Data has become the primary asset of the modern enterprise, but it is also the most vulnerable. As organizations migrate from static data warehouses to distributed, real-time data ecosystems, the pathways through which data flows have grown incredibly complex. Data pipelines now stretch across multi-cloud environments, stream data from thousands of IoT devices, and feed complex machine learning models. To bridge this gap, organizations are turning to DataOps. By merging data engineering, operations, and quality assurance into a continuous, automated lifecycle, DataOps changes how we approach data protection. It embeds security directly into the fabric of the data lifecycle rather than treating it as an external wrapper. For comprehensive frameworks and deep dives into building robust data architectures, platforms like TheDataOps offer essential guidance on aligning operational agility with enterprise-grade protection. Implementing DataOps security in pipelines ensures that compliance, access control, and anomaly detection are fully automated. This methodology eliminates reliance on manual checklists, reducing human error and allowing organizations to scale their data infrastructure without exposing sensitive assets to emerging cyber threats.
What is DataOps?
DataOps is an agile, operations-focused methodology designed to improve the quality, speed, and accuracy of data analytics. Inspired by the success of DevOps in software engineering, DataOps combines statistical process control, agile development, and automated workflows to streamline the entire data lifecycle. It focuses on breaking down the traditional silos between data engineers, data scientists, analysts, and operations teams.
At its core, DataOps views data pipelines as manufacturing assembly lines. Raw inputs enter at one end, undergo a series of transformations, and emerge as high-value analytics or machine learning features at the other. Statistical process control monitors this line in real-time, catching defects before they reach consumers.
+--------------------------------------------------------------------------+
| DATAOPS |
| +-------------------+ +--------------------+ +------------------+ |
| | AGILE | | DEVOPS | | STATISTICAL | |
| | DEVELOPMENT | + | CI/CD automation | + | PROCESS CONTROL | |
| | (Rapid Iteration) | | & Infrastructure | | (Quality/Safety) | |
| +-------------------+ +--------------------+ +------------------+ |
+--------------------------------------------------------------------------+
By prioritizing automation and continuous integration and continuous deployment (CI/CD), DataOps minimizes the friction associated with manual deployments. Data engineers use version control for code, data schemas, and infrastructure configurations, ensuring that all changes are auditable, repeatable, and testable.
In modern data engineering, DataOps provides the foundational framework needed to manage complex data estates. It shifts the organization from reactive firefighting to proactive management, ensuring data delivery is both highly reliable and rapidly adaptable to changing business requirements.
Understanding Data Security in Data Pipelines
A data pipeline is a structured set of automated processes that extract data from various source systems, transform it into a usable format, and load it into a target destination such as a data lake, warehouse, or analytical application. These systems handle vast volumes of sensitive data, making them primary targets for malicious actors.
Data pipeline security is uniquely challenging because data changes state, location, and format continuously throughout its journey. Risks manifest at various stages:
- Data Breaches: Unauthorized external attackers exploit unpatched software or weak credentials to exfiltrate proprietary data directly from active pipelines.
- Data Leaks: Internal misconfigurations, such as leaving an Amazon S3 bucket public or exposing Kafka topics, inadvertently expose confidential data to the internet.
- Credential Exposure: Hardcoding database passwords, API keys, or encryption secrets directly into pipeline orchestration code or GitHub repositories.
- Man-in-the-Middle (MitM) Attacks: Intercepting unencrypted data as it travels across networks between ingestion sources, processing clusters, and storage tiers.
Securing these pipelines is critical because a compromise can lead to severe regulatory fines under frameworks like GDPR or HIPAA, loss of intellectual property, and a total collapse of customer trust. Data pipeline security requires a holistic approach that protects data at rest, in transit, and during active compute operations.
How DataOps Improves Security in Pipelines
DataOps addresses security vulnerabilities by replacing manual verification with automated guardrails, effectively introducing DevSecOps for data. By weaving security checks directly into the continuous integration and deployment pipeline, vulnerabilities are detected and mitigated long before code or data reaches production.
Automation of Security Checks
Every piece of code written to alter a data pipeline undergoes automated testing within a DataOps framework. Static application security testing (SAST) tools scan data pipeline scripts, SQL transformations, and infrastructure-as-code (IaC) files for vulnerabilities, such as hardcoded credentials or unencrypted storage declarations, before allowing code merges.
Continuous Monitoring
DataOps implements real-time monitoring across the complete data lifecycle. By utilizing statistical process control, the operational environment monitors data volume, schema drift, and execution times. If a pipeline suddenly processes an unexpectedly large volume of data or attempts to transfer data to an unauthorized IP address, the system triggers alerts or halts execution automatically.
Policy Enforcement
Global data policies, such as tokenization requirements for Personally Identifiable Information (PII), are managed as code. DataOps platforms enforce these policies universally, ensuring that every new pipeline automatically inherits the organization’s overarching security standards without requiring manual configuration by individual engineers.
Data Validation
Automated data validation tests run at every stage of the pipeline: ingestion, transformation, and delivery. These tests verify that the data meets strict quality and structural criteria. If anomalous data structures or unauthorized data types appear, the DataOps framework quarantines the corrupted records to prevent downstream contamination.
Access Control Integration
DataOps integrates natively with central identity and access management (IAM) systems. Instead of embedding static passwords within data tools, pipelines use short-lived, automated tokens and service accounts. This integration guarantees that pipelines operate with the absolute minimum privileges necessary to execute their specific tasks.
Key Security Mechanisms in DataOps
To protect sensitive information without introducing operational friction, DataOps relies on five core technical pillars. These mechanisms work in tandem to construct a comprehensive security perimeter around the data architecture.
| Security Mechanism | Primary Technical Function | Impact on Pipeline Security |
| Encryption | Protects data using advanced algorithms (AES-256, TLS 1.3) at rest and in transit. | Prevents unauthorized data reading if storage media or network packets are intercepted. |
| Role-Based Access Control (RBAC) | Restricts data and pipeline access based on defined organizational roles. | Enforces the principle of least privilege, preventing unauthorized data access. |
| Data Masking & Tokenization | Replaces sensitive fields with realistic or tokenized data in non-production areas. | Allows developers and analysts to work with realistic structures without seeing raw PII. |
| Audit Logging | Records comprehensive event trails for every read, write, and configuration change. | Provides the historical trace needed for forensic analysis and regulatory compliance audits. |
| Pipeline Versioning | Tracks all pipeline code, configurations, and schemas through version control systems. | Ensures predictability, rapid rollback capabilities, and strict change accountability. |
Encryption in Transit and at Rest
Encryption forms the foundation of data protection. DataOps enforces Transport Layer Security (TLS 1.3) across all network connections, ensuring data cannot be read during transit between extraction points and processing engines. At rest, data stored within data lakes or warehouses is protected via Advanced Encryption Standard (AES-256) encryption, utilizing automated key rotation managed by cloud hardware security modules (HSMs).
Role-Based Access Control (RBAC)
RBAC minimizes internal security risks by ensuring that users and system accounts have access only to the data required for their specific duties. DataOps automates the deployment of RBAC configurations across databases and processing clusters, granting data scientists access to aggregated data models while restricting access to raw, unmasked data tables.
Data Masking and Tokenization
To protect privacy while maintaining analytical utility, DataOps applies data masking and tokenization at the ingestion boundary. Sensitive attributes, such as credit card numbers or medical identifiers, are dynamically replaced with structurally identical synthetic tokens. This allows software engineers and analysts to test code and build models without exposing sensitive production values.
Audit Logging
Comprehensive audit logging captures every event within the data ecosystem, tracking who accessed what data, which pipeline modified a specific table, and when a schema change occurred. These immutable logs are streamed to centralized security information and event management (SIEM) systems for real-time analysis, compliance verification, and forensic investigation.
Pipeline Versioning
Treating pipelines as code via Git repositories guarantees that every modification to a data workflow is tracked and approved. If a security vulnerability is discovered in a production pipeline deployment, developers can immediately roll back the infrastructure to a known secure historical state, minimizing exposure times.
DataOps Security Workflow
A secure DataOps workflow protects data at every step of its journey, applying specific security controls from initial ingestion through to final monitoring.
[ Ingestion Stage ] --> [ Transformation Stage ] --> [ Storage Stage ]
(Source Validation, (Masking, Tokenization, (At-Rest Encryption,
TLS Encryption) Anonymization) Immutable Backups)
|
v
[ Monitoring Layer ] <-- [ Deployment Pipeline ] <------------+
(Real-time SIEM, (Automated SAST scans,
Anomaly Detection) IaC Security Validation)
1. Data Ingestion Stage Security
Security begins at the ingestion boundary. When data is pulled from external APIs, operational databases, or third-party streams, the ingestion layer validates the identity of the source system using cryptographic certificates. The data is checked against schema definitions to block malicious injections, and network connections are restricted to dedicated virtual private networks (VPNs) or private cloud links.
2. Data Transformation Stage Security
As data passes through processing engines like Apache Spark or dbt, the transformation layer isolates data processing in secure, ephemeral clusters. During this stage, automated scripts strip out unnecessary metadata and perform column-level data masking, tokenization, and anonymization. This step strips sensitive details before writing the output to downstream storage tiers.
3. Storage Security
Once data is written to data lakes, file systems, or relational warehouses, storage security rules take effect. Storage buckets are configured with zero public access by default. DataOps automation applies strict lifecycle policies that automatically encrypt datasets, enforce object locking for immutability to combat ransomware, and purge temporary staging directories.
4. Deployment Pipeline Security
The deployment pipeline governs how data engineering code reaches production environments. Before any code goes live, the DataOps CI/CD runner executes automated security scanners. These tools check for dependency vulnerabilities, scan container configurations for root-access exploits, and run automated integration tests to confirm the code does not violate data governance policies.
5. Monitoring Layer Security
The final line of defense is the continuous monitoring layer. Here, operational metrics are analyzed alongside security event streams. Machine learning models establish baseline operational profiles for the pipelines. If a workflow deviates from its historical resource utilization, connects to an unknown external endpoint, or processes a data volume that triggers an anomaly threshold, the system immediately isolates the compromised environment.
Real-World Use Cases
The implementation of DataOps security workflows varies across industries, depending on specific regulatory environments and the nature of the data being processed.
Banking Data Security
A multinational retail bank struggled with slow data provisioning for its quantitative risk analysts. Security teams required weeks to approve data extraction requests due to stringent financial regulations. By implementing a secure DataOps pipeline, the bank automated its data masking and tokenization processes at the ingestion layer.
Now, when production transaction logs are extracted, PII is automatically tokenized using format-preserving encryption. Financial analysts receive realistic, high-fidelity datasets in minutes rather than weeks. This architecture ensures absolute compliance with financial data governance standards while drastically accelerating the delivery of risk modeling insights.
Healthcare Data Protection
A healthcare analytics company manages electronic health records (EHR) to provide predictive diagnostic insights to hospitals. The platform must adhere strictly to HIPAA guidelines, where any leak of Protected Health Information (PHI) carries severe penalties. The company adopted a DataOps framework designed to enforce row- and column-level security automatically based on user context.
When a pipeline runs, it queries a central identity server. Doctors see complete clinical records, medical researchers see anonymized and aggregated diagnostic data, and billing software developers see only financial transactions with clinical data completely stripped out. Automated audit trails track every access request, ensuring effortless compliance reporting during federal audits.
E-Commerce Transaction Security
A global e-commerce platform processes millions of checkout transactions daily across multiple continents. To protect customer payment details and comply with PCI-DSS requirements, the company used DataOps to implement a zero-trust data pipeline architecture. Payment data is separated at the ingestion edge into an isolated, highly secure vault.
+-------------------+
| Payment Vault |
+--> | (PCI-DSS Zone) |
| +-------------------+
+----------------------+ |
| Ingestion Edge | ----+
| (Transaction Stream) | |
+----------------------+ | +-------------------+
+--> | Analytics Engine |
| (Tokenized Data) |
+-------------------+
The primary analytical pipelines only process non-sensitive tokens and purchase metadata. This separation minimizes the scope of PCI compliance audits, shields analytical teams from managing raw cardholder data, and protects the primary data lake from credential-based attacks.
Cloud Data Platforms
A tech enterprise operates a decentralized data mesh architecture across AWS and Google Cloud Platform. Managing data governance across multi-cloud environments created a fragmented security perimeter. By implementing DataOps principles via centralized Infrastructure as Code (IaC), the data platform team unified their security posture.
Every cloud data lake bucket, access control policy, and encryption key configuration is defined within centralized Terraform repositories. The DataOps pipeline automatically checks these definitions before deployment, ensuring that no cloud resource can ever be provisioned with weak access configurations, regardless of which cloud provider hosts the underlying data.
Benefits of DataOps for Security
Adopting DataOps principles within data engineering workflows provides a wide array of security benefits that go far beyond standard operational efficiencies.
- Reduced Human Error: Automating pipeline configurations, access controls, and deployments removes manual touchpoints, eliminating the misconfigurations that cause over 80% of data breaches.
- Faster Threat Detection: Real-time operational monitoring and anomaly detection ensure that unauthorized pipeline behavior or data leaks are flagged and mitigated within minutes, rather than months.
- Improved Regulatory Compliance: Continuous data validation, integrated masking, and automated auditing provide an immutable record of data lineage, simplifying compliance with GDPR, HIPAA, and CCPA.
- Better Data Governance: Data governance policies are shifted from static paper documents directly into executable pipeline code, ensuring universal, automated enforcement across all data assets.
- End-to-End Visibility: Data engineers and security personnel gain a clear view of data flows, lineages, and transformation steps, allowing teams to trace exactly where sensitive data originates and where it is consumed.
Challenges in Securing Data Pipelines
While the benefits of a secure DataOps methodology are undeniable, data engineering teams face distinct obstacles during implementation.
Complex Architectures
Modern data ecosystems are a patchwork of legacy mainframes, modern cloud warehouses, streaming queues, and edge computing nodes. Orchestrating a unified security framework across different technologies—each with its own native access controls and logging formats—requires careful planning and deep technical expertise.
Multi-Cloud Environments
Distributing data across multiple cloud vendors creates fragmented identity perimeters. An AWS IAM policy operates differently than a Google Cloud IAM policy, and reconciling these permission models into a coherent security strategy increases operational complexity.
Misconfiguration Risks
As pipelines scale to handle thousands of concurrent jobs, the risk of a misconfigured pipeline configuration increases. If a single CI/CD deployment script contains an error, it could inadvertently expose a data repository or apply incorrect data masking rules across downstream datasets.
Skill Gaps
The intersection of data engineering, cloud infrastructure operations, and cybersecurity requires a highly specialized skill set. Finding professionals who understand data pipeline design, data governance frameworks, and automated security scanning tools is a notable challenge for many enterprises.
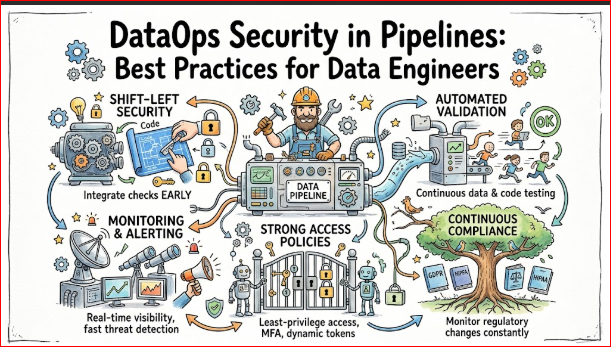
Best Practices for Data Pipeline Security
To overcome these challenges and successfully build a resilient DataOps ecosystem, organizations should adopt five foundational best practices.
Shift-Left Security Approach
Integrate security considerations into the earliest phases of data pipeline development. Engineers should design data masking schemas, define access controls, and plan encryption strategies during the architecture phase, rather than attempting to apply security patches to an active production pipeline.
+--------------------------------------------------------------------------+
| SHIFT-LEFT DATAOPS SECURITY |
| |
| [Design Phase] --> [Code & Test] --> [Deploy] --> [Monitor] |
| * Threat * SAST scans * Access * Real-time |
| Modeling * Masking tests Validation Anomaly |
| * Schema Policy * IaC Validation * Zero-Trust Detection |
+--------------------------------------------------------------------------+
Automated Validation
Implement rigorous automated data validation checks at every stage of the pipeline lifecycle. Use data profiling tools within CI/CD pipelines to ensure that changes to code do not alter expected data structures, introduce unauthorized sensitive fields, or cause data corruption downstream.
Continuous Compliance
Treat compliance as an ongoing operational state rather than an annual audit preparation event. Automate the generation of data lineage reports, maintain immutable audit trail logs, and run daily automated compliance checks to ensure all production environments strictly adhere to regulatory mandates.
Strong Access Policies
Enforce a strict zero-trust access model across the entire data estate. Implement network segmentation, use ephemeral authentication tokens, disable static database passwords, and mandate multi-factor authentication for every human and programmatic entity interacting with the data architecture.
Monitoring and Alerting
Build a centralized monitoring dashboard that integrates pipeline operational metrics with security log networks. Configure intelligent alerting thresholds that notify the appropriate data engineering and security response teams the moment a pipeline deviates from normal baseline performance parameters.
Future of DataOps Security
As data volumes continue to grow exponentially, the strategies used to protect data pipelines must evolve accordingly. The future of DataOps security centers on intelligent automation and zero-trust orchestration.
AI-Driven Security in Pipelines
Artificial intelligence and machine learning models will become deeply integrated into DataOps pipelines to predict and neutralize threats. Future systems will automatically analyze pipeline operations, identifying complex threat vectors and data exfiltration patterns that are impossible for human operators to detect manually.
Self-Healing Data Systems
When a pipeline encounters a security exception or a data validation failure, future frameworks will not simply halt execution and raise an alert. Instead, self-healing data systems will automatically isolate compromised data rows, trace the vulnerability back to its source, and apply automated code patches to remediate the security flaw without causing downtime.
Real-Time Anomaly Detection
Static threshold alerts will be replaced by continuous, real-time contextual analysis. Security systems will evaluate the intent behind data requests, considering variables such as the user’s current project allocation, historical data access patterns, and systemic risk conditions to dynamically adjust access boundaries.
Zero-Trust Architecture Adoption
The traditional network perimeter model will disappear entirely from data engineering design. Every data resource, storage block, and pipeline worker node will continually authenticate and authorize every transaction, ensuring that data remains protected even if an attacker manages to breach the internal enterprise network.
FAQ Section
1.What is the primary difference between DevOps and DataOps regarding security?
The primary difference lies in the nature of the assets being secured. DevOps focuses on protecting application code, deployment files, and infrastructure states, which are generally predictable and static. DataOps security must secure code and infrastructure while protecting dynamic data streams that continually change in volume, format, and sensitivity as they pass through processing engines.
2.How does shifting left benefit data pipeline security?
Shifting left integrates security tests, dependency scans, and data masking protocols into the initial stages of pipeline development. This proactive methodology identifies vulnerabilities while code is still in development. It prevents configuration flaws, unmasked PII, or hardcoded keys from entering production environments, where they are much more expensive and complex to fix.
3.Can DataOps help with GDPR and HIPAA compliance?
Yes, DataOps simplifies compliance with regulatory frameworks. By automating data lineage tracking, enforcing column-level masking for PII or PHI at the ingestion boundary, and maintaining immutable audit logs, DataOps ensures that an organization can easily prove compliance with data privacy laws through automated, reproducible documentation.
4.What is data lineage, and why is it important for security?
Data lineage is the comprehensive map that tracks the lifecycle of data from its original source system, through every intermediate transformation stage, to its final analytical destination. Lineage is critical for security because it allows teams to trace the origin of a data corruption event, identify exactly which users or processes interacted with sensitive datasets, and verify that data masking rules were correctly applied throughout the pipeline journey.
5.How does automated data validation protect against security threats?
Automated data validation acts as a continuous quality and security gatekeeper. By running validation checks at every stage of a pipeline, the system verifies that incoming data matches strict, predefined structural and programmatic constraints. This mechanism stops SQL injection attempts, blocks unexpected schema alterations that might leak sensitive fields, and quarantines corrupted files before they reach downstream users.
6.What role does encryption play in a secure DataOps pipeline?
Encryption acts as the foundational defense mechanism that protects data across its entire operational journey. DataOps automation ensures that Advanced Encryption Standard (AES-256) is applied to all data repositories at rest, while Transport Layer Security (TLS 1.3) is enforced across every single network link to protect data from being read or intercepted while in transit.
7.How do we handle secrets management within a DataOps framework?
Secrets management within DataOps completely avoids the use of hardcoded passwords, access keys, or connection strings inside pipeline code repositories. Instead, pipelines utilize central, secure secrets managers. At runtime, the automated environment pulls short-lived, ephemeral execution tokens and certificates, ensuring that credentials are encrypted, rotated frequently, and audited closely.
8.Is DataOps security only applicable to cloud-native data pipelines?
No, DataOps security principles apply universally to cloud-native, on-premises data centers, and hybrid data ecosystems. While cloud platforms offer unique managed APIs for access control and monitoring, the core concepts of automation, version control, continuous monitoring, and policy enforcement remain identical across any physical or virtual deployment model.
Conclusion
The rapid expansion of enterprise data pipelines requires a fundamental shift in how we approach data security. Traditional, manual security strategies can no longer keep pace with the velocity and complexity of modern data engineering. By adopting a DataOps methodology, organizations can build automated, secure pipelines that protect data at scale without sacrificing business agility.
As data pipelines become increasingly decentralized and distributed across multi-cloud environments, embedding automated security controls, continuous validation, and zero-trust access management directly into pipeline code is the only path forward. This proactive strategy protects intellectual property and ensures ongoing regulatory compliance, turning security into a distinct operational advantage.