Are you curious about how DataOps work? In this blog post, we will delve into the intricacies of DataOps and how it can help businesses make data-driven decisions.
What is DataOps?
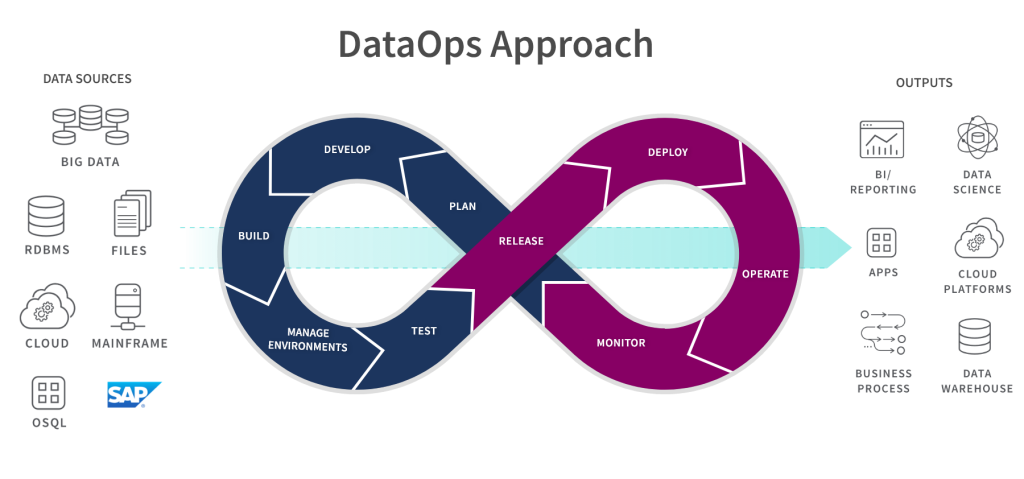
DataOps is a relatively new term that refers to the methodology, culture, and practices used by data teams to streamline the flow of data from source to analysis. It aims to bridge the gap between data science and operations, enabling teams to work collaboratively and efficiently.
The Benefits of DataOps
DataOps offers several benefits, including:
- Faster time to market: With DataOps, teams can deliver insights and analysis faster, enabling businesses to make data-driven decisions quickly.
- Improved collaboration: DataOps encourages collaboration between different teams, including data scientists, engineers, and operations.
- Better quality data: By automating data pipelines and using advanced analytics, DataOps ensures that data quality is maintained throughout the entire process.
- Cost savings: By automating data processes, businesses can save time and money, reducing the overall cost of data management.
How DataOps Works
DataOps involves a set of practices and tools that enable teams to work collaboratively and efficiently. Here are the key components of DataOps:
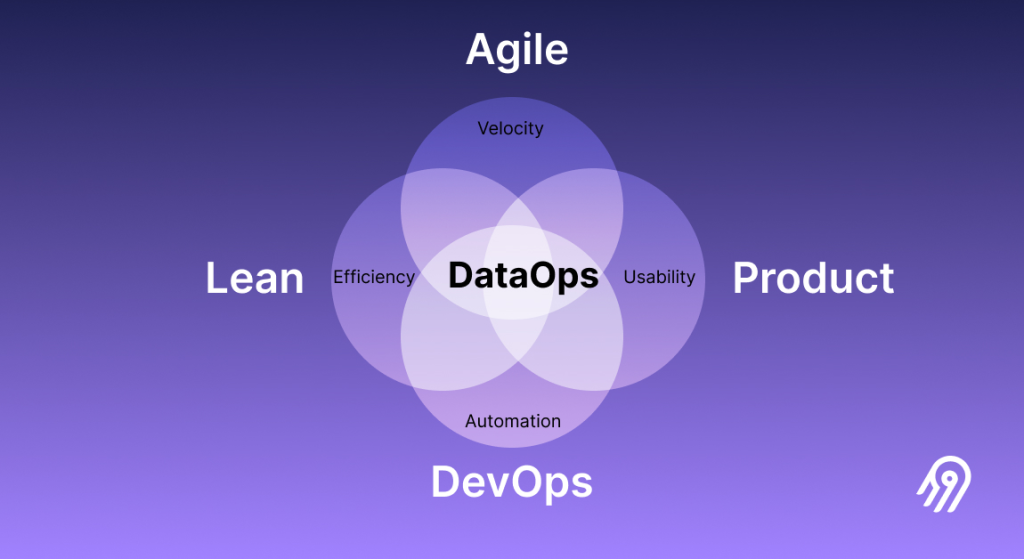
Agile and DevOps
DataOps borrows heavily from the Agile and DevOps methodologies, focusing on collaboration, automation, and continuous improvement. Agile and DevOps practices are used to streamline the flow of data from source to analysis, enabling teams to work collaboratively and efficiently.
Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration and Continuous Deployment (CI/CD) are critical components of DataOps. These practices involve automating the build, test, and deployment of data pipelines, enabling teams to deliver insights and analysis faster.
Data Pipelines
Data pipelines are the backbone of DataOps, enabling teams to move data from source to analysis quickly and efficiently. These pipelines use automation to ensure data quality and consistency, reducing the risk of errors and inconsistencies.
Cloud Computing
Cloud computing is a critical component of DataOps, providing the infrastructure and tools needed to store and process large amounts of data. Cloud computing enables teams to scale their data pipelines quickly, reducing the time and cost of data management.
Conclusion
In conclusion, DataOps is a methodology that aims to streamline the flow of data from source to analysis, enabling teams to work collaboratively and efficiently. By borrowing from Agile and DevOps practices and using tools like CI/CD, data pipelines, and cloud computing, businesses can make data-driven decisions quickly and efficiently.