Introduction
Real-time DataOps is a critical evolution in how modern organizations manage the constant flow of information. By integrating automation, continuous testing, and real-time processing, businesses can transition from slow, batch-oriented reporting to immediate, actionable intelligence. Successfully implementing these high-speed pipelines requires a rigorous methodology to ensure data quality, consistency, and reliability across the entire infrastructure. TheDataOps.org provides the structured guidance and best practices necessary to navigate this complexity and establish robust operational frameworks. This guide outlines the core architecture and implementation strategies required to achieve excellence in real-time DataOps, offering the clarity needed to build pipelines that are both highly performant and easy to maintain.
Understanding Real-Time DataOps
What is Real-Time DataOps?
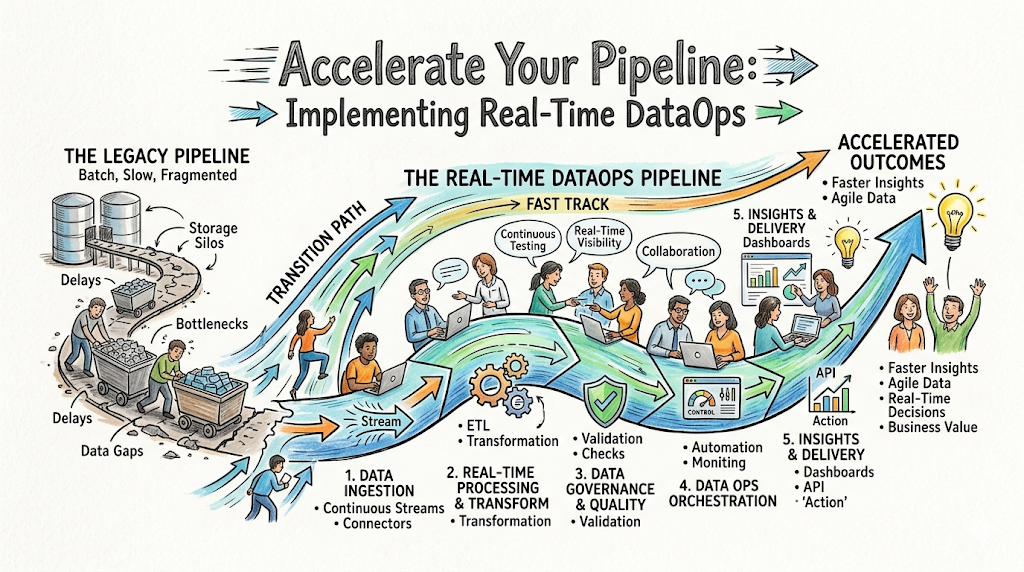
At its heart, DataOps is about speed and quality. Real-time DataOps applies those same principles to data that arrives in a continuous stream. Instead of processing data in large “batches” once a day, it processes every tiny piece of information the second it is created, keeping your business systems perfectly synchronized.
Why Real-Time Data Matters in Modern Businesses
Today’s market moves instantly. If a bank waits until the end of the day to check for fraud, the money is already gone. If a delivery company waits hours to update a package location, the customer loses trust. Real-time data turns information into immediate action, giving companies a massive competitive advantage.
Traditional vs Real-Time Data Pipelines
Think of traditional data as a mail service that delivers letters once a day. Real-time data is like a phone call; it happens live. Traditional batch pipelines are great for long-term trends, but they lack the urgency required to manage live inventory, fraud detection, or active system performance.
Role of TheDataOps.org in Modern DataOps Practices
Implementing high-speed pipelines is difficult and often error-prone. TheDataOps.org acts as a mentor, providing standardized frameworks and proven methodologies that help teams avoid common pitfalls. By following these structured paths, organizations can build pipelines that are not only fast but also reliable and easy to maintain.
Core Architecture of Real-Time DataOps Systems
Data Ingestion Layer
This is the “doorway” where data enters your system. It collects information from apps, sensors, or websites. For instance, a mobile app sends a signal every time a user clicks a button, and the ingestion layer catches that signal immediately.
Stream Processing Layer
Once data enters, it needs to be understood. This layer filters, cleans, and organizes the data in motion. Imagine a conveyor belt where a machine automatically removes broken items before they reach the packaging stage.
Data Transformation Layer
Here, raw data is converted into a useful format. If you receive “temp: 72” and “unit: fahrenheit,” this layer combines them into a clear reading so your dashboard can display “72°F” instantly.
Real-Time Storage Systems
Real-time systems need special, high-speed databases. Unlike standard archives, these are built to be read and written to simultaneously, ensuring your charts never lag.
Observability and Monitoring Layer
This is your “control tower.” It alerts you if a pipeline slows down or if the data looks wrong. If a sensor stops sending information, this layer sounds the alarm before the business impact is felt.
How TheDataOps.org Guides Real-Time DataOps Implementations
Standardized Data Pipeline Design
Consistency is key to speed. TheDataOps.org promotes using uniform design patterns across all teams, so every pipeline is built with the same level of reliability. Example: Every new pipeline must include a standardized “error-handling” step to ensure no data is ever lost.
Automation-First Data Delivery Approach
Manual tasks slow down data. By automating the testing and deployment of data code, teams can move faster. Example: A system automatically runs a test every time a developer updates a data transformation rule to ensure it doesn’t break the live feed.
Real-Time Data Validation Techniques
Validating data after it’s stored is too late. TheDataOps.org suggests checking data at the moment of ingestion. Example: If a system receives a negative value for a product price, it instantly flags or rejects that record before it ruins your revenue report.
Continuous Monitoring and Feedback Loops
Data health is not a one-time check. By using constant feedback loops, teams can see how their pipelines are performing throughout the day. Example: A team gets a notification when a pipeline’s latency exceeds five seconds, allowing them to fix the bottleneck immediately.
Scalable Architecture Best Practices
Your data needs will grow. TheDataOps.org guides teams on building systems that can handle a thousand clicks today and a million tomorrow without needing a total redesign.
Data Quality and Governance Frameworks
Speed means nothing if the data is wrong. Robust governance ensures that data follows strict rules from the moment it is created. Example: Automatically tagging data by department so that sensitive information is only accessible by authorized users.
Real-World Use Cases of Real-Time DataOps
E-Commerce Real-Time Recommendations
A store tracks what you click and updates the “Recommended for You” section instantly on your next page load to increase the chance of a sale.
Banking Fraud Detection Systems
A bank analyzes your location and spending history in milliseconds to block a suspicious credit card purchase before it is approved.
Logistics and Supply Chain Tracking
A shipping company uses live GPS updates to reroute delivery trucks around traffic jams, saving time and fuel.
Healthcare Monitoring Systems
Wearable health devices send heart rate data to a doctor’s dashboard, triggering an instant alert if a patient’s vitals enter a dangerous range.
SaaS Application Performance Monitoring
A software provider monitors how users interact with their tool, fixing bugs or performance issues before users even realize they are happening.
Benefits of Real-Time DataOps Implementation
- Faster Decision Making: Leaders have the live facts they need, when they need them.
- Improved Data Accuracy: Automated validation stops errors from spreading through your systems.
- Reduced Latency in Insights: There is no waiting for the “overnight batch” to finish.
- Better Customer Experience: Customers enjoy smooth, responsive, and personalized services.
- Scalable Data Infrastructure: Your system grows with your business needs.
- Automated Error Handling: Small issues are fixed automatically before they become outages.
Challenges in Real-Time DataOps
Data Latency Issues
Sometimes, network delays can slow down streams, making it hard to achieve true “zero-latency.”
System Complexity
Managing live streams is more difficult than managing static files, requiring specialized tools and training.
Integration Difficulties
Connecting new real-time tools with your existing “legacy” databases can be a complex technical hurdle.
Data Quality Problems
If raw data is messy at the source, your real-time system might propagate those errors at lightning speed.
Skill Gaps in Teams
DataOps requires a blend of data engineering and software development skills, which can be hard to find and hire for.
Best Practices for Real-Time DataOps Implementation
Start with High-Impact Pipelines
Don’t overhaul everything. Pick the one business process where “live” data matters most and optimize that first.
Use Event-Driven Architecture
Design your system so that actions trigger other actions automatically, reducing the need for constant polling or manual checks.
Automate Data Validation
Always treat data as “guilty until proven innocent” by running automated tests at every stage of the pipeline.
Implement Strong Observability
Make sure your team can see what is happening inside the pipeline, not just at the end of it.
Continuously Optimize Pipelines
Technology and data volumes change. Regularly audit your pipelines to ensure they are still as fast as they can be.
Real-Time DataOps vs Batch Data Processing
| Feature | Batch Processing | Real-Time DataOps |
| Speed | Slow (hours/days) | Instant (seconds/milliseconds) |
| Use Case | Historical Reporting | Live Operations |
| Complexity | Lower | Higher |
| Infrastructure | Simple | Specialized/Scalable |
Essential Technologies for Real-Time DataOps
Stream Processing Engines
Tools like Apache Flink or Kafka Streams that process events as they happen.
Cloud Data Platforms
Modern cloud warehouses that are built to handle both high-speed ingestion and complex queries.
Event Streaming Tools
Platforms that move massive volumes of event data reliably from producers to consumers.
Observability Tools
Dashboards that provide deep, real-time insights into the health of your pipelines.
Automation Frameworks
Tools that handle the CI/CD of data, ensuring that changes to pipeline code are tested and safe.
Career Opportunities in Real-Time DataOps
Required Skills
Focus on learning SQL, Python, distributed systems, and the fundamentals of data stream processing.
Job Roles in DataOps
Common roles include DataOps Engineer, Streaming Data Architect, and Platform Reliability Engineer.
Certifications and Learning Paths
Look for certifications in cloud data platforms and real-time streaming technologies to validate your expertise.
Learning Opportunities from TheDataOps.org
TheDataOps.org offers resources designed to help you bridge the gap between traditional data management and modern, real-time operations.
Future of Real-Time DataOps
AI-Driven Real-Time Pipelines
AI will monitor your pipelines and automatically tune them for better performance without human help.
Autonomous Data Systems
Systems will be able to detect and fix their own failures, leading to 100% uptime.
Predictive Streaming Analytics
Pipelines will not just report what is happening, but predict future outcomes based on live patterns.
Self-Healing Data Pipelines
When a part of the pipeline fails, it will re-route and self-repair instantly to keep the data flowing.
FAQ Section
1. Is real-time DataOps only for large companies?
No, while enterprises have complex needs, small businesses can use simplified real-time tools to improve their customer service.
2. Does DataOps replace data science?
No, DataOps provides the high-quality, reliable data foundation that data scientists need to do their work effectively.
3. Is real-time data always necessary?
Not always. Use it where speed matters, like fraud detection; use batch for long-term historical analysis.
4. What is the hardest part of implementation?
Changing the team culture to focus on automation and quality at every stage of the pipeline.
5. Do I need to be a programmer to use DataOps?
You need basic coding skills, but many modern tools have visual interfaces to help you build pipelines.
6. How do I measure success?
Look at your pipeline latency, error rates, and the time it takes to deploy new data features.
7. Is cloud infrastructure required?
Cloud is highly recommended because it offers the scalability and tools needed for real-time streams.
8. Can I start with my existing data?
Yes, you can incrementally add real-time streams alongside your batch processes.
9. What if my data source is unstable?
Real-time DataOps helps you implement “buffering” and retry logic to handle source instability gracefully.
10. How can I learn more?
TheDataOps.org provides structured guides and community support to help you get started.
Conclusion
By moving away from slow, manual processes and embracing automated, high-speed pipelines, organizations can transform their data into an immediate competitive advantage. The guidance provided by dedicated frameworks ensures that teams have the necessary expertise to implement these systems with precision, balancing speed with the highest standards of data integrity. As data volume and the demand for instant insights continue to grow, the ability to process information in real time will distinguish industry leaders. Consistently refining these operational processes is essential for long-term success, and continued commitment to structured implementation strategies will ensure that your data infrastructure remains resilient, scalable, and prepared for future demands.