Introduction
In a fast-paced digital economy, the shelf life of data value is shorter than ever. Businesses no longer have the luxury of waiting for overnight batch jobs to complete before making critical operational choices. Whether it is identifying fraudulent transactions, optimizing supply chain routes, or serving personalized product recommendations, modern enterprises require immediate clarity. This shift has triggered an unprecedented surge in demand for real-time decision-making. Traditional data architectures struggle heavily with this level of speed. Built on rigid, legacy extract-transform-load (ETL) structures, traditional pipelines are prone to frequent bottlenecks, silent failures, and high latency. When streaming data breaks downstream, debugging manually takes hours or days, completely defeating the purpose of live applications. Data teams find themselves constantly firefighting infrastructure failures rather than delivering valuable business logic. For deep-dive technical frameworks and educational curriculum on this operational paradigm, platforms like TheDataOps.org serve as vital industry foundations. By standardizing practices around pipeline automation, continuous testing, and infrastructure management, technology professionals can reliably build architectures that deliver trustworthy insights instantly.
Understanding Real-Time Data Analytics
Definition
Real-Time Data Analytics is the practice of continuously ingest, processing, and analyzing data as soon as it is generated by source systems to deliver immediate insights.
[Data Sources] ---> (Continuous Ingestion) ---> [Real-Time Processing Engine] ---> [Instant Insights]
Batch vs. Real-Time Analytics
Traditional batch processing collects data over a set period, aggregates it, and pushes it through pipelines in scheduled blocks. While cost-effective for deep historical reports, it introduces massive latency. Real-time analytics relies on continuous processing, executing computations on moving windows of data within milliseconds of generation.
| Capability | Batch Analytics | Real-Time Analytics |
| Data Latency | Hours, days, or weeks | Milliseconds to seconds |
| Ingestion Type | Scheduled blocks (e.g., nightly) | Continuous event streaming |
| Primary Use Case | Historical reporting, financial audits | Live anomaly detection, dynamic pricing |
| Infrastructure | Relational databases, static warehouses | Message brokers, stream processing engines |
The Corporate Imperative
Waiting for data means losing competitive advantages. Organizations leverage real-time insights to capture fleeting market opportunities, prevent operational vulnerabilities, and optimize user engagement. When an operational system responds instantly to live behavioral markers, conversion rates and customer satisfaction metrics increase significantly.
What Is DataOps?
Definition
DataOps (Data Operations) is an agile, lifecycle-oriented approach to data management that automates the design, deployment, and monitoring of data pipelines to improve quality and accelerate time-to-insight.
Core Principles and Origins
DataOps is not an isolated software tool; it is a cultural and operational methodology. It borrows foundational concepts from three distinct disciplines:
- DevOps: Utilizing continuous integration and continuous deployment (CI/CD) paths for data infrastructure code.
- Agile Methodology: Breaking data pipeline development down into short, iterative sprints to deploy features incrementally.
- Statistical Process Control (SPC): Continuously monitoring and testing pipeline inputs and outputs to ensure data consistency.
Data Pipeline Management as Code
In a DataOps ecosystem, everything is defined as code. Database schemas, transformation models, orchestration steps, and quality assertions are written in version-controlled repositories. This prevents configuration drift and allows engineers to test code adjustments in isolated staging environments before promoting them to production streams.
Why Real-Time Analytics Needs DataOps
High-velocity environments amplify minor pipeline flaws into massive operational failures. Without DataOps, real-time architectures quickly collapse under operational friction.
Velocity Challenges
When data enters systems at thousands of events per second, human data validation becomes physically impossible. Manual reviews fail immediately, meaning unvalidated schemas can quickly corrupt downstream analytical dashboards and machine learning models.
Strict Data Quality Commitments
Real-time does not mean cutting corners on data quality. An erroneous data point processed instantly can trigger automatic, incorrect operational choices—such as shutting down a healthy factory assembly line or blocking legitimate financial transactions. DataOps enforces automated checks directly inside the active data stream.
The Need for Continuous Infrastructure Monitoring
Streaming pipelines run 24/7. Infrastructure components require deep data observability to alert engineers before resource exhaustion occurs. DataOps introduces systemic telemetry, ensuring that memory leaks, network lag, and schema deviations are flagged instantly.
High Data Velocity + Zero Quality Control = Automated Errors at Scale
High Data Velocity + DataOps Infrastructure = Reliable Real-Time Insights
How DataOps Supports Real-Time Data Analytics
Automated Data Pipelines
Manual pipeline deployments introduce human configuration errors. DataOps automates infrastructure provisioning and code deployment using robust CI/CD frameworks.
- Implementation: Using tools like Terraform to define message brokers and cloud storage, combined with GitHub Actions to deploy transformation code automatically upon pull request approval.
- Example: A transportation network automates the deployment of updated geospatial ingestion pipelines across regional cloud instances simultaneously without manual ssh configurations.
Continuous Data Integration
Streaming architectures ingest unstructured or semi-structured data from hundreds of microservices. Continuous integration ensures new data types fit schema contracts perfectly.
- Implementation: Implementing schema registries that validate JSON or Avro schemas during the serialization process before messages hit production topics.
- Example: A gaming firm updates a mobile client’s telemetry schema; the continuous integration pipeline automatically flags incompatible field names before production deployment.
Data Quality Monitoring
DataOps injects automated quality assertions directly into stream runtimes to catch anomalies inline.
- Implementation: Running micro-batch validation checks that evaluate payload ranges, null values, and formatting rules on incoming event streams.
- Example: An e-commerce platform filters out transaction records containing negative prices or missing currency codes before the data reaches the real-time financial ledger.
Data Observability
Data observability goes beyond standard infrastructure uptime monitoring, focusing directly on the health, lineage, and structural integrity of the moving data assets.
- Implementation: Tracking pipeline metrics like data freshness, volume variations, and processing lineage via real-time telemetry layers.
- Example: A media company observes an unusual drop in video-click events per second, instantly isolating a broken tracking tag on a specific mobile application version.
Workflow Orchestration
Real-time architectures require low-latency coordination between ingestion engines, processing clusters, and caching layers.
- Implementation: Utilizing event-driven orchestration tools that trigger tasks based on message arrivals or specific infrastructure signals rather than fixed cron clocks.
- Example: A logistics framework triggers microservice alerts and updates warehouse routing maps the moment a delivery vehicle crosses an established geofence boundary.
Incident Detection and Resolution
When live pipelines fail, data engineering teams must resolve root causes before business applications drift into inaccurate states.
- Implementation: Setting up automated alerting routines linked to on-call paging platforms, backed by clear lineage graphs to pinpoint breaking code changes instantly.
- Example: An ad-tech system detects a sudden 40-millisecond spike in message delivery lag and automatically scales up consumer instances to maintain stable ingestion speeds.
Faster Analytics Delivery
Analytics operations move faster when analysts can modify data models safely without breaking core systems.
- Implementation: Maintaining isolated development environments using containerization alongside automated test suites that mimic production data volume.
- Example: A business intelligence professional safely edits a real-time revenue dashboard’s calculations, running it through automated staging validation before public launch.
Continuous Feedback Loops
A healthy DataOps ecosystem feeds performance data directly back into the development lifecycle to drive optimization.
- Implementation: Reviewing pipeline processing costs, error frequencies, and query speeds to systematically guide next sprint priorities.
- Example: A fintech platform analyzes historical pipeline resource consumption to optimize memory allocations for their stream-processing clusters.
Key Components of a Real-Time DataOps Architecture
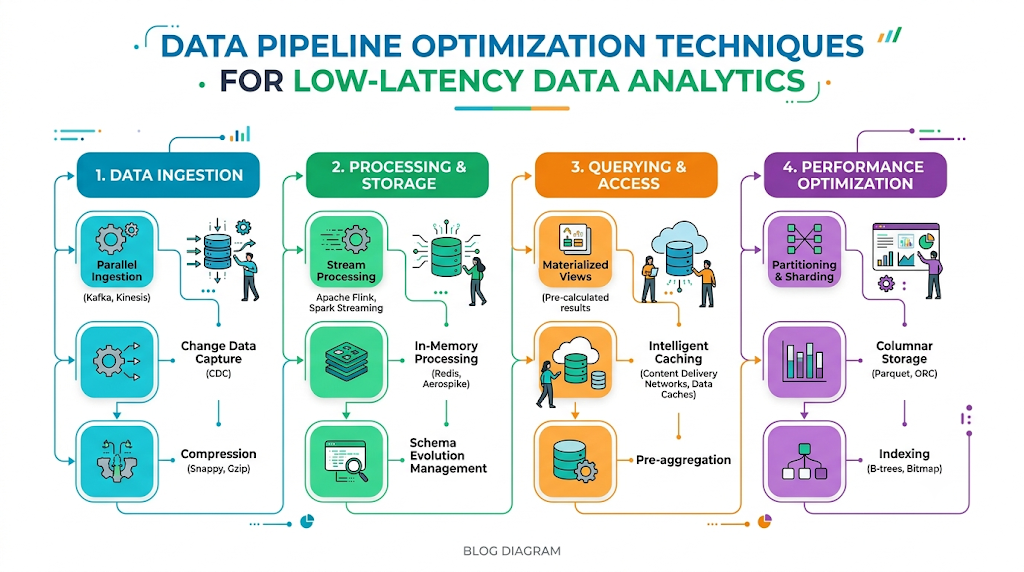
Building a framework capable of handling streaming analytics requires an integrated, multi-layered stack designed for low latency and high reliability.
[Data Sources]
│
▼
[Streaming Platforms (Kafka/Kinesis)]
│
▼
[Data Processing (Flink/Spark)] ◄─── Managed by [Data Observability & Orchestration]
│
▼
[Storage & Analytics Engines]
│
▼
[Visualization Platforms]
1. Data Sources
The primary origin points of high-velocity data, including IoT sensor clusters, web application clickstreams, relational database change data capture (CDC) logs, and external API payloads.
2. Streaming Platforms
Decoupling layers that act as message brokers. These platforms receive incoming payloads safely, durably log them to disk, and make them available to multiple downstream consumers concurrently without performance loss.
3. Data Processing Layers
Stateful computing platforms that read continuous data from streaming platforms, applying filters, joins, aggregations, and windowing functions on the fly.
4. Storage Systems
High-throughput storage layers optimized for rapid writes. These hold the raw event streams, intermediate states, and processed records for deep archival exploration.
5. Analytics Engines
Real-time OLAP (Online Analytical Processing) databases designed to run complex sub-second queries across millions of rows of freshly ingested data.
6. Monitoring and Observability Systems
The central nervous system of DataOps, tracking system performance, data lineage, and schema conformance across every pipeline interface.
7. Visualization Platforms
Live dashboards and end-user interfaces that pull data directly from real-time engines to present up-to-the-second operational realities to business owners.
Core Real-Time Architecture Options
| Architecture Component | Technology Examples | Core Function in DataOps |
| Streaming Platform | Apache Kafka, AWS Kinesis, Redpanda | Durable event buffering, message delivery guarantees |
| Data Processing Layer | Apache Flink, Apache Spark Streaming | Stream transformation, windowed aggregation |
| Storage & Analytics Engine | ClickHouse, Apache Pinot, Snowflake | Low-latency querying, real-time column storage |
| Observability Platform | Datadog, Monte Carlo, OpenTelemetry | Lineage mapping, anomaly alerts, data tracking |
Benefits of DataOps for Real-Time Analytics
Faster Decision Making
By removing manual intervention from code integration and deployments, insights reach dashboards instantly. Leaders make tactical judgments based on what is happening right now, rather than acting on outdated historical patterns.
Improved Data Quality
Continuous testing catches schema drift, missing fields, and corrupted payloads before they pollute production systems. This ensures data consumers always trust the integrity of their metrics.
Better Operational Efficiency
Engineers spend significantly less time on manual interventions. Automating infrastructure orchestration means teams can focus entirely on developing new features, optimizing queries, and refining machine learning models.
Reduced Downtime
Proactive data observability flags system health deterioration prior to catastrophic failures. Catching a creeping storage bottleneck early saves companies from costly service outages.
Enhanced Collaboration
DataOps breaks down functional walls between data engineers, analytics professionals, and software developers. Shared git repositories, clear schema contracts, and collaborative tooling ensure everyone speaks the same technical language.
Scalability
As event volumes grow from thousands to millions per second, DataOps processes scale predictably. Infrastructure as Code patterns make expanding cluster resources simple and error-free.
Improved Business Outcomes
Reliable real-time intelligence translates directly to enhanced revenue generation. Better fraud prevention, immediate conversion optimization, and automated system corrections drive measurable bottom-line value.
Real-World Use Cases
E-Commerce Analytics
Modern retail platforms utilize real-time data analytics to combat cart abandonment and run dynamic pricing engines. DataOps ensures that clickstream tracking pipelines stay stable during massive traffic surges like Black Friday. If a web tracking tag breaks, automated testing catches the schema deviation before inventory systems display incorrect pricing information.
Financial Services Monitoring
High-frequency trading groups and retail banks utilize real-time systems to detect fraudulent credit card transactions. DataOps provides the continuous integration and testing required to deploy updated machine learning models safely. This allows institutions to block fraudulent activity within milliseconds without interrupting legitimate customer payments.
Healthcare Data Operations
Patient monitoring systems generate vast streams of vital metric data. DataOps frameworks guarantee that clinical ingestion channels remain resilient and error-free. If network lag impacts patient data transmission, automated alerting instantly routes traffic to backup infrastructure, keeping clinicians connected to live patient diagnostics.
Manufacturing Intelligence
Industrial IoT setups monitor temperature, vibration, and performance across thousands of factory floor machines. DataOps manages these complex sensor data pipelines to support predictive maintenance strategies. Correctly processed anomalies trigger automated maintenance tickets before expensive machinery encounters catastrophic hardware failures.
Telecommunications Analytics
Telecom networks analyze immense cell tower data volumes to manage bandwidth usage on the fly. DataOps supports these pipelines by validating network logs continuously. This enables carriers to reroute traffic away from congested cells dynamically, ensuring stable call and data quality for active users.
Customer Experience Monitoring
Digital services track user interaction patterns to address user friction instantly. DataOps frameworks monitor data delivery fresh paths continuously. If a new application update causes payment processing errors, the observability platform isolates the problem instantly, allowing product teams to rollback changes before broad user churn occurs.
Common Challenges in Real-Time Analytics
Despite its immense benefits, deploying a real-time system presents unique engineering challenges that can derail standard data teams.
- High Data Volumes: Ingesting millions of events per second puts massive pressure on compute, memory, and network resources, making system crashes common without proper management.
- Data Quality Issues: Unstructured payloads, late-arriving events, and corrupted data records can easily enter streaming channels, polluting downstream analytics engines quickly.
- Infrastructure Complexity: Managing distributed clusters, stateful streaming jobs, and schema registries creates a complex ecosystem that is incredibly difficult to maintain manually.
- Monitoring Gaps: Standard server health monitoring fails to track actual data health, leaving organizations blind to silent pipeline failures and corrupted datasets.
- Security and Compliance Concerns: Streamed data containing personally identifiable information (PII) must be masked and audited instantly to adhere to strict international privacy laws.
How DataOps Solves These Challenges
DataOps provides structural engineering solutions to systemic data management issues, transforming fragile pipeline systems into resilient operations.
[Challenge: Infrastructure Complexity] ──> [DataOps Tool: Infrastructure as Code] ──> [Result: Standardized Environments]
[Challenge: Data Quality Issues] ──> [DataOps Tool: Automated Testing] ──> [Result: Clean Downstream Data]
Automation
By automating infrastructure deployment and scaling policies, organizations manage high data volumes without constant manual tuning. Clusters expand and contract dynamically based on real-time stream pressure.
Standardization
DataOps establishes strict, version-controlled guidelines for how pipelines are built, deployed, and maintained. This removes ad-hoc scripts and unifies team efforts under a reliable engineering methodology.
Continuous Testing
Automated checks are deployed at every stage of the pipeline lifecycle. Code is validated before merging, and data payloads are evaluated instantly during runtime to prevent downstream data pollution.
Data Observability
Implementing deep data observability ensures teams have end-to-end visibility into data health. Lineage mapping helps engineers track down the origin point of errors within minutes rather than hours.
Cross-Team Collaboration
By utilizing code repositories as a single source of truth, developers, engineers, and analysts can collaborate cleanly without breaking downstream dashboards or upstream production microservices.
Tools Commonly Used in DataOps and Real-Time Analytics
An effective streaming architecture relies on specialized tools working together seamlessly across the lifecycle.
- Data Integration & CDC: Qlik Replicate, Debezium, Fivetran. These tools capture source database mutations instantly and stream them into central message queues without impacting source transactional performance.
- Streaming & Message Broker Platforms: Apache Kafka, Redpanda, AWS Kinesis. Distributed event logs designed to handle incredibly high write volumes while guaranteeing durable message retention.
- Orchestration Platforms: Apache Airflow, Prefect, Dagster. Central workflow management tools that coordinate complex data dependencies, manage execution histories, and trigger alerts upon failures.
- Monitoring & Observability Tools: Monte Carlo, Datadog, Great Expectations, OpenTelemetry. Software frameworks that evaluate data quality, measure latency, track lineage, and monitor infrastructure health.
- Analytics & Query Engines: ClickHouse, Snowflake, StarRocks, Apache Pinot. Hyper-fast data stores optimized for executing complex calculations over real-time datasets with sub-second response times.
Best Practices for Implementing DataOps
Success with streaming operations requires a deliberate focus on automation, systemic testing, and cultural alignment.
Automation-First Mindset
Never build data infrastructure manually via cloud consoles. Define every database table, permissions role, and processing pipeline step inside version-controlled code repositories to guarantee environmental consistency.
Build Observability into Pipelines Early
Do not treat monitoring as an afterthought. Integrate data tracing, latency telemetry, and volume alerts directly into your pipeline code from day one to avoid blind spots.
Monitor Data Quality Continuously
Deploy automated testing rules at the ingestion gate, during transformation runs, and right before data hits production analytics layers. Stop malformed payloads before they propagate through your system.
Establish Feedback Loops
Create automated communication loops between your data consumers and platform engineers. Utilize pipeline performance metrics, query logs, and user bug reports to systematically target optimizations.
Optimize for Scalability
Design pipelines assuming your data volumes will eventually triple. Utilize partitioned storage paths, stateless transformation components, and decoupled compute architectures to handle sudden data spikes gracefully.
Future of DataOps and Real-Time Analytics
As technologies evolve, the integration of data operations and streaming engines will become deeper and more automated.
AI-Powered Analytics and Autonomous Operations
Machine learning models will increasingly handle root-cause analysis for broken pipelines. Future architectures will identify schema drifts and automatically patch transformation code in real time without human engineers needing to wake up for on-call shifts.
Predictive Data Observability
Observability frameworks will evolve from identifying existing failures to predicting potential pipeline bottlenecks. Systems will analyze historical ingestion trends to scale up computing clusters before data surges arrive.
Cloud-Native Unified Platforms
The lines separating streaming platforms, processing engines, and analytical databases will continue to blur. Next-generation data platforms will provide unified, serverless architectures that manage ingestion and sub-second querying within a single, highly automated interface.
Career Opportunities
The growth of streaming data systems has created a massive enterprise need for specialized engineering talent skilled in modern data methodologies.
- DataOps Engineer: Professionals focused on building CI/CD pipelines, automating infrastructure deployment, and managing containerized data processing environments.
- Analytics Engineer: Advanced data specialists who apply software engineering best practices to clean, transform, and model data for business consumption.
- Data Platform Engineer: Software professionals who architect and scale the underlying core engines, message brokers, and analytical databases.
- Data Reliability Engineer: Specialists dedicated to maintaining data pipeline uptime, managing data observability platforms, and optimizing query performance.
- Data Architect: Strategic tech leaders who design the comprehensive, end-to-end blueprinted flow of data assets across an entire enterprise.
Common Misconceptions About DataOps and Real-Time Analytics
Myth: DataOps Is Just DevOps with a Different Name
Reality: While DataOps adopts DevOps concepts like CI/CD, it deals with unique data challenges. DevOps focuses entirely on code deployment stability. DataOps must manage code stability while constantly handling unpredictable variations in data quality, schema mutations, and data volume.
Myth: Real-Time Analytics Is Always Expensive to Build and Run
Reality: Poorly designed real-time streaming architectures are expensive. However, by leveraging modern DataOps principles—such as automated infrastructure scaling and efficient columnar storage engines—organizations can run high-velocity pipelines at highly optimized price points.
Myth: Small Data Teams Do Not Need a DataOps Strategy
Reality: Small data engineering groups actually benefit immensely from automation. Implementing automated data testing and deployment loops frees small teams from constant manual troubleshooting, allowing them to deliver massive value quickly.
FAQ Section
1. What is the main difference between DevOps and DataOps?
DevOps focuses entirely on automating software application development, code deployments, and infrastructure uptime. DataOps adapts these principles specifically for data environments, managing code environments while simultaneously monitoring data quality, data lineage, and schema drift across dynamic pipelines.
2. Does real-time analytics require completely replacing batch pipelines?
No. Most modern data organizations leverage hybrid architectures, such as the Lambda or Kappa architecture patterns. Real-time pipelines handle instant operational insights (like fraud detection), while batch frameworks run concurrently to process heavy historical reports and deep financial compliance jobs.
3. How does DataOps prevent bad data from reaching live dashboards?
DataOps implements automated data quality tests directly within the ingestion and processing stream. If an event payload violates schema validation rules or falls outside acceptable data ranges, the system flags the record, routes it to a dead-letter queue for inspection, and alerts engineers before it can impact production dashboards.
4. What is schema drift, and how does DataOps handle it?
Schema drift occurs when upstream source applications alter their data structures—such as renaming database columns or changing data types—without warning the downstream data team. DataOps manages this via automated schema registries that block incompatible payloads before they enter production streaming networks.
5. Is Apache Kafka required to build a real-time data pipeline?
While Apache Kafka is an industry standard for durable event streaming, it is not your only option. Depending on your organization’s specific scale, cloud providers, and architecture goals, alternative message brokers like Redpanda, Apache Pulsar, or AWS Kinesis can fill this role effectively.
6. How does data observability differ from standard software monitoring?
Standard software monitoring tracks infrastructure metrics like server CPU loads, memory utilization, and network traffic. Data observability focuses specifically on the internal health of the data itself, analyzing data freshness, distribution anomalies, volume mutations, and end-to-end data lineage graph states.
7. Can we implement DataOps principles without buying new software tools?
Yes. DataOps is fundamentally a cultural and operational methodology, not a specific software tool. You can begin implementing it using open-source version control (Git), writing custom testing assertions in SQL or Python, and organizing team workflows around agile processes.
8. What are the primary business metrics improved by DataOps?
DataOps directly optimizes critical operational metrics, including time-to-insight (how fast data moves from source to user), data downtime (pipeline outage duration), production error rates, and the overall deployment velocity of new analytical features.
9. How do you handle late-arriving data records in streaming analytics?
Stream processing engines use a concept called watermarking to handle data that arrives late due to network lag. Watermarks allow the processing engine to keep a specific time window open for an acceptable duration, ensuring late events are aggregated correctly before finalizing window metrics.
10. What is a dead-letter queue (DLQ) in real-time data streams?
A dead-letter queue is a isolated storage destination where a streaming platform routes malformed, corrupted, or unparseable messages. This prevents a broken payload from blocking the entire processing pipeline, allowing healthy messages to pass through while engineers debug the bad data offline.
Final Summary
The modern enterprise runs on data speed and data trust. As companies shift away from rigid historical reporting towards immediate, real-time decision-making, traditional data pipelines can no longer keep pace. High-velocity streaming systems require proactive, automated discipline to remain accurate, resilient, and cost-effective under continuous pressure. Implementing a structured DataOps methodology transforms fragile data architectures into reliable delivery systems. By introducing automation-first workflows, deep data observability, and inline data quality testing, organizations eliminate the manual firefighting that historically stalled engineering teams. DataOps turns data streams into trustworthy assets that drive fast operational decisions.