Introduction
Modern organizations deal with a massive influx of data from applications, IoT devices, and cloud services. Managing these data volumes requires speed, accuracy, and agility. Traditional data workflows often struggle to keep pace with this rapid growth. AI-powered DataOps represents the next evolution of intelligent data operations. By embedding machine learning models and cognitive automation into data engineering workflows, systems can self-heal, adapt to changes, and flag anomalies automatically. This shift turns data infrastructure from a passive delivery network into a proactive asset. To help technical professionals navigate this transition, resources like TheDataOps.org provide foundational learning paths, frameworks, and community insights. Utilizing these educational tools ensures teams can deploy automation strategies effectively across their entire enterprise data footprint.
What Is AI in DataOps Pipelines?
AI in DataOps refers to embedding machine learning models, statistical algorithms, and automated orchestration into data lifecycles. Instead of relying only on static scripts, these workflows use data-driven insights to manage, clean, and optimize information flows.
The core objectives of adding AI tools for DataOps include:
- Eliminating manual pipeline adjustments.
- Identifying hidden data quality issues before they reach production.
- Optimizing cloud resource allocation during intensive processing.
- Accelerating the time-to-value for analytical insights.
[Raw Data Sources] ---> [AI-Powered Ingestion & Cleansing] ---> [Self-Healing Transformations] ---> [Automated Delivery]
^ |
|------------ AI Anomaly Detection ----|
Key technologies driving this shift include predictive analytics, natural language processing (NLP) for metadata cataloging, and anomaly detection algorithms. Enterprises adopt AI-driven data engineering to handle modern scale, lower cloud infrastructure costs, and minimize downtime caused by broken pipeline segments.
Fundamentals of DataOps Pipelines
To understand how artificial intelligence enhances data infrastructure, we must first look at the core stages of a standard DataOps pipeline:
+-----------+ +------------+ +----------------+ +-------------+ +----------+ +----------+
| Ingestion | --> | Validation | --> | Transformation | --> | Integration | --> | Testing | --> | Delivery |
+-----------+ +------------+ +----------------+ +-------------+ +----------+ +----------+
^ |
+---------------------------------- Continuous Monitoring <-------------------------------------+
Data Ingestion
This stage extracts raw structured, semi-structured, or unstructured information from external sources and loads it into a storage layer like a data lake or warehouse.
Data Validation
Data validation checks the incoming assets against structural templates, schemas, and predefined formatting constraints to ensure structural consistency.
Data Transformation
Raw inputs are cleaned, denormalized, aggregated, and structured into usable formats for analytics tools and business intelligence dashboards.
Data Integration
This phase combines disparate data sets from different business units, resolving matching identities and unifying schemas into a single source of truth.
Data Testing
Automated unit tests and regression test suites run across data sets to verify accuracy, calculate metrics, and confirm logic before deployment.
Data Delivery
Cleaned and verified records travel safely to target endpoints, such as operational databases, business intelligence tools, or data science modeling environments.
Continuous Monitoring
Orchestrators track system performance, execution times, job failures, and data volume shifts to alert engineering teams of processing issues.
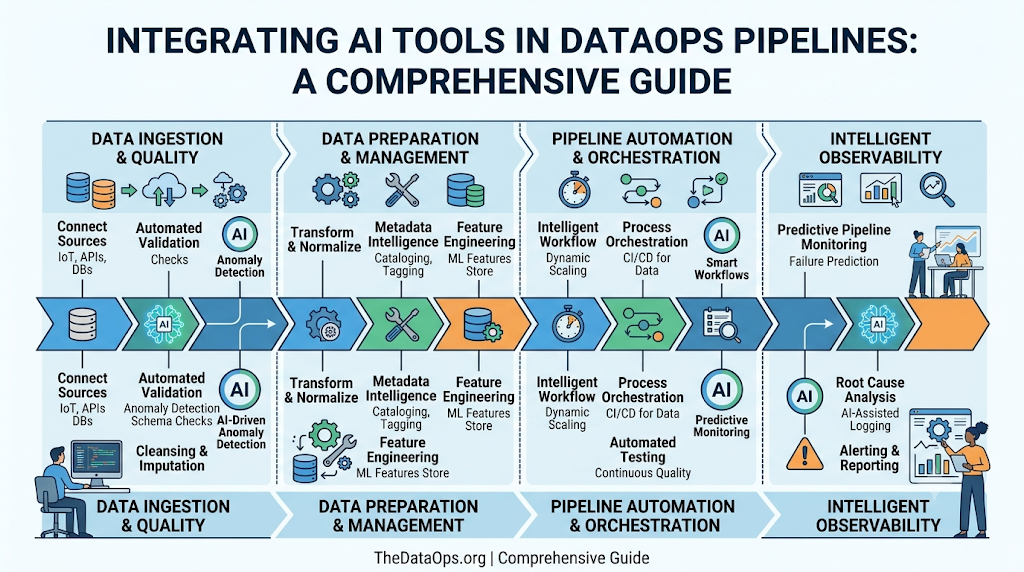
Integrating AI Tools in DataOps Pipelines
Integrating AI tools in DataOps pipelines changes how data teams build, monitor, and maintain enterprise platforms. Below are the key capabilities realized through this integration.
Intelligent Data Quality Validation
Instead of writing thousands of row-level SQL rules to validate incoming files, machine learning models learn the historical profile of your data.
For example, if an enterprise financial pipeline receives a daily transaction file, an AI model automatically reviews the row counts, null distributions, and value ranges. If the null rate for a specific column spikes from 0.1% to 5%, the system flags it without a developer writing an explicit rule.
Automated Data Cleansing
AI tools can automatically correct syntax errors, impute missing values using predictive patterns, and standardize addresses or naming variations.
If a retail pipeline receives inconsistent customer location text like “N.Y.”, “NY”, and “New York”, an embedded NLP model standardizes these records automatically. This saves engineers from maintaining fragile string-mapping functions.
AI-Based Anomaly Detection
Machine learning algorithms analyze streaming telemetry to spot unusual patterns that point to software bugs, security issues, or system errors.
In an enterprise IoT pipeline processing telemetry from manufacturing equipment, isolation forests or autoencoders can flag out-of-range temperature readings. This triggers data quarantines before corrupted metrics skew predictive maintenance dashboards.
Predictive Pipeline Monitoring
By analyzing historical metadata, AI engines predict when a data pipeline job might fail or experience significant delays.
If a cloud data warehouse materialization job typically runs for twenty minutes, an AI monitor flags an issue if the execution passes thirty minutes. This alert triggers early, before an actual out-of-memory timeout occurs.
[Normal Execution: 20 mins] ----------> Check Baseline
[Current Execution: 32 mins] ---------> AI Flags Outlier Alert (Before Out-Of-Memory Crash)
Smart Workflow Automation
Intelligent orchestrators dynamically adjust pipeline schedules and allocate computing power based on fluctuating data volumes and warehouse workloads.
During seasonal e-commerce events like Black Friday, an AI-driven data engineering system scales up processing clusters in advance. It then scales them back down when traffic decreases, preventing expensive cloud over-provisioning.
Metadata Intelligence
AI automatically scans data tables, infers business context, assigns semantic tags, and maps data lineage links across enterprise environments.
An enterprise tool can analyze database structures to tag columns containing Personally Identifiable Information (PII) like social security numbers or credit cards. This ensures immediate adherence to compliance standards without requiring manual human audits.
AI-Assisted Root Cause Analysis
When an orchestration job fails, AI tools analyze stack traces, system logs, and recent code modifications to point out the underlying issue.
Instead of an engineer spending hours combing through cloud logs, an AI model identifies that an upstream database migration added a column that broke downstream transformation scripts, suggesting the exact patch needed.
TheDataOps.org Guide to AI-Driven DataOps Pipelines
Building robust, intelligent data pipelines requires a methodical framework. This section highlights the core focus areas for shifting toward AI-powered DataOps.
Building Intelligent Data Pipelines
Transitioning from static to intelligent data pipelines involves deploying tools that observe, learn, and adjust automatically. Organizations should focus on adding modular machine learning components into ingestion layers. These components extract schema metadata dynamically, allowing systems to handle upstream schema drift without manual interventions.
Improving Data Reliability
Data reliability relies on continuous checks. By introducing machine learning models into your validation steps, you can score data health in real time. Suspicious inputs route directly to quarantine zones for review, while clean records move forward. This ensures downstream applications always receive verified information.
Automating Repetitive Data Engineering Tasks
Data engineers often spend valuable time on repetitive work like writing documentation, generating boilerplate SQL, and setting up environments. AI automation tools handle these administrative tasks, allowing developers to focus on architecture, performance tuning, and high-value data initiatives.
Scaling Enterprise Data Operations
As an enterprise grows, managing thousands of data pipelines across various cloud environments becomes complex. AI-driven data engineering acts as an automated operational layer. It manages compute resources, balances query workloads, and resolves resource contention across global platforms automatically.
Preparing for AI-Enabled Data Platforms
To prepare for advanced AI-driven platforms, enterprises must treat data assets as ready for machine learning. This requires maintaining clear metadata catalogs, enforcing precise tracking, and ensuring data pipelines deliver high-quality inputs to internal machine learning models.
Benefits of AI Integration in DataOps
BENEFITS OF AI IN DATAOPS
+--------------------+ +--------------------+
| Fast Processing | | High Accuracy |
| Accelerates engine | | Keeps downstream |
| execution speeds. | | analytics clean. |
+--------------------+ +--------------------+
| |
v v
+--------------------+ +--------------------+
| Reduced Manual Work| | Strong Reliability |
| Frees engineers up | | Self-healing loops |
| for complex tasks. | | prevent downtime. |
+--------------------+ +--------------------+
- Faster Data Processing: Intelligent workloads clear bottlenecks, balance system queries, and accelerate processing speeds.
- Improved Data Accuracy: Automated cleansing and anomaly detection stop bad data from reaching production tables, keeping downstream analytics clean.
- Better Operational Efficiency: Data engineering teams spend less time fixing broken workflows and more time deploying new capabilities.
- Reduced Manual Effort: Automated testing and monitoring cut down on repetitive maintenance work.
- Enhanced Decision-Making: Business leaders receive fresh, high-quality information faster, making strategic forecasting more reliable.
- Greater Pipeline Reliability: Self-healing data infrastructure routes around system dependencies and network glitches, preventing pipeline downtime.
Real-World Industry Applications
Banking and Financial Services
Financial institutions process millions of global credit transactions every second. AI-driven pipelines find odd transaction clusters, flag fraud attempts instantly, and normalize data from international banking systems for regulatory audits.
Healthcare
Hospital networks use intelligent pipelines to merge patient records from different clinics, clean unstructured doctor notes, and format clinical trial data securely while complying with strict healthcare privacy standards.
Retail and E-Commerce
Global retailers deploy automated workflows to combine inventory levels, digital point-of-sale logs, and web behavior analytics. This gives logistics teams accurate data to adjust supply chain volumes dynamically.
Manufacturing
Industrial factories use automated pipelines to process continuous streaming sensor data from production lines. AI tools clean missing readings and fuel predictive maintenance systems that help avoid expensive machine breakdowns.
Telecommunications
Telecom companies use intelligent observability to handle massive volumes of call detail records. The system flags cell tower drops and balances network traffic paths to maintain consistent service quality during peak hours.
Cloud-Based Analytics Platforms
Modern cloud data ecosystems use machine learning to optimize query plans, index large datasets automatically, and clean cold storage spaces to reduce monthly infrastructure costs.
Traditional DataOps vs. AI-Enhanced DataOps
| Capability | Traditional DataOps | AI-Enhanced DataOps |
|---|---|---|
| Data Quality | Rule-based validation | Intelligent quality monitoring |
| Pipeline Monitoring | Manual dashboards | AI-driven observability |
| Error Detection | Reactive | Predictive |
| Workflow Automation | Limited | Intelligent automation |
| Root Cause Analysis | Manual investigation | AI-assisted analysis |
Common Implementation Challenges
Poor Data Quality
If historical operational logs are messy, AI tools may struggle to establish accurate performance baselines.
- Recommendation: Clean your historical metadata first and use semi-supervised models that learn from verified, high-quality production runs.
Legacy System Integration
Older on-premises mainframes and data warehouses often lack modern APIs to connect easily with AI tools.
- Recommendation: Use lightweight data abstraction layers or cloud change-data-capture (CDC) tools to stream legacy data into modern systems.
AI Model Training
Machine learning models can drift over time, leading to false positives or missed anomalies.
- Recommendation: Set up regular automated retraining loops for your monitoring models using the latest pipeline performance metrics.
Data Governance
Automated data modifications can raise compliance concerns if changes lack clear documentation.
- Recommendation: Ensure all AI cleansing actions write to an open metadata ledger, providing clear documentation of every change.
Organizational Adoption
Data teams may hesitate to trust automated decisions or change their established workflows.
- Recommendation: Introduce automated features gradually—start with alerts and suggestions before enabling self-healing, automated adjustments.
Best Practices
- Standardize data governance policies: Set clear boundaries for data ownership, access controls, and compliance rules before deploying automation.
- Automate repetitive pipeline processes: Focus on automating time-consuming tasks first, like schema validation and infrastructure scaling.
- Continuously monitor AI model performance: Track your operational models to ensure they remain accurate as data volumes evolve.
- Maintain high-quality metadata: Well-organized metadata catalogs provide the necessary context for AI engines to analyze your workflows.
- Encourage collaboration across data teams: Bring engineers, data scientists, and analysts together to align pipeline development with overall business goals.
Key Performance Metrics
To judge the success of your implementation, track these key metrics:
$$Pipeline\ Success\ Rate = \left( \frac{Successful\ Executions}{Total\ Executions} \right) \times 100\%$$
- Data Quality Score: The percentage of records that pass structural check suites without triggering errors.
- Processing Latency: The total time it takes for data to travel from initial ingestion to its final destination.
- Pipeline Throughput: The total volume of data records processed by your system per minute or hour.
- Data Freshness: The time elapsed since the data point was recorded in the source system versus its availability in production.
- Mean Time to Recovery (MTTR): The average time required for your team to restore operations after a pipeline failure occurs.
Career Opportunities
- DataOps Engineer: Designs and maintains the infrastructure, deployment pipelines, and automation tools supporting data delivery.
- Data Engineer: Builds data architectures, transformations, and ingestion models that feed downstream applications.
- Machine Learning Engineer: Deploys and manages the automated models that monitor and optimize operational pipelines.
- Analytics Engineer: Cleans and transforms raw data into structured, well-documented assets for business intelligence use.
- Cloud Data Engineer: Specializes in building, scaling, and optimizing data operations across cloud environments.
- Enterprise Data Architect: Designs the high-level frameworks, governance standards, and systems that manage corporate data assets.
Future of AI-Driven DataOps
The future of data operations points toward fully autonomous pipelines. These systems will detect new source data, build their own transformation models, and repair code bugs without human intervention.
AI-powered data governance will also become standard, with automated systems managing data privacy compliance across global networks in real time. As intelligent metadata management grows, platforms will automatically document operations and optimize data layouts to keep cloud infrastructure fast and cost-effective.
Common Misconceptions
- AI Eliminates Data Engineers: AI handles routine maintenance and monitoring, freeing engineers to focus on architecture, system design, and complex data strategies.
- AI Automatically Fixes Every Data Issue: Machine learning models rely on clear configurations and high-quality training inputs; they require human guidance to align with specific business goals.
- AI Is Only Useful for Large Enterprises: Small and mid-sized businesses can use modular, open-source AI tools to automate operations and scale efficiently without a massive budget.
- DataOps Is Only About Automation: Automation is a major component, but successful DataOps also requires collaboration, strong governance, and well-designed data workflows.
FAQ Section
1. What is the main difference between traditional DataOps and AI-driven DataOps?
Traditional DataOps relies on static rules and manual interventions to manage data pipelines. AI-driven DataOps integrates machine learning models to automate tasks like anomaly detection, schema drift adaptation, and resource scaling, making the system adaptive and self-healing.
2. How do AI tools improve data quality in enterprise engineering pipelines?
AI tools analyze historical data to establish normal baseline profiles. They can automatically flag outliers, detect high null rates, and fix formatting inconsistencies without requiring developers to write explicit, hardcoded validation rules.
3. Can AI-powered DataOps pipelines handle unstructured data formats?
Yes, by using integrated natural language processing (NLP) and computer vision models, these pipelines extract structural metadata from text files, PDFs, and images, converting unstructured content into clean tables for analytics.
4. Will integrating AI tools replace the need for data engineering teams?
No, AI handles repetitive tasks like basic troubleshooting, routine validation, and log monitoring. This allows data engineers to focus on more impactful work, like optimizing system architecture and building new data products.
5. What is predictive pipeline monitoring?
Predictive pipeline monitoring uses historical metadata to predict potential failures, data bottlenecks, or processing delays, allowing teams to address infrastructure issues before they cause system downtime.
6. How does schema drift impact automated data pipelines, and can AI fix it?
Schema drift happens when upstream source systems change database structures without warning. AI tools handle this by detecting the structural changes, adjusting downstream mappings automatically, and alerting engineers without crashing the pipeline.
7. Is it expensive for a growing company to add AI tools to DataOps?
While there are initial setup costs, many open-source tools and cloud services offer modular, pay-as-you-go pricing. The long-term savings from reduced manual work and lower downtime often outweigh the initial investment.
8. How do AI tools help optimize cloud infrastructure costs?
AI tools analyze processing workloads to scale compute clusters up during peak demand and down during quiet hours. This prevents over-provisioning and reduces monthly cloud infrastructure expenses.
9. What role does metadata play in intelligent data operations?
Metadata serves as the foundational data for AI tools. It provides the historical context, execution logs, and data lineage paths that machine learning models need to analyze and optimize your pipelines.
10. How should an enterprise start transitioning to AI-powered DataOps?
Start small by adding AI monitoring or anomaly detection to a single data workflow. Once your team builds trust in the automated insights, you can gradually expand those capabilities across your broader platform.
Final Summary
Integrating AI tools in DataOps pipelines helps modern enterprises manage growing data complexity efficiently. Moving away from rigid, rule-based workflows allows organizations to build adaptable, intelligent systems that improve data quality, automate routine tasks, and handle infrastructure issues before they cause downtime. Emphasizing strong data governance, continuous monitoring, and structured metadata management helps teams maintain reliable, high-performing platforms. For data professionals looking to stay ahead, resources like TheDataOps.org offer valuable frameworks and educational materials to master these automation skills.