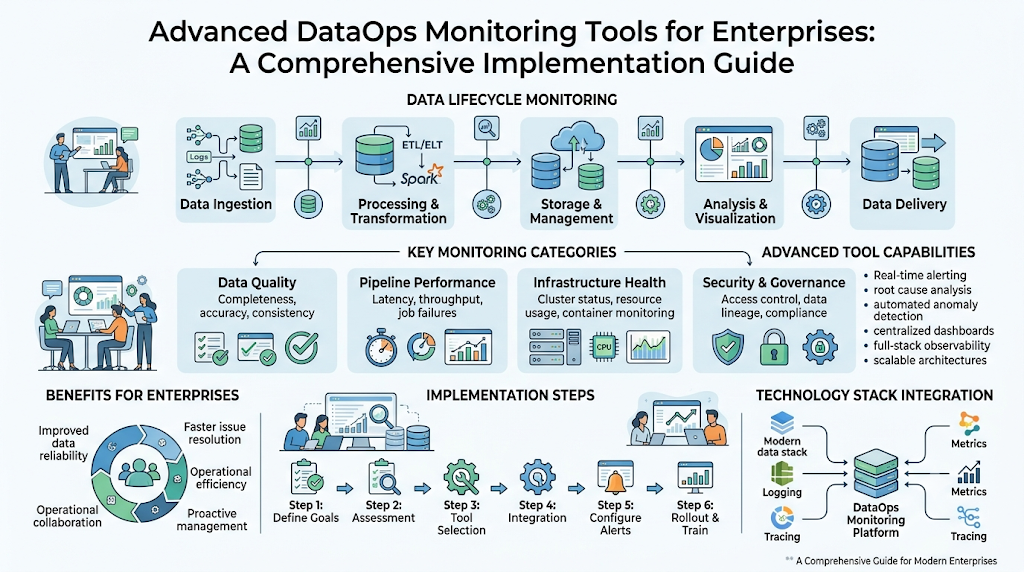
Introduction
Enterprise data environments are becoming more complex as organizations depend on cloud platforms, data lakes, data warehouses, real-time pipelines, analytics tools, and automated workflows. When one pipeline fails or poor-quality data reaches a dashboard, the impact can affect business decisions, customer reporting, compliance, and operational trust. This is why Advanced DataOps Monitoring Tools for Enterprises are now essential. These tools help data teams monitor pipelines, validate data quality, detect anomalies, track performance, and respond quickly when something goes wrong. For teams that want to learn DataOps concepts in a practical and structured way, TheDataOps.org can be used as an educational learning resource for understanding enterprise DataOps practices, monitoring workflows, and data reliability principles.
What Is DataOps Monitoring?
DataOps monitoring is the continuous tracking of data pipelines, data quality, workflow performance, infrastructure health, and operational reliability across a data platform.
In simple terms, it helps teams answer important questions such as:
- Is the data pipeline running successfully?
- Is the data fresh and available on time?
- Has the data quality changed unexpectedly?
- Are dashboards showing trusted information?
- Where did the pipeline fail?
- Which team should respond?
The main objective of DataOps monitoring is to keep data systems reliable, visible, and operationally efficient. It supports data engineers, analytics engineers, platform teams, and business users by making data problems easier to detect and resolve.
DataOps monitoring is closely connected with data observability. Monitoring tells teams that something has happened, while observability helps explain why it happened. For example, monitoring may show that a pipeline failed, but observability can help identify whether the cause was schema drift, late source data, infrastructure limits, or transformation errors.
In enterprise environments, this visibility is very important because data systems often support finance reports, healthcare analytics, customer intelligence, supply chain forecasting, regulatory reporting, and executive dashboards.
Why Monitoring Is Critical in Enterprise DataOps
Enterprise DataOps is not just about moving data from one system to another. It is about delivering trusted, timely, and usable data at scale. Monitoring plays a central role in achieving that goal.
Pipeline Reliability
Data pipelines often run across multiple systems, including ingestion tools, transformation jobs, orchestration platforms, storage layers, and analytics applications. A small failure in one stage can affect downstream dashboards and reports.
Advanced monitoring helps teams detect failed jobs, delayed workflows, broken dependencies, and incomplete data loads before business users are impacted.
For example, if a sales reporting pipeline fails before the morning executive dashboard refresh, monitoring can alert the data operations team immediately.
Data Quality Assurance
Data quality monitoring checks whether data is complete, accurate, consistent, valid, and fresh. It helps detect missing values, duplicate records, unexpected format changes, incorrect calculations, or sudden volume drops.
For enterprises, poor data quality can lead to wrong decisions, compliance risks, and loss of trust in analytics.
For example, if a customer table usually receives thousands of records daily but suddenly receives only a few hundred, a data quality monitoring tool can flag this anomaly.
Operational Visibility
Enterprise data teams need visibility across pipelines, workflows, databases, cloud services, logs, and infrastructure. Without monitoring, teams may not know where data is delayed, which system is overloaded, or why reports are incomplete.
Operational visibility helps teams move from reactive troubleshooting to proactive management.
Performance Optimization
Pipeline performance monitoring helps teams understand job duration, processing latency, resource usage, and bottlenecks.
For example, if a transformation job that normally takes ten minutes starts taking one hour, performance monitoring can help identify whether the issue is data volume growth, inefficient queries, poor resource allocation, or infrastructure limits.
Regulatory Compliance
Many enterprises operate in regulated industries where data accuracy, auditability, and traceability are important. Monitoring supports compliance by tracking data movement, quality checks, access patterns, and operational history.
This is especially useful in sectors such as banking, healthcare, insurance, telecommunications, and public sector analytics.
Understanding Advanced DataOps Monitoring Tools
Advanced DataOps monitoring tools are designed to provide end-to-end visibility across the complete data lifecycle. They go beyond basic server monitoring or simple job status checks.
Data Observability Platforms
Data observability platforms monitor the health of data across freshness, volume, schema, quality, lineage, and usage. They help teams understand whether data is trustworthy and where issues originate.
These platforms are useful when enterprises have many data sources, complex transformations, and multiple downstream reports.
Pipeline Performance Monitoring
Pipeline performance monitoring tracks job execution time, throughput, latency, retry attempts, failures, and processing delays.
For example, an enterprise may monitor how long it takes to move data from a transactional system into a cloud warehouse and then into a reporting dashboard.
Data Quality Monitoring
Data quality monitoring validates whether data meets expected business and technical rules. It can check for:
- Missing values
- Duplicate records
- Invalid formats
- Incorrect ranges
- Broken relationships
- Unexpected null values
- Sudden data volume changes
This helps prevent unreliable data from reaching analytics users.
Metadata Monitoring
Metadata monitoring tracks information about data assets, including schema changes, table ownership, lineage, freshness, usage, and dependencies.
For example, if a source system changes a column name, metadata monitoring can help identify which downstream pipelines and dashboards may break.
Infrastructure Monitoring
Data pipelines depend on compute resources, storage systems, network connections, databases, containers, and cloud services. Infrastructure monitoring tracks resource health so teams can understand whether technical limits are affecting pipeline reliability.
Workflow Monitoring
Workflow monitoring focuses on orchestration systems and scheduled jobs. It tracks dependencies, task status, retries, failures, execution order, and completion time.
This is important when enterprises manage hundreds or thousands of scheduled workflows.
Core Features of Enterprise Monitoring Platforms
Enterprise monitoring platforms need more than basic alerts. They must provide intelligent visibility, operational context, and scalable control.
Real-Time Dashboards
Real-time dashboards show the current status of pipelines, workflows, data quality checks, incidents, and system health.
A good dashboard should help teams quickly answer:
- Which pipelines are healthy?
- Which jobs failed?
- Which data sets are delayed?
- Which alerts need attention?
- Which business reports may be affected?
Intelligent Alerts
Intelligent alerts reduce noise by sending notifications only when an issue is meaningful. Instead of alerting on every minor event, advanced systems use context, severity, business impact, and historical patterns.
For example, a failed low-priority test pipeline may not need urgent escalation, but a failed finance reporting pipeline may require immediate action.
Anomaly Detection
Anomaly detection identifies unusual behavior in data volume, pipeline duration, freshness, quality scores, or resource usage.
For example, if a customer transaction pipeline receives much lower data volume than usual, anomaly detection can flag the change before users notice missing reports.
Automated Root Cause Analysis
Automated root cause analysis helps teams identify why a problem happened. It may analyze logs, metadata, lineage, dependencies, recent deployments, schema changes, and infrastructure events.
This reduces investigation time and improves incident response.
Historical Trend Analysis
Historical analysis helps teams understand patterns over time. It can show whether failures are increasing, pipeline latency is growing, or data quality is improving.
This supports long-term optimization and platform planning.
Capacity and Performance Tracking
Capacity tracking monitors compute usage, storage growth, processing time, and workload demand. It helps enterprises plan resources before performance problems become serious.
How Advanced DataOps Monitoring Works
Advanced DataOps monitoring works by collecting operational and data signals from many systems, analyzing them, and turning them into useful insights.
Data Collection
The first stage is collecting data from pipelines, databases, orchestration tools, logs, cloud platforms, data warehouses, and quality validation systems.
For example, an enterprise retail company may collect signals from order systems, payment systems, warehouse tables, transformation jobs, and reporting dashboards.
Metric Aggregation
After collection, metrics are grouped and organized. These may include pipeline success rate, job duration, data freshness, error count, record volume, processing latency, and infrastructure usage.
Aggregation helps teams see patterns across multiple systems instead of reviewing each tool separately.
Quality Validation
Quality validation checks whether data meets expected rules. For example, a healthcare analytics team may validate that patient records contain required fields, correct date formats, and valid department codes.
If data does not meet the expected rules, the system can flag the issue before it affects reports.
Alert Generation
When the system detects failure, delay, anomaly, or quality issue, it generates an alert. Advanced tools can classify alerts by severity, business impact, affected pipeline, and responsible team.
For example, a delayed revenue dashboard refresh may be marked as high priority because it affects leadership reporting.
Incident Investigation
During incident investigation, monitoring tools help teams trace the issue. They may show pipeline logs, dependency maps, lineage views, recent schema changes, failed validation checks, and affected data assets.
This helps teams avoid manual guessing.
Continuous Optimization
Monitoring is not only for incident response. It also helps teams improve pipelines over time. By reviewing trends, teams can optimize slow jobs, improve alerts, remove unreliable dependencies, and strengthen quality rules.
Benefits of Advanced DataOps Monitoring Tools
Advanced DataOps monitoring tools provide strong operational and business value for enterprises.
Faster Issue Detection
Monitoring tools help detect failures, delays, and quality issues quickly. This reduces the time between issue occurrence and team response.
Improved Data Reliability
Reliable data builds trust. When teams monitor freshness, quality, schema, and pipeline health, business users can rely more confidently on reports and analytics.
Reduced Pipeline Downtime
By detecting issues early and supporting root cause analysis, monitoring tools reduce downtime and help teams restore services faster.
Better Decision-Making
Business decisions depend on trusted data. Monitoring ensures that dashboards, reports, and analytics models are based on accurate and timely information.
Enhanced Operational Efficiency
Automated alerts, dashboards, and root cause insights reduce manual investigation. This allows data teams to focus more on improvement and less on repetitive troubleshooting.
Enterprise Scalability
As data volume and pipeline complexity grow, manual monitoring becomes difficult. Advanced monitoring tools allow enterprises to scale data operations without losing visibility.
Enterprise Monitoring Best Practices from TheDataOps.org
TheDataOps.org emphasizes that enterprise DataOps monitoring should be practical, continuous, and aligned with business value. Monitoring should not be treated as a one-time setup. It should evolve with pipelines, platforms, and organizational needs.
Monitor Data Quality Continuously
Data quality should be checked throughout the data lifecycle. Teams should monitor completeness, accuracy, consistency, freshness, and validity across critical data sets.
Quality rules should be connected to real business expectations, not only technical assumptions.
Standardize Operational Metrics
Enterprises should define common metrics for pipeline health, data quality, latency, freshness, failures, and incident response. Standard metrics help different teams speak the same operational language.
Build End-to-End Observability
Monitoring should cover the full journey of data from source systems to final dashboards. End-to-end observability helps teams understand upstream and downstream impact.
Automate Alerting and Reporting
Manual checking is not reliable at enterprise scale. Teams should automate alerts, reports, status checks, and escalation workflows.
Automation improves speed and reduces human error.
Track Pipeline Performance
Performance monitoring should include job duration, throughput, resource usage, retries, and processing delays. This helps teams identify bottlenecks before they affect business users.
Continuously Improve Monitoring Rules
Monitoring rules should not remain static forever. Teams should review false alerts, missed incidents, business changes, and platform updates to improve rules regularly.
Popular Categories of Enterprise Monitoring Tools
Enterprise monitoring often requires a combination of tools. Each category serves a different purpose in the DataOps ecosystem.
| Tool Category | Primary Purpose | Enterprise Benefit | Typical Use Case |
|---|---|---|---|
| Data Observability Platforms | Monitor data health, freshness, schema, lineage, and quality | Builds trust in analytics and reduces hidden data issues | Detecting broken downstream reports caused by upstream schema changes |
| Log Analytics Solutions | Analyze logs from pipelines, applications, and infrastructure | Helps troubleshoot failures and understand system behavior | Investigating failed data ingestion jobs |
| Infrastructure Monitoring Platforms | Track compute, storage, memory, network, and cloud resources | Prevents performance bottlenecks and capacity issues | Monitoring warehouse compute usage during large batch processing |
| Workflow Monitoring Tools | Track scheduled jobs, dependencies, task status, and retries | Improves pipeline orchestration visibility | Monitoring daily finance reporting workflows |
| Cloud Monitoring Services | Monitor cloud-native data services and platform resources | Supports scalable and distributed enterprise environments | Tracking cloud data lake storage, processing jobs, and service health |
Real-World Enterprise Use Cases
Advanced DataOps monitoring tools are useful across many industries and business functions.
Financial Data Platforms
Banks and financial institutions use data pipelines for risk reporting, fraud analytics, transaction monitoring, and regulatory reporting.
Monitoring helps ensure that financial data is complete, accurate, timely, and traceable. If a transaction pipeline is delayed or a reconciliation table has missing records, alerts can help teams respond quickly.
Healthcare Analytics
Healthcare organizations depend on reliable data for patient operations, claims analysis, hospital performance, and clinical reporting.
Monitoring can detect missing patient records, delayed claims feeds, incorrect department codes, or failed analytics refreshes. This protects reporting accuracy and operational trust.
Retail and E-Commerce
Retail businesses rely on data from orders, inventory, payments, customer behavior, logistics, and marketing platforms.
Monitoring helps detect problems such as missing sales data, delayed inventory updates, incorrect customer segmentation, or slow recommendation pipelines.
Manufacturing Analytics
Manufacturing companies use data from machines, sensors, supply chains, production lines, and quality systems.
DataOps monitoring helps track sensor data freshness, production reporting accuracy, and pipeline performance for operational analytics.
Telecommunications
Telecom companies manage high-volume data from networks, billing systems, customer service platforms, and usage analytics.
Monitoring helps detect delayed usage data, billing pipeline failures, network analytics anomalies, and data quality issues across large-scale systems.
Common Monitoring Challenges
Enterprise monitoring is powerful, but it also comes with practical challenges.
Data Silos
Different teams may use separate tools, platforms, and reporting systems. This creates limited visibility.
Solution: Build a unified monitoring strategy that connects pipelines, metadata, logs, quality checks, and business reports.
Alert Fatigue
Too many alerts can overwhelm teams. When alerts are not meaningful, people may ignore them.
Solution: Use severity levels, business context, alert grouping, and intelligent thresholds. Review alerts regularly and remove unnecessary noise.
Integration Complexity
Enterprise data platforms often include many systems, such as cloud services, warehouses, lakes, orchestration tools, and reporting platforms.
Solution: Choose monitoring tools that support flexible integrations and open standards. Start with critical pipelines before expanding.
Rapid Data Growth
As data volume grows, pipelines can become slower and more expensive.
Solution: Track processing latency, storage growth, compute usage, and pipeline duration. Use trend analysis for capacity planning.
Limited Visibility
Some teams only monitor infrastructure or job failures, but not data quality or downstream impact.
Solution: Implement data observability across freshness, volume, schema, lineage, quality, and usage.
Best Practices for Enterprise DataOps Monitoring
A strong DataOps monitoring strategy should combine tools, processes, metrics, and team collaboration.
Define Meaningful KPIs
Enterprises should define monitoring KPIs that reflect both technical health and business impact. Useful KPIs include pipeline success rate, data freshness, data quality score, latency, incident resolution time, and report availability.
Implement Data Observability
Monitoring should not stop at infrastructure or job status. Teams need observability into data health, lineage, schema changes, dependencies, and downstream usage.
Standardize Monitoring Processes
A standard monitoring process helps teams respond consistently. This includes alert ownership, escalation paths, incident documentation, review meetings, and improvement actions.
Continuously Optimize Alerts
Alerts should be reviewed regularly. Teams should reduce false positives, improve thresholds, and prioritize alerts based on business impact.
Improve Cross-Team Collaboration
Data reliability depends on collaboration between data engineers, platform engineers, analytics teams, business users, and governance teams.
Shared dashboards, common definitions, and clear ownership improve response quality.
Traditional Monitoring vs Advanced DataOps Monitoring
| Capability | Traditional Monitoring | Advanced DataOps Monitoring |
| Visibility | Component-level | End-to-end data pipelines |
| Alerting | Static thresholds | Context-aware intelligence |
| Root Cause Analysis | Mostly manual | Automated insights |
| Data Quality | Limited | Continuous validation |
| Scalability | Moderate | Enterprise-ready |
Traditional monitoring is useful for checking system health, but it often misses data-specific problems. Advanced DataOps monitoring focuses on the full data lifecycle, including pipelines, quality, freshness, metadata, workflow performance, and business impact.
Key Enterprise Metrics to Track
Enterprise DataOps teams should track metrics that show both technical performance and data trust.
Pipeline Success Rate
This shows the percentage of pipelines that complete successfully. A low success rate indicates reliability problems.
Data Freshness
Data freshness measures whether data is updated within the expected time window. Freshness is critical for operational dashboards and time-sensitive analytics.
Data Quality Score
A data quality score summarizes completeness, accuracy, consistency, validity, and reliability. It helps teams track trust over time.
Processing Latency
Latency measures how long data takes to move from source to destination. High latency may affect real-time or near-real-time reporting.
Incident Resolution Time
This measures how quickly teams resolve data incidents. Lower resolution time indicates better operational maturity.
Infrastructure Utilization
This tracks compute, storage, memory, and network usage. It helps teams manage performance and cost.
Future of Enterprise DataOps Monitoring
The future of enterprise DataOps monitoring is moving toward more intelligent, automated, and self-optimizing systems.
AI-Assisted Observability
AI-assisted observability can help detect unusual patterns, summarize incidents, recommend fixes, and reduce manual investigation.
Predictive Monitoring
Predictive monitoring uses historical trends to identify possible failures before they happen. For example, it may predict that a pipeline will miss its service-level target based on current processing speed.
Autonomous Data Operations
Autonomous DataOps aims to reduce manual work by automating monitoring, validation, escalation, and remediation.
Self-Healing Pipelines
Self-healing pipelines can automatically retry failed jobs, switch resources, apply fallback logic, or pause downstream delivery when data quality is poor.
Unified Enterprise Analytics
Monitoring will become more connected with analytics, governance, metadata, and business intelligence. This will help enterprises manage data reliability as a complete operational discipline.
Career Opportunities
As enterprises invest more in DataOps monitoring and observability, new career opportunities are growing for technical professionals.
DataOps Engineer
A DataOps Engineer manages data pipelines, automation, monitoring, deployment workflows, and operational reliability.
Data Observability Engineer
A Data Observability Engineer focuses on data health, quality checks, lineage visibility, anomaly detection, and monitoring standards.
Analytics Platform Engineer
An Analytics Platform Engineer builds and manages platforms that support analytics teams, dashboards, data models, and business reporting.
Data Reliability Engineer
A Data Reliability Engineer focuses on improving the reliability, performance, and availability of data systems.
Enterprise Data Architect
An Enterprise Data Architect designs scalable data platforms, governance models, integration patterns, and monitoring strategies.
These roles require knowledge of data engineering, cloud platforms, workflow orchestration, data quality, monitoring tools, and enterprise architecture.
Common Misconceptions About DataOps Monitoring
Myth: Monitoring Is Only About Dashboards
Reality: Dashboards are useful, but monitoring also includes alerts, logs, metrics, quality checks, lineage, incident response, and continuous optimization.
Myth: Monitoring and Observability Are the Same
Reality: Monitoring shows what is happening. Observability helps explain why it is happening by using context, metadata, logs, metrics, and dependencies.
Myth: Data Quality Checks Are Enough
Reality: Data quality checks are important, but enterprises also need pipeline monitoring, performance tracking, infrastructure visibility, and workflow observability.
Myth: Only Large Enterprises Need DataOps Monitoring
Reality: Any organization that depends on data pipelines can benefit from monitoring. Enterprise teams need it at larger scale, but the principles apply broadly.
Myth: Monitoring Is a One-Time Setup
Reality: Monitoring must improve continuously as pipelines, data sources, business rules, and platforms change.
FAQ Section
- What are Advanced DataOps Monitoring Tools?
Advanced DataOps monitoring tools help enterprises track data pipelines, data quality, workflow performance, infrastructure health, and data reliability. They provide alerts, dashboards, anomaly detection, and root cause insights. - Why do enterprises need DataOps monitoring?
Enterprises need DataOps monitoring because complex data pipelines can fail, slow down, or produce poor-quality data. Monitoring helps teams detect problems early and protect business reporting. - What is the difference between monitoring and observability?
Monitoring tells teams that something is wrong. Observability helps teams understand why it is wrong by analyzing logs, metrics, metadata, lineage, and system behavior. - How does data quality monitoring work?
Data quality monitoring checks whether data is complete, accurate, consistent, valid, and fresh. It can detect missing values, duplicates, schema changes, and unusual data patterns. - What metrics should DataOps teams track?
Important metrics include pipeline success rate, data freshness, data quality score, processing latency, incident resolution time, and infrastructure utilization. - Can DataOps monitoring reduce pipeline downtime?
Yes. Monitoring helps teams detect failures early, understand root causes faster, and respond before issues affect business users or critical reports. - What is data observability in enterprise DataOps?
Data observability is the ability to understand the health, movement, quality, and usage of data across the full pipeline. It helps teams build trust in enterprise analytics. - How can enterprises reduce alert fatigue?
Enterprises can reduce alert fatigue by using severity levels, context-aware alerts, grouped notifications, business impact scoring, and regular alert review. - Are DataOps monitoring tools useful for compliance?
Yes. They support compliance by tracking data movement, quality checks, operational history, pipeline behavior, and audit-related information. - What skills are needed to work in DataOps monitoring?
Useful skills include data engineering, SQL, cloud platforms, workflow orchestration, observability, data quality, logging, incident management, and automation.
Final Summary
Advanced DataOps monitoring tools help enterprises build reliable, observable, and resilient data platforms. They provide visibility into pipeline health, data quality, workflow performance, infrastructure usage, and operational incidents. As data environments become more complex, monitoring is no longer optional. Enterprises need continuous observability, intelligent alerts, anomaly detection, automated root cause analysis, and strong operational practices.