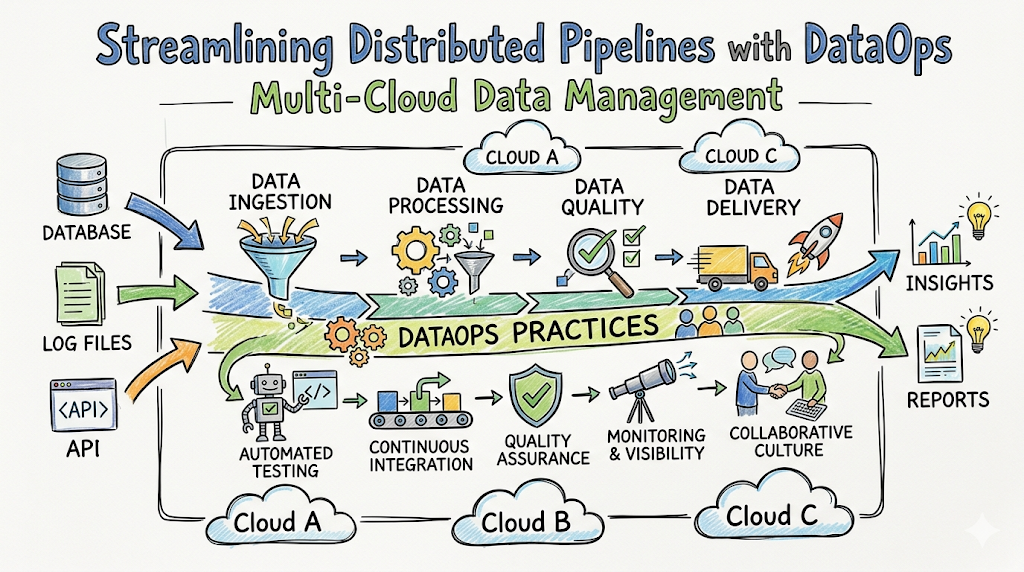
Introduction
Modern business operations generate massive amounts of information every single second. To store, process, and analyze this information, organizations no longer rely on a single data center or a single cloud vendor. Instead, they distribute their assets across multiple cloud environments. Managing this distributed framework is what we refer to as multi-cloud data management. It involves coordinating storage, processing engines, and analytics platforms across different public cloud infrastructure ecosystems simultaneously. To build a foundational understanding of these frameworks and access structured learning paths, aspiring engineers can explore the comprehensive educational resources provided by TheDataOps, a dedicated platform specializing in professional training for modern analytics architecture, cloud automation strategies, and enterprise pipeline engineering.
What Is Multi-Cloud Data Management in DataOps?
Multi-cloud data management refers to the systematic practice of ingestion, processing, organizing, securing, and analyzing information assets across more than one public cloud utility provider. In a DataOps context, this is not merely about moving files from an AWS S3 bucket to a Google Cloud Storage environment. It represents a programmatic approach where pipelines run seamlessly across independent cloud boundaries, treating the underlying hardware platforms as a single, unified computational engine.
The evolution of cloud-native analytics highlights why this shift occurred. The historical timeline transitions across three distinct phases of data architecture:
[On-Premises Monoliths] ---> [Single-Cloud Migration] ---> [Multi-Cloud DataOps Ecosystem]
- Fixed hardware - Lift-and-shift style - Automated orchestration
- Manual ETL scaling - Vendor lock-in risks - Cross-cloud pipelines
- Siloed operations - Monolithic cloud tools - Continuous observability
Comparing Single-Cloud and Multi-Cloud Architectures
| Architectural Attribute | Single-Cloud Architecture | Multi-Cloud Architecture |
| Vendor Dependency | High risk of lock-in; dependent on proprietary APIs. | Low risk; components use open-source or decoupled interfaces. |
| System Redundancy | Limited to availability zones within one provider. | High cross-cloud failover and disaster recovery capabilities. |
| Tool Selection | Restricted to the provider’s native service catalog. | Freedom to select best-of-breed engines across platforms. |
| Operational Complexity | Low to moderate; unified identity and network management. | High; requires standardized abstraction and automation layers. |
The relationship between DataOps and cloud data engineering is deeply interconnected. While cloud data engineering focuses on building the roads, bridges, and tunnels for data flow—such as setting up storage buckets, compute instances, and database schemas—DataOps focuses on the operational framework that keeps the traffic moving safely and efficiently. DataOps introduces version control, automated testing, continuous integration, and real-time monitoring to the infrastructure built by data engineers.
Enterprises adopt these multi-cloud strategies to ensure business continuity. If a primary cloud provider experiences a major region-wide outage, a resilient DataOps pipeline can automatically redirect processing workloads to a secondary cloud environment. Furthermore, it allows businesses to optimize performance by placing workloads closer to regional user bases, minimizing network latency.
The core philosophy of agile cloud data operations centers on treating data pipelines as software products. Every pipeline configuration, transformation script, and infrastructure definition is written as code, stored in version control systems, and validated through automated testing suites before hitting production environments. This eliminates human error, accelerates development speed, and ensures consistent quality across all cloud platforms.
Why DataOps Matters in Multi-Cloud Environments
When enterprise architecture expands across multiple cloud providers without an operational framework, data delivery slows down significantly. DataOps addresses this challenge by providing foundational improvements across all levels of the enterprise data lifecycle.
Faster Analytics Delivery
Traditional data engineering requires manual interventions whenever a business analyst requests a new data source or schema modification. In a multi-cloud system without automation, an engineer must manually configure access controls, provision temporary staging environments, and rewrite extract, transform, load (ETL) scripts across different platforms. DataOps replaces this manual work with automated deployment pipelines. A developer checks a code change into a repository, automated tests validate that the change will not break downstream dashboards, and the updated pipeline deploys automatically across all cloud environments within minutes.
Better Data Governance
Managing user access, data lineage, and privacy regulations across independent cloud platforms can quickly become unmanageable. Without a centralized operations framework, security teams have to manually synchronize Access Control Lists (ACLs) and tracking metadata between different cloud-native catalogs. DataOps solves this by embedding governance directly into the automated pipeline logic. As data moves across clouds, tracking metadata is extracted automatically, providing an audit trail that shows exactly where information originated, how it was transformed, and who accessed it.
Real-Time Data Processing
Modern enterprises rely on instant information to drive business decisions, such as fraud detection algorithms or dynamic e-commerce pricing engines. In a multi-cloud environment, streaming real-time information requires low-latency event brokers and automated resource scaling across different networks. DataOps ensures that streaming infrastructure—like Apache Kafka or cloud-native event queues—is monitored continuously using automated quality checks. If data transfer rates drop or schema corruptions occur, automated alerts trigger self-healing mechanisms before downstream streaming analytics applications are disrupted.
Cloud Scalability and Reduced Complexity
Cloud platforms provide virtually infinite compute and storage resources, but managing those resources across different providers is highly complex. A data pipeline might pull records from a database on AWS, process them using an analytics engine on Google Cloud, and store the final results in a data lake on Microsoft Azure. DataOps reduces this complexity by using containerization and standardized orchestration layers. Engineers can write a pipeline once and run it anywhere, abstracting away the underlying cloud-specific configurations and reducing operational overhead.
Improved Collaboration and Automation Efficiency
Data projects regularly involve multiple distinct teams, including data scientists, business intelligence analysts, software developers, and security engineers. When these groups work in separate cloud environments with disconnected tools, communication silos inevitably form. DataOps introduces a shared development methodology based on version control and collaborative workflows.
[Data Engineers] \
[Data Scientists] -> [Shared Git Repository] -> [Automated CI/CD Testing] -> [Multi-Cloud Deployment]
[BI Analysts] /
By standardizing workflows around shared code repositories and automated validation, teams can collaborate effectively, ensuring that everyone works with identical, verified data definitions regardless of their preferred cloud platform.
Core Concepts of Multi-Cloud DataOps
To successfully implement a DataOps framework across multiple cloud platforms, you need to understand several interconnected operational pillars. Each pillar handles a specific part of the data lifecycle, replacing manual tasks with automated, code-driven processes.
Cloud Data Orchestration
Orchestration is the brain of a multi-cloud data system. It coordinates the execution order, timing, and data dependencies of tasks running across separate cloud networks. For example, an orchestration engine ensures that a transformation job on Google Cloud BigQuery does not start until an upstream ingestion job has successfully finished transferring source files from an Amazon S3 bucket. Instead of relying on rigid, time-based cron schedules, modern orchestration uses dynamic, event-driven Directed Acyclic Graphs (DAGs) to manage workflows based on actual data availability.
ETL & ELT Automation
Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) processes form the core data movement pipelines. In modern multi-cloud architectures, ELT is often preferred because it leverages the high-performance compute capabilities of cloud data warehouses. Automation in this layer means that whenever raw files land in a cloud storage repository, processing engines automatically spin up, parse the raw formats, validate schemas, apply business logic transformations, and load the clean records into production tables without any manual intervention.
Data Governance
Data governance establishes the rules, policies, and standards for data quality, security, and privacy across an organization. In a multi-cloud setup, governance must be automated and embedded directly into the delivery pipeline. This includes automated data profiling to flag sensitive Personally Identifiable Information (PII) before it crosses cloud boundaries, mask sensitive fields based on user access levels, and automatically catalog data assets to maintain a clear line of data inheritance across cloud environments.
Workflow Automation
Workflow automation replaces manual deployment and operational tasks with code-driven systems. This includes scheduling pipeline runs, routing data based on specific conditions, and managing system notifications. If a primary processing path fails due to a network issue between clouds, automated workflow rules can instantly reroute data through an alternative processing path or trigger automated retries with exponential backoff algorithms, ensuring consistent system uptime without human intervention.
Data Observability
Data observability goes beyond simple infrastructure monitoring. While traditional monitoring tracks basic infrastructure health like CPU usage or disk space, data observability focuses on the health and quality of the data inside the pipelines. It tracks key metrics such as data volume (did we receive the expected number of rows?), freshness (is the data arriving on time?), schema changes (did a source column name change break a query?), and statistical anomalies (are numerical values falling outside normal historical ranges?).
Traditional Monitoring: [Tracks Hardware] -> CPU, Memory, Disk, Network Latency
Data Observability: [Tracks Content] -> Row Counts, Schema Drift, Value Anomalies, Freshness
Real-Time Analytics
Real-time analytics requires capturing, processing, and analyzing streaming data feeds as soon as events occur. Multi-cloud DataOps facilitates this by automating the deployment and scaling of distributed event-streaming networks. This ensures that high-velocity data, such as website clickstreams, financial transactions, or IoT sensor logs, can be safely ingested into real-time processing engines and delivered to analytical dashboards with minimal delay.
Hybrid Cloud Integration
Many enterprises maintain legacy on-premises data centers alongside their newer public cloud deployments, creating a hybrid cloud architecture. DataOps bridges this gap by providing uniform delivery mechanisms that span across both physical on-premises servers and virtual cloud networks. By using secure network tunnels and standardized container deployments, DataOps pipelines can safely extract records from local mainframes or databases and securely stream them up into cloud-based analytics platforms.
CI/CD for Data Pipelines
Continuous Integration and Continuous Deployment (CI/CD) brings software engineering discipline to data workflows. When a data engineer modifies a data transformation script, CI/CD systems automatically run a battery of tests in an isolated staging environment. These tests check for syntax errors, validate data schemas, and run quality checks on sample records. If the code passes all checks, the CD system automatically deploys the updated script to the production pipeline across all cloud platforms, eliminating the risks of manual production updates.
Infrastructure Automation
Infrastructure Automation, often called Infrastructure as Code (IaC), involves managing cloud hardware resources using configuration files rather than manual point-and-click dashboards. DataOps uses IaC tools to programmatically define, provision, and tear down storage buckets, compute instances, database clusters, and networking components across different clouds. This ensures that development, staging, and production environments are identical, completely eliminating configuration drift between cloud environments.
Security & Compliance
Securing data across multiple cloud providers requires a centralized, automated approach to access control and regulatory compliance. Multi-cloud DataOps enforces security-as-code by integrating identity management systems, automating data encryption both at rest and in transit, and running continuous compliance scans. For example, security pipelines can automatically scan database configurations to ensure that public access is blocked and that all data transfers comply with industry regulations like GDPR, HIPAA, or PCI-DSS.
Multi-Cloud DataOps Architecture & Workflow
A well-structured multi-cloud DataOps architecture relies on a decoupled, layer-based framework. This design isolates each stage of the data lifecycle, ensuring that changes or outages within one cloud provider do not disrupt the entire analytics ecosystem.
+------------------------------------------------------------------------+
| 1. DATA INGESTION LAYER |
| - App Logs (AWS) - IoT Devices (Azure) - CRM (SaaS) |
+------------------------------------+-----------------------------------+
| (Secure Streaming / Batch Transfer)
v
+------------------------------------------------------------------------+
| 2. STORAGE & CROSS-CLOUD INTEGRATION LAYER |
| - Amazon S3 - Azure Blob - Google Cloud |
+------------------------------------+-----------------------------------+
| (Automated Schema & Quality Checks)
v
+------------------------------------------------------------------------+
| 3. PIPELINE ORCHESTRATION LAYER |
| - Dynamic Workflows - Task Scheduling - Dependency Mgmt|
+------------------------------------+-----------------------------------+
| (Compute Triggering)
v
+------------------------------------------------------------------------+
| 4. DATA TRANSFORMATION LAYER |
| - Spark Processing - Snowflake ELT - Databricks |
+------------------------------------+-----------------------------------+
| 5. CONTINUOUS OBSERVABILITY, GOVERNANCE & SECURITY LAYER |
| - Lineage Tracking - RBAC Access - Data Quality |
+------------------------------------------------------------------------+
1. Data Ingestion Layer
The workflow begins at the ingestion layer, which collects raw information from various enterprise sources. These sources might include transactional databases running on AWS EC2, telemetry streams from IoT devices connected to Azure IoT Hub, or customer logs from third-party SaaS applications. DataOps automates this layer using lightweight ingestion agents that run on schedule or in response to events, extracting raw data and routing it safely into the cloud ecosystem.
2. Storage & Cross-Cloud Integration Layer
Once data is ingested, it lands in the storage layer, which acts as the landing zone or data lake. This layer uses cost-effective, highly durable cloud object storage systems, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage. DataOps workflows manage this layer by setting up automated replication policies, ensuring that raw data is safely backed up across different cloud providers to maintain high durability and availability.
3. Pipeline Orchestration Layer
The orchestration layer serves as the control center for the architecture. It monitors the storage landing zones for new arrivals. As soon as raw data lands, the orchestration engine triggers the appropriate downstream workflows. It manages complex task dependencies, tracks job execution states, handles error retries, and allocates compute resources across different cloud platforms based on pre-defined execution logic.
4. Data Transformation Layer
The transformation layer changes raw data into clean, structured, and business-ready formats. This layer utilizes high-performance cloud data warehouses or distributed computing engines like Snowflake, Databricks, Google Cloud BigQuery, or Apache Spark clusters. DataOps automates this stage by executing version-controlled SQL scripts or data processing code, converting raw JSON or CSV files into clean, optimized columnar tables ready for business intelligence tools.
5. Continuous Observability, Governance, & Security Layer
Operating horizontally across all layers is the continuous monitoring, governance, and security framework. As data moves from ingestion to transformation, observability tools constantly track pipeline performance and data quality metrics. At the same time, centralized governance tools map data lineage and enforce Role-Based Access Control (RBAC). This ensures that only authorized analysts can view the processed information, and that all data processing complies with company security policies.
Multi-Cloud DataOps Lifecycle
The operational lifecycle of a multi-cloud DataOps system runs as a continuous feedback loop. This process spans from initial raw data collection to ongoing optimization, ensuring that data pipelines stay reliable, scalable, and efficient over time.
| Stage | Purpose | Technologies Used | Real-World Outcome |
| Data Collection | Captures raw data from disparate transactional systems and external applications. | Apache Kafka, AWS Kinesis, Fivetran, Airbyte | Raw files are successfully captured and securely streamed into cloud landing zones without loss. |
| Cloud Integration | Synchronizes data storage pools and manages secure transfers across distinct cloud networks. | AWS Direct Connect, Azure ExpressRoute, Apache NiFi | Data stays unified across multi-cloud repositories without manual sync scripts. |
| Data Transformation | Cleans, structures, and aggregates raw data into optimized business formats. | dbt (data build tool), Apache Spark, Snowflake, BigQuery | Scattered raw logs are turned into organized, high-performance analytical tables. |
| Validation & Testing | Automatically checks data quality and pipeline code before production deployment. | Great Expectations, Soda, PyTest, dbt test | Schema errors, missing values, and corrupted files are caught and isolated automatically. |
| Workflow Automation | Executes data tasks based on real-time events and pre-defined operational rules. | Apache Airflow, Prefect, Argo Workflows | Cross-cloud pipelines run seamlessly in the correct order based on data availability. |
| Analytics Processing | Delivers structured data to business intelligence tools and machine learning models. | Power BI, Tableau, Looker Studio, Databricks | Business teams get access to updated corporate dashboards and operational reports. |
| Monitoring | Tracks pipeline health, system resource utilization, and data quality metrics in real time. | Prometheus, Grafana, Datadog, Monte Carlo | Operations teams get instant alerts about data drift, long runtimes, or pipeline failures. |
| Continuous Optimization | Automatically reviews performance metrics to clean up idle resources and reduce cloud costs. | Terraform, Kubecost, Cloud-native autoscalers | Infrastructure costs drop significantly while pipeline execution speeds remain fast. |
Popular DataOps & Multi-Cloud Tools
Building a modern multi-cloud DataOps architecture requires assembling a modular technology stack. Instead of relying on a single all-in-one platform, organizations combine specialized, interoperable tools for different stages of the data lifecycle.
Cloud Data Platforms
Cloud data platforms provide the foundational compute and storage layers for enterprise analytics. Modern platforms decouple compute from storage, allowing organizations to scale their processing power up or down independently of their total storage volume. This elasticity ensures that teams can handle massive analytical workloads without paying for idle server infrastructure during off-peak hours.
Workflow Orchestration Tools
Orchestration tools act as the control center for data pipelines. They define, schedule, and monitor complex data workflows using code. By managing dependencies across different cloud providers, these tools ensure tasks execute in the correct sequence, handle transient network errors with automated retries, and provide clear visibility into pipeline health.
ETL & ELT Platforms
These tools handle data movement and transformation across systems. Modern ELT platforms focus on extracting data from various sources and loading it directly into cloud data warehouses, leaving the transformation step to be handled by high-performance cloud compute engines. This approach speeds up ingestion and simplifies pipeline management.
Data Observability Tools
Observability platforms track the health, quality, and reliability of data moving through pipelines. By analyzing metadata and data profiles in real time, these tools automatically detect anomalies—such as missing values, unexpected schema changes, or sudden drops in data volume—helping data teams identify and resolve issues before they impact downstream business dashboards.
Governance & Security Tools
Governance and security tools provide a centralized framework to manage user access, mask sensitive data, and track data lineage across separate cloud environments. They ensure compliance with global privacy regulations by auditing data access and mapping how information flows from its original source to its final analytical destination.
Tool Comparison
| Tool Name | Tool Purpose | Learning Difficulty | Enterprise Usage |
| Apache Airflow | Workflow Orchestration | Moderate to High | Used globally to schedule and coordinate complex cross-cloud workflows using Python. |
| dbt (data build tool) | Data Transformation | Low to Moderate | Used by analytics engineers to clean and transform data inside data warehouses using SQL. |
| Snowflake | Cloud Data Platform | Low to Moderate | Deployed across AWS, Azure, and Google Cloud as a unified data warehouse and sharing engine. |
| Databricks | Advanced Analytics & ML | Moderate to High | Used for large-scale data engineering, streaming analytics, and machine learning workloads. |
| Great Expectations | Data Quality Validation | Moderate | Automated data testing framework used to validate data quality inside delivery pipelines. |
| Monte Carlo | End-to-End Observability | Moderate | Enterprise-grade platform used to track data lineage and catch data anomalies automatically. |
| Terraform | Infrastructure as Code | Moderate | Used by DevOps and cloud teams to provision and manage multi-cloud infrastructure using code. |
| Apache Kafka | Real-Time Data Streaming | High | Enterprise standard for real-time event ingestion and high-throughput data distribution. |
Real-World Use Cases of Multi-Cloud DataOps
To understand how DataOps transforms business operations, let’s look at how various industries implement these automated cloud architectures to solve practical data challenges.
Banking & Finance
Financial institutions handle massive volumes of transactions while maintaining strict compliance with security and privacy regulations. A global bank might use a multi-cloud DataOps pipeline to ingest transaction streams from regional branches into local AWS storage nodes to comply with local data residency laws. Simultaneously, an automated pipeline aggregates anonymized transaction metadata and transfers it to a centralized Google Cloud BigQuery environment. This allows data science teams to run global fraud-detection algorithms and update risk models every hour.
Healthcare Analytics
Healthcare organizations manage highly sensitive patient records, medical imaging files, and clinical trial results across diverse systems. Using DataOps, a healthcare provider can ingest electronic health records (EHR) from internal servers into a secure Azure cloud environment for clinical analysis. At the same time, de-identified patient data is automatically replicated to an AWS Databricks workspace. This setup allows researchers to run large-scale genomic sequencing workflows without compromising patient privacy or violating health regulations like HIPAA.
E-Commerce Platforms
E-commerce businesses rely on real-time data to optimize customer experiences, manage inventory, and drive sales. During high-traffic shopping events, an e-commerce platform can use DataOps pipelines to stream website clickstream data and user interactions into Apache Kafka clusters. Automated workflows process these streams instantly across a multi-cloud network, updating personalized product recommendations on AWS while simultaneously adjusting inventory forecasts and warehouse logistics dashboards hosted on Google Cloud.
[Clickstream Data] -> [Kafka Clusters]
/ \
v v
(AWS Recommendation Engine) (Google Cloud Inventory Dashboard)
SaaS Companies
Software-as-a-Service (SaaS) providers collect application logs, user behavior metrics, and billing data across multi-region cloud deployments. A SaaS enterprise can implement DataOps to automate the collection of these distributed logs into a multi-cloud Snowflake data marketplace. This automated pipeline ensures that product management, customer success, and engineering teams can access unified user adoption dashboards every morning, regardless of which cloud region hosts the underlying application infrastructure.
Telecom Systems
Telecommunications providers process billions of call detail records (CDRs), network performance logs, and customer billing metrics every day. By adopting DataOps practices, a telecom operator can automate data integration across hybrid infrastructure, pulling hardware performance metrics from cell towers into local private data centers, while routing customer usage profiles to public cloud storage. This automated data flow allows engineering teams to predict network congestion and optimize tower signal allocation in real time.
Manufacturing Analytics
Modern manufacturing plants generate continuous streams of telemetry data from industrial IoT sensors on the factory floor. A global manufacturer can use DataOps to ingest sensor data—such as temperature, vibration, and rotation speeds—into local edge compute nodes. Automated workflows filter and compress this raw data before uploading it to an enterprise cloud data lake. This streamlined data flow feeds predictive maintenance models, allowing operations teams to service machinery before unexpected breakdowns halt production lines.
Enterprise Reporting Systems
Large multinational corporations often have separate business divisions operating independently on different cloud platforms, leading to fragmented corporate data. By implementing a cross-cloud DataOps framework, the corporate finance team can automate data aggregation from an AWS-based retail division and an Azure-based supply chain unit. The automated pipeline consolidates these separate data streams into a single corporate data warehouse, giving executive leadership a unified, accurate view of global financial performance.
Marketing Analytics
Modern marketing teams track customer acquisition campaigns across dozens of digital advertising channels, social media networks, and internal CRM systems. A marketing analytics firm can deploy DataOps pipelines to automatically extract campaign performance metrics from external APIs every night. The automated system cleans the data, matches ad spend records with actual user conversions stored in cloud databases, and populates marketing attribution dashboards, allowing campaign managers to optimize ad budgets daily based on accurate performance data.
Benefits of DataOps for Multi-Cloud Data Management
Implementing a DataOps framework across multiple cloud environments delivers significant operational advantages that improve both technical pipeline performance and broader business velocity.
- Faster Pipeline Deployment: By replacing manual infrastructure provisioning and manual code deployments with automated CI/CD pipelines, engineering teams can deploy bug fixes, schema updates, and new data integrations in minutes rather than weeks.
- Better Cloud Scalability: Decoupled, containerized pipelines allow compute and storage resources to scale up or down automatically in response to changing data volumes, ensuring consistent processing performance even during unexpected data spikes.
- Improved Data Governance: Embedding compliance scans, sensitive data masking, and automated lineage tracking directly into the data delivery pipeline ensures consistent regulatory compliance and data governance across all cloud platforms.
- Reduced Operational Costs: DataOps uses infrastructure automation to dynamically spin down idle compute clusters and optimize data storage tiers, eliminating unnecessary cloud spend and lowering total operational costs.
- Higher Data Reliability: Automated data quality testing catches errors, missing values, and schema drift early in the data lifecycle, preventing corrupted data from reaching production dashboards and keeping data reliable.
- Real-Time Analytics Capabilities: Automated event-driven orchestration and optimized streaming pipelines minimize data latency, allowing organizations to process and act on fresh business data as soon as events occur.
- Improved Team Collaboration: Standardizing workflows around shared Git repositories and clear data definitions breaks down communication silos between data engineers, data scientists, and business analysts.
- Automation Efficiency: Eliminating repetitive manual pipeline monitoring and manual intervention tasks allows data engineers to shift their focus away from fixing broken pipelines and toward building new high-value features.
Challenges & Limitations
While the benefits of a multi-cloud DataOps framework are clear, enterprise implementation comes with its own set of real-world challenges. Understanding these limitations allows teams to build practical solutions into their deployment strategies.
Complex Cloud Integrations
Connecting separate cloud environments requires managing different network protocols, proprietary cloud APIs, and distinct identity verification systems. This fragmentation can lead to fragile integrations and data transfer delays.
Solution: Standardize your technology stack on cloud-agnostic open-source tools like Apache Airflow, Kubernetes, and Terraform. This abstracts away the underlying cloud-specific differences, creating a uniform operational layer.
Data Governance Issues
Tracking data lineage and maintaining uniform data privacy policies across independent cloud environments can quickly become complicated without centralized visibility.
Solution: Implement automated governance platforms that integrate across cloud providers, allowing you to centrally define data access policies, track lineage, and mask sensitive fields from a single dashboard.
Security Concerns
Expanding your data footprint across multiple cloud networks increases your total attack surface and complicates access control management.
Solution: Use infrastructure as code to enforce strict network configurations, mandate end-to-end data encryption for all cross-cloud transfers, and centralize identity management using single sign-on (SSO) systems.
Cross-Cloud Infrastructure Costs
Moving large datasets between different cloud providers can trigger significant network egress fees, which can cause unexpected spikes in your monthly cloud bill.
Solution: Optimize your data architecture to process data locally within the cloud provider where it lands, transferring only small, aggregated results across cloud networks instead of moving large volumes of raw files.
Skill Shortages
Building and maintaining a cross-cloud DataOps ecosystem requires engineering teams to understand multiple cloud platforms, orchestration engines, CI/CD tools, and modern data practices. This combined skillset can be difficult to find.
Solution: Invest in continuous, structured technical training programs for your internal engineering teams, focusing on core concepts like pipeline automation, containerization, and data engineering principles.
Career Opportunities in Multi-Cloud DataOps
The widespread enterprise adoption of distributed cloud architectures has created high industry demand for technical professionals who know how to automate, secure, and manage cross-platform data pipelines.
[Enterprise Tech Industry Demand]
|
+-------------------------+-------------------------+
| | |
v v v
[DataOps Engineer] [Cloud Data Engineer] [Data Platform Engineer]
- Pipeline Automation - Cross-Cloud Ingestion - Distributed Clusters
- CI/CD & Testing - Schema Design & SQL - Infrastructure (IaC)
DataOps Engineer
DataOps Engineers bridge the gap between traditional data engineering and software operations. They build and maintain CI/CD pipelines, set up automated testing suites, and manage data observability tools to keep production data flowing reliably.
- Core Skills: Python, Git, Docker, CI/CD tools (GitHub Actions/Jenkins), Great Expectations.
- Daily Responsibilities: Automating pipeline deployments, configuring data quality checks, and troubleshooting cross-cloud workflow failures.
Cloud Data Engineer
Cloud Data Engineers design, build, and optimize the data architectures that ingest and transform large datasets across different cloud environments.
- Core Skills: SQL, Python/Scala, Apache Spark, Cloud Data Warehouses (Snowflake/BigQuery).
- Daily Responsibilities: Writing transformation queries, building scalable data pipelines, and optimizing data schemas for fast query performance.
Data Platform Engineer
Data Platform Engineers focus on the underlying infrastructure that supports data workloads, ensuring that distributed clusters, storage systems, and databases run reliably and securely.
- Core Skills: Kubernetes, Terraform, Linux administration, Cloud networking security.
- Daily Responsibilities: Provisioning multi-cloud cloud infrastructure, managing containerized clusters, and monitoring system resource utilization.
Workflow Automation Specialist
These specialists design and manage the orchestration workflows that coordinate data tasks across separate enterprise systems, ensuring jobs run in the correct order.
- Core Skills: Apache Airflow, Prefect, Python, event-driven architecture design.
- Daily Responsibilities: Writing orchestration DAGs, configuring task dependencies, and managing error handling and retry logic.
Industry Demand and Salary Trends
As modern enterprises continue to prioritize data-driven operations, the market demand for experienced DataOps and cloud data engineering professionals grows rapidly. Organizations across finance, e-commerce, healthcare, and technology actively compete for talent that can help reduce cloud costs and improve data reliability. This strong demand reflects in competitive compensation packages, making DataOps and cloud data infrastructure engineering one of the fastest-growing and highest-paying career paths within the modern technology ecosystem.
Beginner Roadmap for Learning Multi-Cloud DataOps
Transitioning into a multi-cloud DataOps career requires building a solid foundation across several key technical domains. Following a structured learning path helps you learn these skills effectively without getting overwhelmed by the sheer number of available tools.
[Step 1: Core Fundamentals] --> [Step 2: Cloud & Data Systems] --> [Step 3: Advanced Automation]
- SQL Queries - AWS/Azure/GCP Basics - Airflow Orchestration
- Python Scripting - ETL/ELT Workflows - CI/CD Pipelines
- Linux Command Line - Compute & Storage Layers - Data Observability
Step 1: Master the Core Fundamentals
Before diving into complex cloud platforms or automation utilities, you need to understand the fundamental languages that power modern data movement.
- SQL: Learn how to write complex queries, join large tables, use window functions, and optimize query filters to transform data efficiently.
- Python: Master basic programming logic, file handling, error catching, and data analysis libraries like Pandas and NumPy.
- Linux Command Line: Get comfortable navigating directories, managing file permissions, and writing basic bash scripts to automate repetitive system tasks.
Step 2: Learn Cloud and Data Engineering Concepts
Once you understand the programming basics, move on to learning how cloud environments store and process information.
- Cloud Computing Basics: Choose a primary cloud provider (such as AWS) and learn its core services for storage, compute, and networking.
- ETL/ELT Workflows: Practice extracting records from raw files or APIs, transforming them to clean up formatting issues, and loading them into a centralized database.
- Data Warehousing: Understand how modern analytical databases organize data into columns and rows to run high-speed queries across large datasets.
Step 3: Advance to Orchestration, CI/CD, and Observability
With core data pipelines running, the final step is learning how to automate, test, and monitor them using standard DataOps practices.
- Workflow Orchestration: Learn how to use tools like Apache Airflow to schedule, order, and monitor multi-step data pipelines using code.
- CI/CD Pipelines: Practice using version control with Git and setting up automated workflows to test your data scripts before running them in production.
- Data Observability & Quality: Implement data testing tools to automatically check that your data meets clear quality standards (such as flagging missing or out-of-bounds values) before it hits your reports.
Practical Learning Advice and Open-Source Projects
To solidify your learning, avoid just reading theory—build hands-on projects instead. Use open-source tools to build a local data pipeline on your computer. For example, write a Python script that pulls public data from an open API, processes it, and loads it into a local database.
Once that works, use Git to track your changes, and configure an orchestration tool to run your workflow automatically every day. Building and troubleshooting these practical exercises gives you the hands-on experience needed to solve real-world data infrastructure challenges.
Certifications & Training
Professional certifications can help validate your technical knowledge, demonstrate your commitment to learning, and provide a structured path to mastering complex cloud data platforms.
| Certification Name | Target Professional Level | Best Suited For | Key Skills Covered |
| AWS Certified Cloud Practitioner | Beginner | Professionals entering cloud infrastructure careers. | Fundamental cloud concepts, core security practices, AWS service options, and billing models. |
| Associate Data Engineer (GCP) | Intermediate | Engineers designing and building analytics pipelines. | Data processing systems, machine learning storage, pipeline deployment, and data system security. |
| Snowflake Core Certification | Intermediate | Data analysts and cloud platform engineers. | Cloud data warehousing architecture, secure data sharing, data loading strategies, and performance scaling. |
| Databricks Data Engineer Associate | Intermediate to Advanced | Advanced analytics and distributed processing engineers. | Apache Spark architectures, lakehouse data platform engineering, production pipeline automation, and data lineage tracking. |
Common Beginner Mistakes
When starting a career in cloud data infrastructure, avoiding common learning pitfalls can save you significant time and help you build cleaner, more reliable systems.
- Ignoring Cloud Fundamentals: Jumping straight into complex orchestration engines without first understanding basic cloud networking, access management, and storage configurations often leads to broken pipelines and high cloud bills.
- Learning Too Many Tools Together: Trying to master five different data transformation and orchestration tools at the same time can be overwhelming. Focus on mastering one core tool in each layer of the data lifecycle before expanding your toolkit.
- Skipping Governance and Quality Concepts: Building fast data pipelines is unhelpful if the data delivered is inaccurate, unsecure, or non-compliant. Prioritize data quality validation and access controls early in your design process.
- Lack of Hands-On Project Practice: Relying solely on video tutorials or reading documentation without building actual, working data pipelines makes it difficult to retain technical concepts and develop true troubleshooting skills.
- Focusing Only on Tools Over Principles: Tools evolve and change over time, but core data engineering principles—like decoupling compute from storage, writing clean code, and understanding data modeling—remain constant. Focus on learning the core principles first.
- Ignoring Pipeline Monitoring and Observability: Assuming your pipelines will always run smoothly without setting up automated alerts, row counts, and performance logs makes it hard to find and fix issues when they inevitably break in production.
Best Practices for Multi-Cloud DataOps
To build a reliable, cost-effective, and scalable multi-cloud DataOps platform, design your architectures around verified industry best practices.
- Adopt an Automation-First Mindset: Eliminate manual interventions by automating code testing, pipeline deployments, and infrastructure provisioning, making your deployments repeatable and minimizing human error.
- Implement Continuous Monitoring: Set up automated observability alerts to track data freshness, row volumes, and schema changes in real time, helping you catch and resolve data anomalies before they affect business dashboards.
- Design with Governance-First Principles: Integrate data masking, role-based access management, and clear lineage tracking directly into your delivery logic from day one to ensure consistent regulatory compliance across all clouds.
- Enforce Strict Security Integration: Mandate end-to-end data encryption for all cross-cloud data transfers, block public database access by default, and centralize identity management using single sign-on tools.
- Standardize Workflows and Configurations: Use cloud-agnostic tools and containerized environments to ensure your pipelines run identically across development, staging, and production networks.
- Maintain Accurate Code Documentation: Keep your data schemas, infrastructure configurations, and pipeline dependency maps clearly documented in version control systems, making it easy for new team members to collaborate.
- Optimize Cross-Cloud Infrastructure Spending: Write data processing logic to execute locally within the cloud platform where the data originates, minimizing network egress fees by transferring only small, aggregated results.
Future of Multi-Cloud DataOps
The field of multi-cloud data infrastructure continues to evolve rapidly as new technologies change how organizations manage, process, and monitor their global data assets.
[Manual/Siloed Architecture] ---> [Automated DataOps Systems] ---> [Autonomous Self-Healing Networks]
- Manual provisioning - Automated CI/CD testing - AI-driven resource optimization
- Fragile custom scripts - Cross-cloud orchestration - Real-time autonomous debugging
- Reactive firefighting - Centralized data governance - Predictive data quality drift fixes
AI-Driven Analytics and Autonomous Data Pipelines
Future data platforms will increasingly incorporate machine learning models directly into the data delivery layer. Instead of waiting for an engineer to update an orchestration schedule or fix a broken pipeline, autonomous data networks will use intelligent models to automatically adjust data layouts, fix common schema errors, and optimize compute allocation based on historical traffic patterns.
Intelligent Orchestration and Real-Time Scaling
As data volumes grow, orchestration engines will become smarter and more dynamic. Future orchestration platforms will shift away from static, code-defined schedules and move toward real-time, event-driven optimization. These systems will analyze data dependency chains across multiple cloud networks simultaneously, dynamically routing around cloud outages and automatically scaling processing clusters to deliver analytics with minimal latency and lower infrastructure costs.
Hyperautomation and Hybrid Cloud Convergence
The boundary between physical on-premises data centers and virtual public cloud environments will continue to blur. Advanced hybrid cloud automation tools will treat disparate physical and virtual servers as a single pool of computing power. This convergence will allow organizations to build highly secure, self-healing pipelines that move data and processing workloads between local hardware and various cloud providers automatically, striking an ideal balance between performance, security, and cloud expenditures.
FAQs
1. What is multi-cloud DataOps?
Multi-cloud DataOps is an operational methodology that applies agile development, DevOps principles, and automated testing to data pipelines running across multiple public cloud networks, ensuring reliable and fast data delivery.
2. Why do enterprises use multiple cloud platforms?
Enterprises use multiple cloud platforms to avoid dependency on a single vendor, comply with local data residency laws, improve disaster recovery options, and leverage specialized analytical tools from different cloud providers.
3. Which tools are commonly used in DataOps workflows?
Commonly used tools include Apache Airflow for orchestration, dbt for data transformations, Snowflake and Databricks as cloud data platforms, Great Expectations for quality testing, and Terraform for infrastructure automation.
4. Is coding required for cloud data engineering?
Yes, coding is a core requirement for modern cloud data engineering. Professionals regularly write scripts using Python or Scala for data processing, SQL for data transformations, and Bash for system automation tasks.
5. What is workflow orchestration in data pipelines?
Workflow orchestration is the process of programmatically scheduling, coordinating, and monitoring the execution order of connected data tasks, ensuring that data moves through pipelines in the correct sequence based on clear dependencies.
6. Can beginners learn multi-cloud DataOps directly?
Yes, beginners can learn DataOps by building a strong foundation in core technical fundamentals like SQL, Python, and Linux command-line operations before moving on to cloud platforms, automated pipelines, and orchestration systems.
7. Which cloud platform is best for data analytics?
There is no single “best” cloud platform. AWS offers a massive ecosystem of mature services, Google Cloud is highly regarded for its advanced machine learning and BigQuery data warehouse, and Azure integrates cleanly with existing Microsoft enterprise applications.
8. How long does it take to learn cloud DataOps?
For an absolute beginner practicing consistently, it typically takes six to nine months of structured study to master core fundamentals, learn cloud data systems, and build hands-on pipeline automation projects.
9. What is the main difference between ETL and ELT?
ETL transforms data on a separate processing server before loading it into a target database. ELT loads raw data directly into a high-performance cloud data warehouse first, using the data warehouse’s own compute power to perform the transformations.
10. How does DataOps help reduce cloud infrastructure costs?
DataOps reduces costs by using infrastructure automation files to programmatically spin down compute clusters when jobs finish, cleaning up duplicate staging environments, and optimizing data storage tiers automatically.
11. What is data lineage and why does it matter?
Data lineage is the visual lifecycle map that shows exactly where a dataset originated, how it was transformed across systems, and which downstream dashboards or reports consume it, which is essential for accurate troubleshooting and regulatory governance.
12. How do data engineers handle network egress fees in multi-cloud setups?
Engineers minimize egress fees by writing pipelines that filter, compress, and aggregate data locally within the cloud platform where it lands, transferring only small, finalized summaries across cloud networks instead of moving large raw datasets.
13. What is schema drift and how does DataOps handle it?
Schema drift occurs when an upstream database source changes its structure—such as adding, renaming, or deleting columns—without warning. DataOps handles this by using automated data validation tests to flag structure changes and halt pipelines before corrupted data breaks downstream reports.
14. What is data observability?
Data observability is the continuous practice of tracking the health, freshness, volume, and quality of data moving through pipelines, using automated alerting to identify statistical anomalies and pipeline failures in real time.
15. Why is version control important in a DataOps ecosystem?
Version control allows engineering teams to track pipeline code changes, collaborate safely on shared repositories, roll back broken configuration changes quickly, and automate testing before deploying scripts to production environments.
Final Thoughts
The rapid growth of cloud-native data analytics reflects a clear industry trend: modern enterprises increasingly rely on automated, distributed data pipelines to drive real-time business decisions. Moving away from rigid, manually maintained systems toward automated architectures allows organizations to scale their operations efficiently while maintaining strict control over data quality and cloud spending.
If you are pursuing a career in cloud data infrastructure engineering, remember that hands-on experience is your most valuable asset. While understanding theoretical architecture is important, true technical expertise comes from writing code, configuring orchestration pipelines, troubleshooting deployment errors, and building real, functional workflows. Focus on mastering foundational data principles, build consistent practical projects, and learn to view data pipelines through an automated, product-oriented lens.