation. By analyzing value distributions, identifying format mutations, and flagging structural changes in real time, it allows teams to catch and address data issues before they corrupt downstream systems.
7. Can small data teams implement observability?
Yes. Fast-deploying, commercial observability platforms can connect to modern cloud data stacks via APIs in less than thirty minutes, providing automated anomaly detection with minimal setup overhead and allowing small teams to manage complex infrastructure efficiently without hiring dedicated reliability architects.
8. What technical skills are required to manage data observability?
Engineers need a solid foundation in data engineering principles, advanced SQL proficiency for data profiling and analysis, a clear understanding of monitoring concepts (such as logs, metrics, and traces), and familiarity with cloud data platforms like Snowflake, BigQuery, or Databricks.
9. How much do data observability tools cost?
Costs vary widely based on the deployment model. Open-source frameworks are free to use but require internal engineering time to host, manage, and scale. Commercial SaaS platforms use pricing models based on data volume, table counts, or warehouse compute activity, ranging from accessible mid-market tiers to premium enterprise contracts.
10. What is the future of data observability?
The discipline is moving toward autonomous, self-healing data architectures. Future observability tools will use advanced AI models to predict pipeline failures, automate data drift analysis, and trigger self-repair workflows that isolate corrupted data and fix routine errors without requiring human intervention.
11. What is a silent data failure?
A silent data failure occurs when a data pipeline executes successfully without throwing system infrastructure errors, but the data payload itself becomes corrupted, incomplete, or structurally altered, leading to inaccurate downstream business reporting.
12. How does alert fatigue happen in data operations?
Alert fatigue occurs when an observability system is configured with overly sensitive anomaly thresholds or lacks clear routing rules, bombarding engineers with a constant stream of low-priority notifications that cause teams to ignore alerts and miss critical failures.
13. How do you prevent alert fatigue?
Teams can minimize notification noise by using dynamic, machine learning-driven thresholds that adapt to historical trends, filtering out minor variations, and setting up precise routing rules to ensure alerts are sent only to the specific team that owns the affected asset.
14. What is data drift?
Data drift describes a gradual, unexpected shift in the statistical properties and distribution of values within a dataset over time, which can corrupt analytics insights and degrade the performance of predictive machine learning models even if the pipeline structure remains intact.
15. How does observability optimize cloud warehouse costs?
Observability platforms analyze query logs, table access records, and compute resource utilization to identify inefficient SQL code, locate abandoned or duplicate tables, and highlight wasteful processing jobs, helping teams optimize cloud data infrastructure spend.
16. What is the modern data stack (MDS)?
The modern data stack is a cloud-native ecosystem of specialized data tools built around a central cloud data warehouse, utilizing modular services for data ingestion (e.g., Fivetran), transformation modeling (e.g., dbt), orchestration (e.g., Airflow), and business intelligence (e.g., Looker).
17. How does data observability support regulatory compliance?
Observability platforms automatically document end-to-end data lineage, track structural modifications, and maintain detailed data access logs, providing a transparent, reliable audit trail that helps organizations verify compliance with data privacy frameworks like GDPR, CCPA, and HIPAA.
18. What is a Data Service Level Agreement (SLA)?
A Data SLA is a formal commitment between a data engineering team and business stakeholders that defines measurable targets for data platform performance, establishing clear, agreed-upon standards for data freshness, availability, and quality.
19. Should we build our own observability tools or buy a platform?
Building a custom internal tool provides total control over architecture but requires significant, ongoing engineering time to maintain and scale. Buying a commercial platform offers automated features and immediate time-to-value out of the box, letting your team focus on core data development instead of building monitoring systems.
20. How do you introduce observability to a team resistant to change?
Demonstrate the practical value of the tool early by showing how it automates routine troubleshooting tasks and saves engineers time during data incidents, and provide structured training and clear implementation guidelines to ensure a smooth transition.
Final Summary
Embracing DataOps observability marks a significant shift in how organizations manage data infrastructure, moving from a reactive firefighting posture to a proactive, reliable, and engineering-driven methodology. As modern data stacks grow more complex, relying on basic infrastructure monitoring leaves systems vulnerable to silent data corruption, breaking schema mutations, and data drift.
By structuring an operational strategy around the Five Pillars of Data Observability—Freshness, Volume, Schema, Distribution, and Lineage—organizations can establish deep visibility into their data lifecycles, ensuring that the information driving business decisions remains accurate, complete, and fully trustworthy.