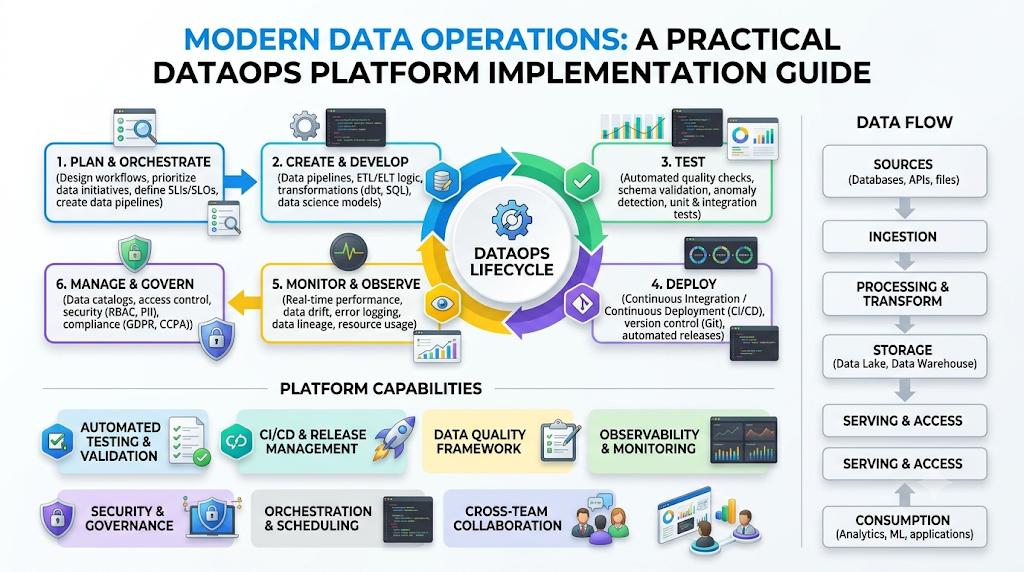
Introduction
Modern data ecosystems are expanding at an unprecedented rate. Centralized databases have given way to distributed cloud data warehouses, real-time data streaming architectures, and multi-cloud data lakes. While these systems provide incredible raw storage and computing power, managing them has become incredibly complex for modern data teams. To bridge this operational gap, data leaders are shifting toward modern data operations. This methodology applies software engineering discipline directly to data delivery. Executing a highly effective DataOps Platform Implementation allows companies to transform chaotic, fragile data pipelines into predictable, highly automated, and self-healing systems. This detailed educational guide covers everything you need to know about setting up a successful data platform. You will learn the core structural requirements, common operational challenges, practical best practices, and real-world deployment roadmaps needed to maximize your organization’s data agility.
Understanding DataOps Platform Implementation
A successful DataOps platform implementation introduces a unified operational layer that orchestrates data tools, enforces data quality automation, and manages the entire lifecycle of data assets. Rather than representing a single product or tool, it is an integrated engineering ecosystem built around automated orchestration, continuous integration, and deep pipeline observability.
+------------------------+
| Orchestration Layer |
+-----------+------------+
|
+----------------------+----------------------+
| |
+-------v--------+ +------v-------+
| CI/CD Engine | | Observability|
+-------+--------+ +------+-------+
| |
+----------------------+----------------------+
|
+-----------v------------+
| Data Quality Guardrails|
+------------------------+
Core Objectives of DataOps
The primary goal of this framework is to shorten the development lifecycle of data products while maintaining excellent data quality. It establishes automated testing guardrails at every phase of ingestion, transformation, and distribution. This gives business users access to reliable data without putting an extra burden on platform engineering teams.
Driving Force Behind Adoption
Organizations adopt this framework because traditional, manual management scales poorly. When data environments grow to include thousands of daily pipelines, manual oversight becomes impossible. Teams need automated systems that flag anomalies, validate schemas, and deploy code changes automatically without causing downtime.
The DevOps and Agile Connection
This methodology adapts proven principles from software development and IT infrastructure management to data environments:
- Agile Data Management: Uses iterative sprints to build data products, ensuring data teams deliver immediate value instead of waiting for massive, multi-month delivery cycles.
- DevOps Principles: Brings continuous integration and continuous deployment (CI/CD) to data work. Version control tools manage data infrastructure as code, ensuring that all transformations are peer-reviewed and fully automated.
Why DataOps Matters in Modern Data Environments
The push for automation across modern data operations is fueled by deep architectural shifts and changing business requirements.
UNMANAGED DATA PIPELINES AUTOMATED DATAOPS PIPELINE
[ Source ] [ Source ] [ Source ] [ Source ]
\ / \ /
v v v v
+------------------------+ +------------------------+
| Broken Schemas | | Labeled Data Testing |
| Silent Degradation | | Continuous Monitoring |
| Manual QA Bottlenecks | | Automated Recovery |
+-----------+------------+ +-----------+------------+
| |
v v
[ Downstream Analytics ] [ Trusted Actionable Insights ]
Navigating Rapid Data Growth
Data volumes are scaling past the limits of legacy systems. Organizations now ingest unstructured, semi-structured, and streaming data from hundreds of external platforms, IoT devices, and application logs. Automated platforms handle this variety smoothly, ensuring pipelines scale without needing constant manual updates.
Serving Faster Analytics
Business stakeholders no longer want to wait for weekly or monthly batch reports. Modern operations require real-time dashboards and instantaneous streaming analytics to power machine learning models. Automated operational frameworks ensure pipelines run quickly and reliably enough to support immediate decision-making.
Meeting Strict Quality Expectations
Poor data quality quickly erodes organizational trust. If a broken upstream pipeline slips into an executive dashboard, it can lead to bad business choices and hours of stressful debugging. Automating data quality tests ensures errors are caught and isolated before they reach downstream systems.
Lowering Operational Overhead
Without automation, data engineering teams get trapped in a reactive cycle of manual work, often called data linting. Engineers waste hours reviewing query logs and manually restarting failed jobs. Standardizing workflows lets teams break this cycle, giving them time back to build strategic features.
Supporting True Business Agility
Markets shift quickly, requiring companies to update their analytics logic just as fast. An automated pipeline environment lets engineers modify models, test adjustments in isolated sandboxes, and push updates to production confidently in minutes instead of weeks.
Common Challenges During DataOps Platform Implementation
Deploying an enterprise-wide framework often comes with unexpected technical and organizational hurdles.
+---------------------------+-------------------------------------------------------------+
| Implementation Challenge | Real-World Enterprise Scenario |
+---------------------------+-------------------------------------------------------------+
| Legacy System Integration | Connecting a modern cloud warehouse to an on-prem mainframe |
| Data Silos | Marketing and finance teams keeping separate customer lists |
| Governance Complexity | Masking PII data dynamically across multiple cloud regions |
| Team Alignment Issues | Data scientists using custom scripts outside standard Git |
| Tool Proliferation | Managing five different orchestrators across departments |
| Engineering Skill Gaps | SQL analysts needing to learn advanced Git CI/CD actions |
+---------------------------+-------------------------------------------------------------+
Legacy System Integration
Many enterprises rely on older on-premises databases and rigid legacy ETL tools. These systems lack the modern APIs and metadata hooks needed for automated testing and real-time observability.
Example: A bank trying to link a modern cloud data warehouse with an on-prem main frame often encounters slow batch windows and formatting issues that disrupt automated pipelines.
Overcoming Internal Data Silos
Different departments frequently use distinct SaaS applications and storage solutions without central coordination. This makes it tough to build clean, end-to-end operational visibility.
Example: When the marketing team and finance team maintain independent customer databases, creating unified reporting pipelines often results in mismatched totals and conflicting insights.
Navigating Governance Complexity
Enforcing strict data privacy rules like GDPR and CCPA across complex pipelines can slow down engineering velocity if handled manually.
Example: An enterprise-wide deployment must automatically mask personally identifiable information (PII) during ingestion, without requiring engineering teams to write custom security logic for every new pipeline.
Resolving Team Alignment Issues
Data engineers, analytics engineers, data scientists, and business analysts often work in isolation, using different tools, workflows, and communication channels.
Example: A data science team might deploy machine learning models using custom scripts that bypass standard Git workflows, creating tracking blind spots for the core platform engineers.
Managing Tool Proliferation
Without clear standards, different teams buy different tools for ingestion, transformation, and scheduling, leading to fragmented infrastructure.
Example: A company might end up running three different orchestration engines across five teams, making it nearly impossible to build a single, unified view of pipeline health.
Addressing Engineering Skill Gaps
Moving to code-driven data operations requires analysts and engineers to master advanced software development skills like version control, containerization, and writing automated tests.
Example: SQL analysts comfortable with manual query execution often need targeted training to safely use Git branch architectures, perform code reviews, and manage automated deployment pipelines.
Best Practices for DataOps Platform Implementation
Successfully deploying a DataOps implementation strategy requires combining the right technology with clear processes and cultural alignment. Focus on these eight core practices to set your team up for success.
PLANNING PHASE ENGINEERING PHASE OPERATIONS PHASE
+-----------------------+ +-----------------------+ +-----------------------+
| Define Clear Goals | ---> | Standardize Pipelines | ---> | Continuous Monitoring |
| & Business Outcomes | | & Automated Testing | | and Observability |
+-----------------------+ +-----------------------+ +-----------------------+
^ | |
| v v
| +-----------------------+ +-----------------------+
+----------------------| Unified Governance | <--------| Cross-Team Cohesion |
+-----------------------+ +-----------------------+
1. Define Clear Business Objectives
Avoid implementing tools purely for the sake of technology. Tie your platform work to concrete business goals like reducing dashboard load times, accelerating new report delivery, or cutting cloud infrastructure costs.
- Implementation Guidance: Sit down with business leaders to find their biggest data pain points. Frame your project goals around fixing these specific business metrics.
- Example: A retail business might focus on reducing the time it takes to process inventory data from 12 hours to 15 minutes, allowing store managers to optimize stock in near real-time.
2. Build a Strong Data Governance Foundation
Governance should be built directly into your pipelines rather than treated as an afterthought. Automate policy checks so data protection happens naturally as data moves through your system.
- Implementation Guidance: Use data catalogs that automatically tag sensitive data at ingestion, and apply automated access controls based on user roles.
- Example: A healthcare data system can use automated policies to find and encrypt patient identifier fields across ingestion buckets before the data ever reaches analytics environments.
3. Standardize Data Pipelines
Get rid of custom, one-off ingestion scripts. Build reusable, modular pipeline templates so your engineering team can build and scale workloads consistently.
- Implementation Guidance: Create base configuration files for common tasks like API ingestion, schema validation, and delta loading that any team member can quickly copy and deploy.
- Example: An infrastructure team can build a standard ingestion template so that adding a new Salesforce or HubSpot data source requires editing a short configuration file rather than writing new python scripts.
4. Automate Data Testing
Treat data quality checks like unit tests in software engineering. Test your data at every key milestone: during ingestion, right after transformations, and before updating production tables.
- Implementation Guidance: Add validation steps that automatically check for missing values, unexpected schema changes, and out-of-bounds metrics.
- Example: An e-commerce pipeline can instantly halt an ingestion run if a vendor file accidentally arrives with zero values in the price column, preventing broken data from hitting downstream sales reports.
5. Implement Continuous Monitoring
Maintain clear visibility into pipeline health. Set up automated tracking for job statuses, execution times, and infrastructure resource use.
- Implementation Guidance: Build centralized alerts that ping messaging channels like Slack or Microsoft Teams the moment an orchestration job hits an error.
- Example: A logistics platform uses automated alerts to notify the on-call engineer within two minutes if an API connector times out, keeping minor connection drops from derailing morning business updates.
6. Improve Data Observability
Go beyond basic up/down monitoring. Focus on full data observability, which tracks data lineage, volume changes, freshness metrics, and statistical anomalies.
- Implementation Guidance: Use lineage tracking tools to map exactly how data flows from source systems down to your final business intelligence charts.
- Example: If an executive spots an unusual dip in a revenue graph, an engineer can use lineage maps to instantly trace the issue back to a missing database export from an overseas ERP system.
7. Encourage Cross-Functional Collaboration
Break down walls between data producers, platform engineers, and business analysts. Create shared spaces for code reviews and build out a central repository of approved documentation.
- Implementation Guidance: Bring analysts, engineers, and data scientists together into unified product teams focused on specific business domains like marketing or finance.
- Example: A financial technology company runs weekly cross-team code reviews where analysts and data engineers work together on transformation logic, ensuring the code aligns with both technical standards and business needs.
8. Continuously Measure Performance
You can’t optimize what you don’t track. Monitor your operational data to track how your platform scales and find engineering bottlenecks.
- Implementation Guidance: Set up an internal dashboard that tracks key delivery metrics like deployment frequency, pipeline uptime, and test coverage trends.
- Example: A data platform team reviews their metrics every month to see which pipelines run slow or fail often, allowing them to focus engineering time on the absolute highest-priority optimizations.
Building a Modern DataOps Architecture
A resilient modern data operations platform is built on an interconnected, multi-layered architecture where every component handles a specific phase of the data lifecycle.
## Conceptual Management Architecture ##
+--------------------------------------------------------------------------+
| MANAGEMENT & ORCHESTRATION |
| Git Control / CI-CD Runners |
+--------------------------------------------------------------------------+
| |
| +--------------------+ +--------------------+ +------------+ |
| | Ingestion Layer | ---> | Transformation | ---> | Consumers | |
| | S3 / Kafka / APIs | | Snowflake / dbt | | BI / ML | |
| +---------+----------+ +---------+----------+ +------------+ |
| | | | |
| v v | |
| +--------------------------------------------------------------------+ |
| | DATA QUALITY & OBSERVABILITY FRAMEWORK | |
| | Anomaly Detection / Lineage Engine | |
+--+--------------------------------------------------------------------+--+
Here’s how a modern DataOps framework structures the flow of data:
Data Ingestion Layer
This layer handles extracting data from varied sources—like production databases, SaaS tools, and IoT devices—and loading it into your central repository. It manages both high-frequency streaming data and daily batch uploads smoothly.
Data Transformation Layer
Once raw data lands in your cloud warehouse or data lake, this layer handles reshaping, cleaning, and aggregating it into business-ready formats. Modern architectures manage these transformations as code using version control systems.
Data Quality Framework
This component acts as an automated gatekeeper. It runs data quality validation checks across every stage of your pipeline, isolating suspect data in sandbox environments so your production tables stay clean and accurate.
Pipeline Orchestration
The orchestration engine acts as the command center for your entire data system. It coordinates complex dependencies across systems, schedules jobs efficiently, and triggers automated recovery workflows if a step fails.
Monitoring and Observability
This layer acts as your system’s nervous system. It constantly tracks execution logs, metadata trends, and processing costs, giving your team a clear, real-time look into the overall health and efficiency of your data estate.
Reporting and Analytics
The final destination layer makes processed data easily available to business users. It feeds clean, reliable data directly into analytics dashboards, embedded applications, and machine learning models to drive daily business decisions.
Key Components of a Successful DataOps Platform
+---------------------------------------------+
| SUCCESSFUL DATAOPS IMPLEMENTATION |
+----------------------+----------------------+
|
+------------------------+------------------------+
| |
+--------v---------+ +---------v--------+
| AUTOMATION | | SECURITY |
| * Testing | | * RBAC Access |
| * Monitoring | | * PII Encryption|
| * Collaboration | | * Audit Trails |
+------------------+ +------------------+
When building or buying tools for your platform, ensure your stack solidly covers these six foundational areas:
- Automation: Handles code deployments, schema updates, and environment provisioning via code repositories, minimizing manual tasks.
- Testing: Automatically runs business rule validations and structural schema checks every time your data pipelines run.
- Monitoring: Provides real-time visibility into infrastructure health, alerting your team the moment a data job drops or delays.
- Collaboration: Gives your entire team a unified workspace with shared code tracking, documentation libraries, and clear data lineage.
- Governance: Automates data tracking, tracks lineage end-to-end, and manages metadata to maintain organizational compliance.
- Security: Enforces strict role-based access controls (RBAC), data masking rules, and clear audit logs across all environments.
DataOps Implementation Roadmap
Moving your organization to a structured operational model is a journey that works best when taken in incremental, well-planned steps.
Phase 1: Assessment
Start by auditing your current data infrastructure, pipeline processes, and team skills. Identify your biggest engineering bottlenecks, document data tech debt, and map out where data silos exist across departments.
Phase 2: Planning
Define your core platform architecture and select the tooling that fits your business needs. Build a clear, phased deployment schedule and establish your baseline performance metrics so you can measure progress.
Phase 3: Pilot Deployment
Pick a single, high-value data pipeline to serve as your proof of concept. Build out automated testing, version control, and continuous integration for this pilot project to demonstrate immediate value to stakeholders.
Phase 4: Scaling Across Teams
Take the lessons learned from your pilot and roll the framework out to other departments. Run internal training sessions to help analysts and engineers adopt the new version control and testing workflows.
Phase 5: Continuous Optimization
Regularly review your platform performance metrics to find new optimization opportunities. Refine your testing templates, optimize cloud warehouse costs, and update your automation workflows to keep pace with changing business needs.
Metrics for Measuring DataOps Success
To justify your platform investment and guide engineering work, track these key performance indicators over time:
| Operational Metric | Business Definition | Target Trend |
| Pipeline Reliability | Percentage of pipeline runs that complete successfully without manual intervention. | Target: Greater than 99.5% |
| Data Quality Scores | Ratio of rows that pass validation checks versus total ingested records. | Target: Greater than 99.9% |
| Deployment Frequency | How often your data team safely pushes code changes or new models to production. | Target: Multiple times per day |
| Mean Time to Recovery (MTTR) | The average time it takes your team to fix a broken pipeline after an alert drops. | Target: Under 15 minutes |
| Analytics Delivery Speed | The total time required to build, test, and ship a brand-new data product or report. | Target: Reduced from weeks to days |
| Operational Efficiency | Hours engineering teams spend on manual fixes versus strategic feature development. | Target: Less than 10% on maintenance |
Real-World DataOps Use Cases
Implementing an automated data platform delivers clear operational advantages across a wide range of industries and applications:
Business Intelligence Platforms
Large companies often struggle with slow, out-of-date executive dashboards. Automating ingestion and testing ensures business leaders see fresh, accurate metrics every morning without requiring night-shift engineering oversight.
Financial Analytics Systems
Financial institutions have zero tolerance for data errors or late reporting. Automated data operations enforce strict validation checks, keeping incorrect figures from throwing off regulatory reports or risk models.
Healthcare Data Operations
Healthcare providers navigate a complex web of compliance rules and patient data systems. Automated governance paths securely mask sensitive information at ingestion while keeping clinical research pipelines running quickly.
E-Commerce Analytics
Online retail requires rapid responses to changing customer behavior. Automated pipelines process clickstream data, inventory levels, and transaction records in near real-time, helping marketing teams optimize promotions instantly.
Customer Data Platforms (CDP)
Marketing teams need a unified view of customer interactions across web, mobile, and support channels. A structured platform architecture cleans and resolves conflicting identity records automatically, creating a single source of truth for user profiles.
Enterprise Reporting Systems
Global organizations often run into reporting conflicts when regional offices use different software. Automated platforms standardize these disparate data sources into a shared schema, making global financial and operational reporting smooth and consistent.
DataOps Tools and Technologies
Building a modern platform involves assembling a well-coordinated stack of specialized tools rather than relying on a single vendor solution.
+------------------------------------+-------------------------------------------+
| Core Tooling Category | Primary Role in Your DataOps Stack |
+------------------------------------+-------------------------------------------+
| Data Integration Platforms | Handles raw extraction and ingestion |
| Orchestration Tools | Manages job schedules and dependencies |
| Data Quality Solutions | Validates data values and schemas |
| Monitoring & Observability Tools | Tracks data health and lineage end-to-end |
| Collaboration Tools | Hosts code control and team documentation |
+------------------------------------+-------------------------------------------+
- Data Integration Platforms: Modern ELT tools focus on extracting data from varied sources and loading it efficiently into cloud storage warehouses without complex manual coding.
- Orchestration Engines: Advanced workflow schedulers handle complex task dependencies, manage resource allocation, and trigger error-recovery steps automatically.
- Data Quality Solutions: Validation frameworks allow engineers to define expectation profiles for data, automatically isolating rows that fail structural or statistical rules.
- Monitoring & Observability Platforms: End-to-end observability tools map data lineage, track pipeline performance metrics, and spot statistical anomalies across your entire data landscape.
- Collaboration & Version Control: Git platforms and shared documentation repositories serve as the team’s single source of truth for code, review histories, and architecture maps.
Governance and Security Considerations
A modern platform must balance engineering speed with robust data security and organizational compliance.
Data Privacy Controls
Your platform must protect customer privacy automatically. Build masking and encryption rules directly into your standard ingestion templates so sensitive details are secured before data is stored for analysis.
Access Management
Implement strict, role-based access controls across all environments. Ensure that developers, data scientists, and business analysts only see the specific data rows and columns required for their roles.
Compliance Automation
Avoid relying on manual data audits. Use platforms that automatically log metadata, track data lineage, and document user access histories to make proving compliance with rules like HIPAA or GDPR simple.
Full Auditability
Maintain a complete record of your data ecosystem. Track every version of your transformation code, every schema change, and every pipeline run so you can easily audit how data was modified over time.
Risk Management
Build automated safeguards into your deployment processes. Use isolated sandbox environments for testing and set up automated rollbacks so that a faulty code update can be reversed instantly without disrupting production users.
Future of DataOps Platforms
As technology evolves, the way organizations manage data platforms continues to mature.
- AI-Driven Data Operations: Machine learning models are starting to handle routine platform work—like automatically tuning query performance, fixing simple pipeline errors, and predicting infrastructure capacity needs.
- Expanded Data Observability: Tracking is moving closer to real-time. Future systems will spot micro-anomalies inside streaming data channels the moment they appear, rather than waiting for batch logs.
- Cloud-Native Data Foundations: Data platforms are becoming more decoupled and modular, utilizing serverless computing to scale resources up or down instantly based on real-time processing demands.
- True Self-Service Analytics: Better automation means non-technical business users will soon be able to provision clean, compliant sandboxes and data sets safely on their own, without needing help from central engineering teams.
- Autonomous Data Pipelines: Future data pipelines will be self-healing, automatically adjusting to upstream schema changes and rerouting data paths during cloud outages without requiring manual code fixes.
Career Opportunities in DataOps
The rise of automated data management is creating high-demand, specialized engineering roles across the technology sector:
DataOps Engineer
Focuses on building and maintaining the team’s CI/CD infrastructure. They automate code deployment paths, manage testing environments, and ensure development tools integrate smoothly.
Data Platform Engineer
Designs and scales the core underlying data infrastructure—including cloud data warehouses, streaming clusters, and orchestration layers—ensuring the system remains highly available.
Analytics Engineer
Sits between pure data engineering and business analysis. They write clean, version-controlled transformation code, build reusable data models, and enforce testing standards across business reports.
Data Architect
Designs the high-level blueprints for the organization’s entire data estate. They set integration standards, define the technical stack, and ensure data layouts support long-term business goals.
Data Reliability Engineer (DRE)
Dedicated to keeping production pipelines stable and reliable. They monitor data quality, manage alert systems, respond to incident outages, and work to reduce operational maintenance overhead.
Common Misconceptions About DataOps Implementation
Let’s clear up a few frequent misunderstandings that can derail team adoption:
Myth: DataOps is just DevOps renamed for data teams.
Reality: While it shares DevOps principles like CI/CD and automation, it deals with unique challenges like data state changes, schema evolution, and managing data quality alongside code updates.
Myth: Implementing DataOps requires buying a single, expensive tool.
Reality: It is a cultural philosophy and an architectural approach. You can build a great framework by connecting open-source tools and standardizing your processes around version control and automated testing.
Myth: DataOps is only useful for giant tech companies with massive data scale.
Reality: Small and mid-sized teams see huge benefits from automation. Reducing manual debugging times helps lean teams deliver data products much faster and with fewer operational mistakes.
FAQ Section
- What is the first step in a DataOps platform implementation?
Audit your current data pipelines to find your biggest processing bottlenecks, and establish clear version control practices across your engineering team.
- How does DataOps improve data quality?
It builds automated testing checks directly into your pipelines, ensuring bad data or broken schemas are isolated before they reach production tables.
- Can we build a DataOps framework using our existing data tools?
Yes, you can connect your existing databases, transformation engines, and schedulers into an automated framework using version control and open-source orchestrators.
- What is the difference between data monitoring and data observability?
Monitoring tells you when a pipeline job fails, while observability looks deeper to trace data lineage, track volume anomalies, and assess the overall health of data values.
- How long does a typical DataOps platform implementation take?
A pilot pipeline can be automated in a few weeks, but rolling out a comprehensive enterprise platform across multiple departments usually takes several months.
- Who should lead a DataOps adoption initiative inside a company?
The effort is typically led by a Head of Data, Lead Data Architect, or Platform Engineering Manager who understands both the technical stack and business requirements.
- Does DataOps replace traditional data governance practices?
No, it complements traditional governance by automating compliance policies, tracking lineage, and managing access rules directly within your automated workflows.
- What are the most critical metrics for measuring implementation success?
Focus on tracking pipeline reliability percentages, data quality validation scores, deployment frequency, and your team’s mean time to recovery (MTTR).
- How does an analytics engineer contribute to a DataOps platform?
Analytics engineers write clean, tested, and version-controlled transformation code, bridging the gap between raw data pipelines and final business dashboards.
- Is DataOps applicable to real-time streaming data environments?
Yes, it is highly valuable for streaming systems, helping teams automate schema checks and monitor processing lag across real-time data feeds.
Final Summary
Building out a comprehensive DataOps platform implementation is essential for any modern enterprise looking to stay competitive in a data-driven world. Shifting away from manual, reactive pipeline management toward an automated, code-driven approach helps eliminate processing bottlenecks, reduces engineering overhead, and ensures your team delivers accurate, trustworthy data products. Sustained operational success comes down to solid execution: standardizing your pipelines, automating your testing, and building a culture of cross-functional collaboration. Focusing on these core engineering practices allows you to transform complex data infrastructure into a highly reliable asset that drives rapid business growth.