Introduction
Modern organizations depend heavily on data. Every department, from finance and sales to healthcare, manufacturing, marketing, and customer support, needs reliable data to make better decisions. As businesses move from traditional systems to cloud-native data environments, data teams face new challenges. Data is collected from many sources, stored across multiple platforms, transformed in different tools, and consumed by dashboards, applications, machine learning models, and analytics teams. This is where Cloud-Based DataOps Platforms become important. A cloud-based DataOps platform helps organizations automate, monitor, govern, and improve data pipelines in the cloud. It brings together data engineering, automation, collaboration, testing, observability, and governance into one modern operating approach. TheDataOps.org is an educational learning resource that helps beginners and professionals understand modern DataOps concepts in a practical way.
What Are Cloud-Based DataOps Platforms?
Cloud-Based DataOps Platforms are cloud-native systems that help teams build, automate, monitor, test, deploy, and manage data pipelines with better reliability, speed, and collaboration.
In simple terms, they help data teams move data from source systems to business users in a controlled, automated, and scalable way.
A typical cloud DataOps platform may support:
- Data ingestion from multiple sources
- Data transformation and validation
- Pipeline scheduling and orchestration
- Automated testing
- Version control
- Monitoring and alerts
- Data quality checks
- Governance and access control
- Cost and performance optimization
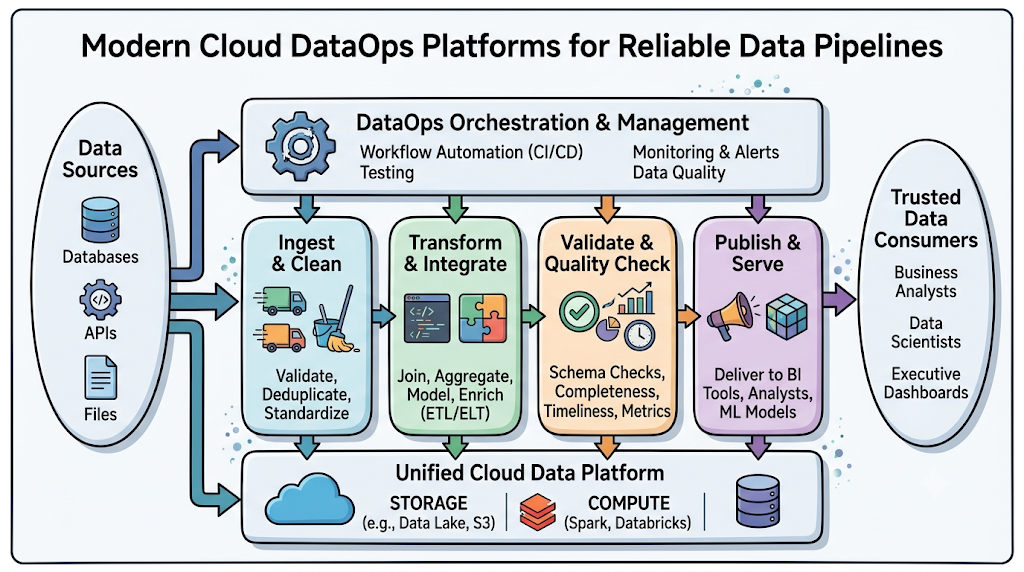
Core Architecture
A cloud-based DataOps architecture usually includes:
- Data sources: Applications, databases, APIs, logs, files, streaming systems, and third-party tools.
- Ingestion layer: Tools that collect and move data into the cloud.
- Storage layer: Data lakes, warehouses, lakehouses, and object storage.
- Processing layer: Transformation, cleansing, enrichment, and aggregation.
- Orchestration layer: Scheduling and managing pipeline workflows.
- Quality layer: Testing data accuracy, completeness, and consistency.
- Observability layer: Monitoring pipeline health, delays, failures, and usage.
- Governance layer: Managing access, lineage, compliance, and policies.
- Consumption layer: Dashboards, reports, analytics, machine learning, and business applications.
Key Objectives
The main goal of a cloud-based DataOps platform is to make data operations faster, safer, and more reliable.
Its key objectives include:
- Delivering trusted data faster
- Reducing manual pipeline work
- Improving collaboration between teams
- Detecting data issues early
- Supporting scalable cloud infrastructure
- Enabling continuous improvement
- Maintaining governance and compliance
Why Cloud-Native DataOps Matters
Traditional data management was often slow and manual. Teams created batch jobs, moved files between systems, and fixed failures after users complained.
Cloud-native DataOps changes this approach.
It allows data teams to create flexible, automated, and observable data pipelines that can grow with business demand. Instead of reacting to problems late, teams can detect issues early and improve data delivery continuously.
For example, an e-commerce company may need real-time product, payment, inventory, and customer data. A cloud DataOps platform helps automate these pipelines so business teams can make faster decisions without waiting for manual reports.
Understanding DataOps Fundamentals
DataOps is a combination of people, process, technology, automation, and governance. It applies modern engineering practices to data workflows.
The goal is not only to move data, but to deliver trusted data continuously.
Data Integration
Data integration means bringing data from different sources into a common platform.
These sources may include:
- Customer relationship management systems
- Enterprise resource planning tools
- Payment platforms
- Website analytics
- Mobile applications
- Cloud databases
- IoT devices
- Marketing platforms
In cloud DataOps, integration is usually automated. Instead of manually exporting and importing files, teams create repeatable pipelines that collect and process data at scheduled or real-time intervals.
Data Pipeline Automation
Data pipeline automation reduces manual work in data movement, transformation, testing, and delivery.
For example, instead of a data engineer running scripts every morning, a DataOps platform can automatically:
- Pull data from source systems
- Clean and validate the data
- Transform it for analytics
- Load it into a warehouse
- Send alerts if something fails
This improves speed and reduces human error.
Continuous Data Delivery
Continuous data delivery means business users receive updated, reliable data regularly.
It is similar to continuous delivery in software development, but applied to data pipelines.
When done well, continuous data delivery allows teams to:
- Release pipeline changes safely
- Test data before publishing
- Detect errors quickly
- Deliver analytics faster
- Support business decisions with fresh data
Data Quality
Data quality is one of the most important parts of DataOps.
Poor-quality data can lead to wrong reports, bad decisions, and operational risk.
A cloud-based DataOps platform helps monitor:
- Missing values
- Duplicate records
- Wrong formats
- Data drift
- Unexpected volume changes
- Broken schema changes
- Inconsistent business rules
For example, if a banking pipeline expects transaction data every hour but suddenly receives half the usual volume, the platform can trigger an alert.
Collaboration
DataOps improves collaboration between data engineers, analysts, architects, cloud teams, security teams, and business users.
Instead of working in separate silos, teams share workflows, documentation, standards, and ownership.
Good collaboration helps teams answer important questions:
- Who owns this data pipeline?
- Where does this data come from?
- What transformation rules were applied?
- Who approved this change?
- Why did this dashboard show different numbers?
Observability
Observability means understanding what is happening inside data systems.
In cloud DataOps, observability helps teams monitor:
- Pipeline success and failure
- Data freshness
- Processing delays
- Data quality issues
- Cloud resource usage
- Cost patterns
- System bottlenecks
Observability is important because modern data systems are complex. Without monitoring, teams may not know that a pipeline is delayed, a table is incomplete, or a dashboard is showing outdated data.
How Cloud-Based DataOps Platforms Work
Cloud-Based DataOps Platforms work by managing the complete data lifecycle. They help teams move data from raw source systems to trusted business use.
Let us understand each stage.
Data Ingestion
Data ingestion is the first step. It means collecting data from different systems and bringing it into the cloud.
Example:
A retail company collects data from online orders, payment gateways, customer support tools, warehouse systems, and marketing campaigns. A cloud DataOps platform ingests this data into a cloud data lake or warehouse.
Ingestion can happen through:
- Batch processing
- Streaming pipelines
- API connections
- Database replication
- File-based uploads
- Event-driven pipelines
The platform helps make ingestion repeatable, trackable, and scalable.
Data Transformation
Raw data is rarely ready for direct business use. It often needs cleaning, formatting, joining, filtering, and enrichment.
For example, customer names may appear in different formats. Product IDs may need mapping. Payment data may need currency conversion. Duplicate records may need removal.
A cloud-based DataOps platform helps automate these transformations.
Common transformation tasks include:
- Standardizing field names
- Removing duplicates
- Applying business rules
- Combining multiple data sources
- Aggregating metrics
- Creating analytics-ready tables
Pipeline Orchestration
Pipeline orchestration means controlling the order in which data tasks run.
For example:
- First, ingest customer data.
- Then, ingest order data.
- Next, join customers with orders.
- Then, calculate revenue metrics.
- Finally, refresh dashboards.
If one step fails, the system should stop the next dependent step and alert the right team.
Cloud DataOps platforms use orchestration to manage complex workflows across many tools and services.
Automated Testing
Automated testing helps confirm that data pipelines are working correctly before data reaches users.
Testing may include:
- Checking whether required columns exist
- Validating data types
- Confirming record counts
- Testing business rules
- Detecting abnormal values
- Verifying schema changes
For example, if a healthcare report expects patient appointment data to include appointment date, doctor ID, and department name, automated tests can catch missing fields before the report is published.
Deployment
Deployment means releasing pipeline changes into production safely.
In traditional data environments, pipeline changes were often manual and risky. A small change in a script could break reports used by leadership teams.
Modern DataOps platforms support controlled deployment using:
- Version control
- Review workflows
- Automated validation
- Environment promotion
- Rollback options
- Approval processes
This makes data pipeline changes more reliable.
Monitoring and Optimization
Once pipelines are running, teams need continuous monitoring.
A cloud-based DataOps platform helps track:
- Pipeline duration
- Failure rate
- Data delay
- Data quality scores
- Resource consumption
- Cost trends
- User impact
For example, if a pipeline that usually runs in 20 minutes suddenly takes two hours, the platform can alert the data engineering team. The team can then check whether the issue is caused by larger data volume, inefficient queries, cloud resource limits, or a source system delay.
TheDataOps.org Guide to Cloud-Based DataOps Platforms
TheDataOps.org explains cloud-based DataOps platforms as a practical approach to building modern, automated, and reliable data operations.
The focus is not only on tools. It is about creating a complete operating model for cloud data engineering.
Building Scalable Data Pipelines
Scalability is a major reason organizations adopt cloud DataOps.
A scalable data pipeline can handle growing data volume without frequent manual redesign.
For example, a small business may start with daily sales reports. As it grows, it may need hourly sales dashboards, customer segmentation, inventory forecasting, and real-time campaign tracking.
Cloud DataOps helps teams design pipelines that can grow step by step.
Good scalable pipeline design includes:
- Modular workflow structure
- Reusable components
- Automated scheduling
- Elastic cloud resources
- Clear ownership
- Monitoring from the beginning
Improving Data Reliability
Data reliability means users can trust the data they receive.
Reliable data pipelines should be:
- Accurate
- Complete
- Timely
- Consistent
- Traceable
- Recoverable after failure
TheDataOps.org emphasizes that reliability must be built into the pipeline lifecycle, not added later.
This includes testing, alerting, documentation, lineage tracking, and defined incident response processes.
Automating Operational Workflows
Automation is at the heart of modern DataOps.
Cloud-based platforms can automate:
- Data collection
- Data validation
- Data transformation
- Pipeline scheduling
- Alert notifications
- Deployment workflows
- Compliance checks
- Resource scaling
Automation does not remove the need for skilled professionals. Instead, it allows data teams to focus on higher-value work such as architecture, optimization, governance, and business problem-solving.
Strengthening Data Governance
Governance is critical in enterprise DataOps.
As more data moves to the cloud, organizations must control who can access it, how it is used, where it came from, and whether it meets compliance requirements.
Strong governance includes:
- Role-based access control
- Data classification
- Audit trails
- Data lineage
- Policy enforcement
- Sensitive data protection
- Approval workflows
A cloud-based DataOps platform helps governance become part of daily operations instead of a separate manual process.
Preparing for Enterprise Data Growth
Enterprise data continues to grow across applications, departments, regions, and cloud services.
Without a structured DataOps approach, growth can create complexity, cost issues, duplicated pipelines, and unreliable reporting.
TheDataOps.org encourages teams to prepare for growth by standardizing pipeline development, improving automation, building observability, and training professionals in modern DataOps practices.
Benefits of Cloud-Based DataOps Platforms
Cloud-Based DataOps Platforms provide both technical and business benefits.
They help teams deliver better data faster while reducing operational risk.
Faster Data Delivery
Automated pipelines reduce delays in data processing.
Instead of waiting for manual extraction, cleaning, and loading, teams can deliver data continuously.
This helps business users make faster decisions.
Example:
A sales team can see updated revenue dashboards daily or hourly instead of waiting for weekly reports.
Improved Collaboration
DataOps encourages shared responsibility between teams.
Data engineers, analysts, cloud engineers, security teams, and business stakeholders can work with common standards.
This reduces confusion and improves trust.
Better Data Quality
Automated validation helps catch issues early.
Teams can detect missing data, schema changes, duplicate records, and abnormal values before they affect reports.
Better quality means better decisions.
Higher Scalability
Cloud platforms allow teams to scale storage and processing based on demand.
A cloud DataOps platform helps manage this scaling in a controlled way.
This is useful for seasonal businesses, high-volume analytics, and fast-growing enterprises.
Reduced Operational Costs
Automation reduces repetitive manual work.
Monitoring helps detect inefficient pipelines and unnecessary cloud resource usage.
Cost optimization becomes easier when teams can track resource consumption and pipeline performance.
Increased Business Agility
When data pipelines are automated and reliable, organizations can respond faster to business change.
They can launch new analytics, support new products, onboard new data sources, and improve customer insights more quickly.
Real-World Industry Applications
Cloud-based DataOps platforms are useful across many industries.
Banking and Financial Services
Banks handle large volumes of customer, transaction, risk, compliance, and fraud data.
Cloud DataOps can help with:
- Fraud detection pipelines
- Risk reporting
- Regulatory reporting
- Customer analytics
- Transaction monitoring
- Data quality control
For example, a bank may use DataOps automation to validate transaction data before it reaches fraud analytics systems.
Healthcare
Healthcare organizations manage patient records, appointment data, lab results, billing information, and operational reports.
Cloud DataOps can support:
- Patient analytics
- Hospital performance dashboards
- Claims processing
- Appointment trend analysis
- Data governance
- Quality reporting
Healthcare data needs strong privacy, accuracy, and governance. DataOps helps manage these requirements carefully.
Retail and E-Commerce
Retail businesses depend on customer behavior, product inventory, pricing, payment, delivery, and marketing data.
Cloud DataOps helps with:
- Customer segmentation
- Sales forecasting
- Inventory analytics
- Recommendation systems
- Campaign performance tracking
- Order pipeline monitoring
For example, an e-commerce company can use automated pipelines to update product availability and sales dashboards continuously.
Manufacturing
Manufacturing companies use data from machines, supply chains, quality checks, maintenance systems, and production lines.
Cloud DataOps can help with:
- Predictive maintenance
- Production monitoring
- Quality analytics
- Supply chain visibility
- Equipment performance tracking
This allows manufacturers to reduce downtime and improve operational planning.
Telecommunications
Telecom companies process huge volumes of network, customer, billing, usage, and service data.
Cloud DataOps supports:
- Network performance analytics
- Customer churn analysis
- Billing data validation
- Service quality monitoring
- Real-time usage reporting
Pipeline reliability is very important because telecom data is often high-volume and time-sensitive.
Media and Entertainment
Media companies use data from streaming platforms, user behavior, content libraries, advertising, and subscriptions.
Cloud DataOps helps with:
- Viewer analytics
- Content recommendation
- Subscription reporting
- Ad performance analysis
- Streaming quality monitoring
Reliable data helps media companies understand audience behavior and improve content strategy.
Traditional Data Management vs Cloud-Based DataOps Platforms
| Capability | Traditional Data Management | Cloud-Based DataOps Platforms |
|---|---|---|
| Deployment | Mostly on-premises | Cloud-native and hybrid |
| Pipeline Management | Manual | Automated |
| Scalability | Limited | Elastic |
| Collaboration | Department-focused | Cross-functional |
| Monitoring | Reactive | Continuous observability |
| Testing | Often manual | Automated and continuous |
| Governance | Policy-driven but separate | Built into workflows |
| Delivery Speed | Slower release cycles | Faster continuous delivery |
| Cost Visibility | Limited infrastructure tracking | Cloud usage and cost monitoring |
| Change Management | Manual approvals and scripts | Versioned and controlled deployment |
Traditional data management can still work for small and stable environments. However, modern enterprises need faster, more flexible, and more automated data operations.
Cloud-based DataOps platforms are better suited for dynamic cloud environments where data volume, users, systems, and business demands keep changing.
Common Challenges
Cloud-Based DataOps Platforms solve many problems, but they also require planning and discipline.
Data Silos
Data silos happen when departments store and manage data separately.
This creates duplicate work, inconsistent reports, and poor visibility.
Recommendation:
Create shared data standards, common data catalogs, and cross-functional ownership. Encourage teams to document data sources and transformation rules clearly.
Cloud Cost Management
Cloud platforms are flexible, but unmanaged usage can become expensive.
Pipelines may consume more compute than expected. Storage may grow quickly. Poorly optimized queries can increase costs.
Recommendation:
Track resource usage, monitor pipeline execution cost, optimize query performance, and schedule workloads based on business priority.
Security and Compliance
Data in the cloud must be protected carefully.
Enterprises need to manage access, encryption, audit logs, sensitive data, and compliance requirements.
Recommendation:
Use role-based access control, data classification, encryption, approval workflows, and regular audits. Governance should be part of pipeline design from the start.
Pipeline Complexity
As data systems grow, pipelines can become difficult to manage.
A single dashboard may depend on many upstream pipelines, transformations, and data sources.
Recommendation:
Use modular pipeline design, clear naming standards, lineage tracking, automated testing, and strong documentation.
Integration Across Multiple Cloud Services
Many organizations use multiple cloud services, SaaS platforms, databases, and analytics tools.
Integration can become complex when each tool has different formats, APIs, and access rules.
Recommendation:
Standardize integration patterns, use reusable connectors where possible, and monitor dependencies across services.
Best Practices
Successful DataOps is built through consistent engineering habits.
Use these best practices when working with cloud-based DataOps platforms:
- Automate repetitive workflows.
- Continuously monitor data quality.
- Standardize pipeline development.
- Implement strong governance.
- Optimize cloud resource utilization.
- Use version control for pipeline code.
- Create reusable pipeline templates.
- Define clear ownership for every pipeline.
- Set alerts for failures, delays, and quality issues.
- Document data lineage and business rules.
- Test pipeline changes before production release.
- Review cloud costs regularly.
- Keep security policies simple, visible, and enforceable.
- Build dashboards for operational visibility.
These practices help teams move from reactive data management to proactive data operations.
Key Metrics to Monitor
Cloud DataOps teams should measure both pipeline health and business impact.
Pipeline Success Rate
This shows how many pipeline runs complete successfully.
A low success rate means pipelines are unstable or poorly tested.
Data Freshness
Data freshness measures how recently data was updated.
For example, a dashboard may require data from the last hour. If the data is one day old, users may make poor decisions.
Data Accuracy
Data accuracy measures whether data matches expected rules and real-world meaning.
Accuracy checks may include totals, formats, ranges, and business validations.
Pipeline Execution Time
Execution time shows how long a pipeline takes to complete.
Long execution time may indicate growing data volume, slow queries, poor design, or limited compute resources.
Resource Utilization
Resource utilization tracks cloud compute, storage, memory, and processing usage.
It helps teams understand whether resources are underused, overloaded, or poorly configured.
Operational Cost Efficiency
Cost efficiency measures whether cloud spending is aligned with business value.
A pipeline may be technically successful but financially inefficient if it consumes too many resources without clear value.
Career Opportunities
Cloud-Based DataOps Platforms are creating strong career opportunities for professionals who understand data, automation, cloud platforms, and operations.
Common career roles include:
- DataOps Engineer: Builds automated, reliable, and monitored data workflows.
- Cloud Data Engineer: Designs and manages cloud-native data pipelines.
- Data Platform Engineer: Builds shared platforms for data engineering and analytics teams.
- Analytics Engineer: Transforms raw data into trusted analytics-ready models.
- Data Architect: Designs enterprise data architecture, governance, and integration strategy.
- Cloud Solutions Engineer: Helps organizations design and operate cloud-based data solutions.
Professionals who understand DataOps can work closely with engineering, analytics, security, DevOps, and business teams.
Important skills include:
- Cloud data platforms
- SQL and data modeling
- Data pipeline orchestration
- Automation scripting
- Data quality testing
- Observability
- Governance
- Cost optimization
- Collaboration and documentation
Future of Cloud-Based DataOps Platforms
The future of DataOps will be more automated, intelligent, and integrated.
AI-Assisted Data Operations
AI will help teams detect anomalies, recommend fixes, optimize pipelines, and identify data quality risks faster.
For example, AI-assisted DataOps may suggest why a pipeline failed or which upstream change caused a dashboard issue.
Serverless Data Pipelines
Serverless pipelines allow teams to run data workflows without managing infrastructure directly.
This can reduce operational burden and improve scalability when designed carefully.
Real-Time Analytics
Organizations increasingly need real-time or near-real-time insights.
Cloud DataOps platforms will support faster streaming pipelines, event-driven architecture, and continuous data processing.
Intelligent Data Governance
Governance will become more automated.
Platforms may help classify data, detect sensitive fields, track lineage, and enforce policies with less manual work.
Unified Data Platforms
Many enterprises are moving toward unified platforms that combine data lakes, warehouses, analytics, governance, machine learning, and observability.
Cloud-native DataOps will play a key role in connecting these capabilities into one reliable operating model.
Common Misconceptions
DataOps Is Only for Large Enterprises
This is not true.
Small and mid-sized companies also need reliable data pipelines, automation, and quality checks. DataOps can start small and grow with the organization.
Cloud Platforms Automatically Solve Data Quality Problems
Cloud platforms provide infrastructure, but they do not automatically create trusted data.
Teams still need testing, governance, validation, ownership, and monitoring.
Automation Eliminates Human Oversight
Automation reduces manual work, but human judgment remains important.
Data professionals still need to design workflows, review quality rules, investigate incidents, and improve architecture.
DataOps Is the Same as Data Engineering
Data engineering focuses on building pipelines and data systems.
DataOps is broader. It includes automation, collaboration, testing, monitoring, governance, deployment, and continuous improvement across the data lifecycle.
FAQ Section
- What is a cloud-based DataOps platform?
A cloud-based DataOps platform is a system that helps teams automate, manage, test, monitor, and improve data pipelines in cloud environments. It supports faster and more reliable data delivery. - Why are cloud-based DataOps platforms important?
They are important because modern businesses use large amounts of data from many sources. DataOps platforms help teams deliver trusted data faster with less manual effort. - Who uses cloud DataOps platforms?
Data engineers, analysts, cloud engineers, data architects, BI developers, DevOps teams, and enterprise IT teams use cloud DataOps platforms to manage data workflows. - How is DataOps different from traditional data management?
Traditional data management is often manual and slower. DataOps uses automation, testing, monitoring, and collaboration to improve data delivery and reliability. - Do cloud DataOps platforms improve data quality?
Yes. They can improve data quality by adding automated checks for missing values, duplicates, schema changes, wrong formats, and unusual data patterns. - Can small companies use DataOps?
Yes. DataOps is not only for large enterprises. Small companies can start with simple automated pipelines, basic monitoring, and clear data ownership. - What skills are needed for a DataOps career?
Important skills include SQL, cloud data platforms, pipeline automation, data quality testing, orchestration, observability, governance, and basic scripting. - Are DataOps and DevOps connected?
Yes. DataOps takes many ideas from DevOps, such as automation, version control, continuous delivery, testing, and monitoring, and applies them to data workflows. - What are common DataOps challenges?
Common challenges include data silos, cloud costs, security, compliance, pipeline complexity, and integration across many cloud services. - How can beginners start learning cloud DataOps?
Beginners can start by learning data pipelines, SQL, cloud storage, data warehouses, orchestration, data quality checks, and basic automation concepts.
Final Summary
Cloud-Based DataOps Platforms are becoming essential for modern data ecosystems. They help organizations manage data pipelines with automation, scalability, monitoring, governance, and continuous improvement. Instead of depending on manual processes, teams can build reliable cloud data pipelines that deliver trusted information to business users faster. The real value of cloud-native DataOps is not only technology. It is the combination of better processes, stronger collaboration, automated testing, continuous monitoring, and clear ownership.