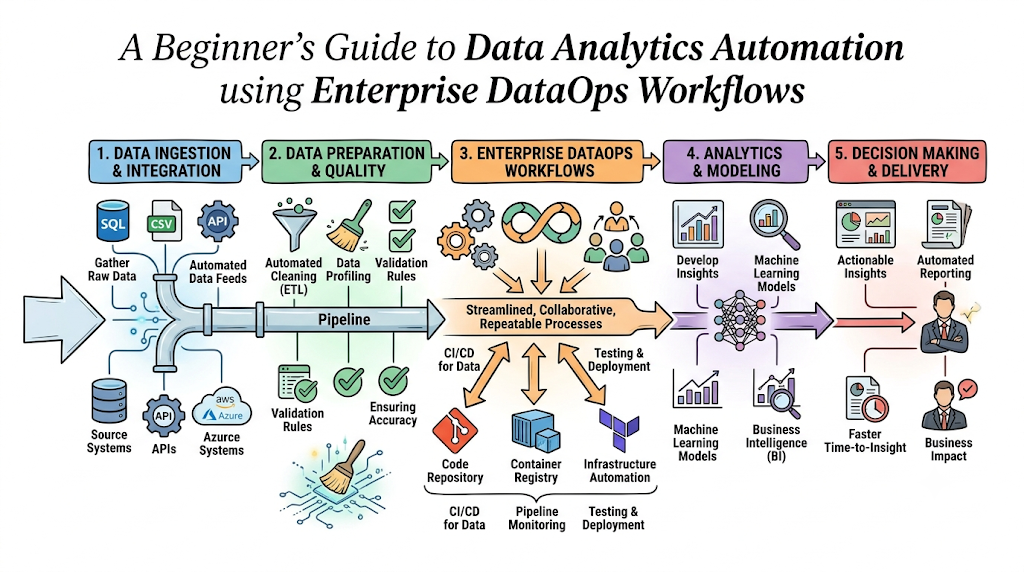
Organizations rely heavily on fast, accurate, and reliable business intelligence to make critical commercial decisions. Whether it is predicting customer churn or managing real-time inventory levels, business leaders demand data that is fresh and trustworthy. Yet traditional analytics workflows often crack under this pressure. Historically, data delivery was plagued by rigid silos, where data engineers built pipelines in isolation, analysts wrote custom scripts that frequently broke, and business teams made decisions based on stale or broken dashboards. This friction is where DataOps steps in. DataOps is an operational methodology that applies agile development, DevOps principles, and statistical process controls to data pipelines. By treating data workflows as production software, DataOps bridges the gap between data creation and consumption. As an educational learning resource, TheDataOps.org helps organizations transition from fragile, manual tasks to highly resilient automated workflows. In this guide, you will learn how adopting enterprise DataOps practices and tools transforms data pipelines from a liability into a competitive business advantage.
What Is DataOps in Analytics?
DataOps (Data Operations) is a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and data consumers across an organization.
Featured Snippet Definition: DataOps is a process-oriented methodology that combines agile development, DevOps engineering practices, and automated quality controls to streamline the design, deployment, and management of data flows throughout the analytics lifecycle.
The core objectives of DataOps include:
- Reducing Cycle Time: Shrinking the timeframe between an initial business request and the deployment of a validated analytical insight.
- Ensuring High Data Quality: Shifting testing to the left so that anomalies are caught early in the pipeline before they impact executive dashboards.
- Fostering Collaboration: Eliminating operational silos between data engineers, analytics engineers, data scientists, and business professionals.
As analytics ecosystems migrate to complex, hybrid-cloud environments, modern analytics platforms require a structured framework to maintain consistency. Without DataOps, scaling a data lakehouse or real-time streaming environment results in manual troubleshooting, lost data context, and declining organizational trust.
Fundamentals of Analytics Delivery
Before examining how tools optimize the system, it helps to understand the standard components of a modern analytics delivery lifecycle. Each stage represents a potential point of failure if managed manually.
Data Collection
The journey begins by ingesting structured, semi-structured, or unstructured data from diverse source systems, including CRMs, ERPs, production databases, third-party APIs, and IoT sensors.
Data Integration
Fragmented data streams are brought together into a centralized staging area or data lakehouse environment. This step ensures that data points from disparate sources can be reconciled.
Data Transformation
Raw ingredients are turned into consumption-ready datasets. Data engineers clean up null values, normalize schemas, mask sensitive fields like personally identifiable information (PII), and apply business logic definitions.
Data Validation
Data validation ensures that data conforms to pre-defined rules. It checks schemas, balance constraints, and reference logic before the datasets are loaded into presentation layers.
Analytics Processing
The clean data is processed at scale. Advanced models, predictive calculations, and aggregation engines compile the underlying tables that drive organizational metrics.
Dashboard Delivery
The final stage presents the refined data to business users through interactive reporting tools, semantic layers, and automated data applications, enabling self-service exploration.
How DataOps Improves Analytics Delivery with Tools
Deploying a DataOps strategy requires moving away from human monitoring toward automated engineering workflows. Here is a breakdown of how enterprise software tools optimize each phase of the pipeline.
Automated Data Pipelines
Manual extraction scripts are notoriously brittle. Enterprise DataOps tools automate data ingestion and schema discovery, allowing pipelines to dynamically handle source modifications. For example, if an upstream application introduces a new column to a checkout table, automated pipelines absorb the structural shift without crashing downstream reports.
Continuous Data Testing
DataOps applies Continuous Integration and Continuous Deployment (CI/CD) to analytics code. When an analytics engineer modifies a SQL transformation query, the code change automatically triggers a battery of regression tests in an isolated staging sandbox. This approach verifies that the update will not break existing production reporting before it is merged.
Pipeline Orchestration
Complex data platforms feature highly interdependent workflows—for instance, a financial summary table cannot run until the daily marketing ledger and sales receipts are fully integrated. Orchestration tools act as the central brain, managing these dependencies, organizing job execution orders, and executing automated retries if a network connection drops.
Data Quality Monitoring
Rather than waiting for an executive to spot an empty chart, data observability tools constantly monitor live data volume, freshness, and distribution patterns. If a daily ingestion batch drops from 100,000 rows to 4,000 rows, an anomaly alert triggers instantly, pausing the affected workflow before bad data reaches the business layer.
Metadata Management
Understanding data lineage—the journey a data point takes from source system to final KPI—is vital for governance. DataOps tools capture metadata automatically, building visual maps that show which tables feed into specific dashboard panels. This makes impact analysis straightforward when an upstream field needs to be deprecated.
Collaboration Between Data Teams
By utilizing Git repositories as a single source of truth for pipeline architectures, engineering and business teams speak the same language. Code reviews, documentation platforms, and standardized environment templates allow engineers, analysts, and data scientists to build upon each other’s work without overwriting scripts.
Automated Analytics Deployment
Infrastructure as Code (IaC) allows data teams to provision identical development, testing, and production environments instantly. When code passes testing parameters, automated release pipelines deploy the changes to production with zero downtime, using instant rollbacks if unexpected bugs materialize post-deployment.
TheDataOps.org Guide to Analytics Delivery
Implementing DataOps requires a structured framework focused on operational maturity. TheDataOps.org emphasizes five key pillars for optimizing enterprise analytics delivery:
- Building Reliable Analytics Pipelines: Shift from reactive troubleshooting to proactive pipeline design. Build modular, reusable code structures that allow data pipelines to scale horizontally as business needs evolve.
- Improving Data Quality: Embed testing logic throughout the pipeline, not just at the final destination. By verifying row counts, null rates, and primary key constraints early in the extraction phase, bad data is quarantined before it corrupts downstream models.
- Accelerating Analytics Delivery: Shorten the cycle time from feature ideation to live implementation. Use version-controlled environments to let teams safely test new models simultaneously without risking production stability.
- Scaling Enterprise Data Platforms: Replace manual operations with automated orchestration layer logic. This enables engineering teams to support petabyte-scale lakehouses and high-frequency streaming systems without a linear increase in maintenance headcount.
- Creating Data-Driven Organizations: Foster true self-service analytics by delivering a highly accurate data catalog and a robust semantic layer. When business professionals trust the accuracy of their dashboards, they confidently base their daily operations on real-time insights.
Popular DataOps Tools for Analytics
The DataOps market contains specialized solutions designed to handle specific parts of the pipeline infrastructure.
+-------------------------------------------------------------------------+
| ORCHESTRATION & COMPUTE LAYER |
| [Apache Airflow] --> [Snowflake / Databricks] |
+-------------------------------------------------------------------------+
|
v
+-------------------------------------------------------------------------+
| TRANSFORMATION & VALIDATION |
| [dbt] --> [Great Expectations / Kafka] |
+-------------------------------------------------------------------------+
|
v
+-------------------------------------------------------------------------+
| PRESENTATION LAYER |
| [Power BI] <----> [Tableau] |
+-------------------------------------------------------------------------+
Apache Airflow
An open-source workflow orchestration platform used to programmatically author, schedule, and monitor data pipelines. Airflow allows teams to write pipelines as Python code, offering extensive plugin support and scalability for highly complex enterprise dependencies.
dbt (Data Build Tool)
A development framework focused entirely on the transformation layer inside data warehouses. dbt enables data and analytics engineers to write modular SQL transformation queries, auto-generate documentation, and run integrated schema tests directly within version-controlled repositories.
Apache Kafka
A distributed event-streaming platform built for high-performance, real-time data pipelines. Kafka acts as a durable, decoupled message broker that safely ingests millions of events per second from live applications and forwards them to analytics processing engines.
Great Expectations
A dedicated open-source data validation tool that assists teams in maintaining data quality. It enables engineers to define explicit test assertions (known as “Expectations”) such as checking if a column value falls within a specific range, automatically creating data documentation and validation reports.
Snowflake
A cloud-native data platform built on a decoupled compute and storage architecture. Snowflake provides enterprise-scale warehousing, automated scaling, zero-copy cloning for rapid environment management, and data sharing capabilities with zero operational overhead.
Databricks
A unified data and AI platform designed around a lakehouse architecture. Databricks combines the structured query speed of a data warehouse with the massive processing capacity of a data lake, allowing engineering, streaming, and machine learning models to run on a single platform.
Microsoft Power BI
A prominent business intelligence and visualization platform designed for data democratization. Power BI provides business teams with drag-and-drop analytics, robust data modeling options, and secure data access governance across enterprise ecosystems.
Tableau
An analytics application famous for deep data visualization and exploratory analysis. Tableau integrates directly with modern cloud warehouses, enabling non-technical business professionals to quickly uncover complex trends through dynamic dashboards.
Benefits of DataOps for Analytics
Shifting from standard data management methods to an automated DataOps strategy provides significant enterprise benefits:
- Faster Analytics Delivery: Automation removes human dependencies from deployment steps, letting data teams release production updates in minutes rather than weeks.
- Improved Data Accuracy: Continuous monitoring and automated data validation rules isolate anomalies early, keeping broken or misleading data out of business reports.
- Better Collaboration: Version control structures, clear data lineage, and unified technical workflows align engineers, analysts, and business users on shared corporate goals.
- Increased Automation: Automating repetitive jobs like schema validation, data loading, and alerts allows data engineering specialists to focus on high-value system design.
- Reduced Operational Costs: Removing manual pipeline troubleshooting saves hours of developer time while cloud performance optimization tools minimize unnecessary cloud compute bills.
- Better Business Decisions: High-speed data ingestion and reliable pipeline up-time provide leadership teams with real-time, accurate numbers to navigate volatile markets confidently.
Traditional Analytics vs. DataOps-Driven Analytics
| Feature | Traditional Analytics | DataOps-Driven Analytics |
| Data Processing | Deeply manual, reliant on hand-crafted custom scripts | Highly automated via orchestrated pipeline tooling |
| Quality Assurance | Periodic, ad-hoc checks often triggered after errors occur | Continuous, automated testing integrated directly into pipelines |
| Collaboration | Disconnected, siloed engineering and analyst teams | Cross-functional collaboration managed with version control |
| Deployment | Slow, manual releases with a high risk of downtime | Automated CI/CD execution enabling continuous delivery |
| Scalability | Rigid, limited by infrastructure constraints and developer hours | Agile, built on elastic cloud platforms and repeatable code |
Common Challenges & How to Overcome Them
Poor Data Quality
- The Challenge: Incoming raw data contains duplicate rows, inconsistent schemas, and missing entries, leading to incorrect calculations down the line.
- The Solution: Shift testing left. Implement data validation engines directly at the ingestion boundary to catch and isolate bad data rows before they flow into core processing tables.
Legacy Analytics Systems
- The Challenge: Monolithic, on-premises data warehouses cannot scale alongside rising modern data volumes and are difficult to automate.
- The Solution: Gradually migrate to modern, cloud-native data lakehouse solutions that naturally support API integrations, automated scaling, and isolated compute workloads.
Integration Complexity
- The Challenge: Combining data from dozens of disparate SaaS systems, internal operational engines, and cloud databases results in complex pipeline dependencies.
- The Solution: Deploy an orchestration framework like Apache Airflow to centralize data workflows, visualize pipeline dependencies, and manage automated retry tasks systematically.
Governance Challenges
- The Challenge: Expanding access to analytical systems increases the risk of data leaks, compliance penalties, and unmapped sensitive information.
- The Solution: Implement automated policy enforcement tools and data masking capabilities directly inside your transformation workflows to guarantee steady compliance.
Skill Gaps
- The Challenge: Traditional analytics teams may lack the software engineering expertise required to build advanced CI/CD and automated infrastructure.
- The Solution: Leverage educational guides and learning repositories like TheDataOps.org to train data professionals on core version-control concepts, data testing frameworks, and pipeline automation tools.
Best Practices for DataOps Implementation
To build an efficient and scalable DataOps practice, prioritize these five fundamental strategies:
- Automate Repetitive Workflows: Avoid manual file loads, custom one-off extractions, and hardcoded variables. Use automated data tools to handle ingestion, scheduling, and error alerting.
- Continuously Validate Data Quality: Treat data validation as a constant requirement. Add automated testing parameters at every step of the pipeline journey to ensure data consistency.
- Standardize Analytics Processes: Establish shared SQL and Python styling standards, code review processes, and deployment strategies to maintain project clarity across different development teams.
- Maintain Strong Metadata Management: Keep an updated data catalog and automated lineage logs so any user can instantly check where a specific data metric originates.
- Encourage Cross-Functional Collaboration: Break down traditional operational walls by having data engineers, analytics specialists, and business analysts use shared code repositories and collaborative platforms.
Key Performance Metrics
Tracking specific operational metrics helps gauge the efficiency of a DataOps architecture:
- Data Freshness: The time elapsed from when an event occurs in a source system to when it reflects inside a production dashboard.
- Pipeline Success Rate: The percentage of scheduled pipeline runs that complete successfully without manual intervention or structural crashes.
- Analytics Delivery Time: The average cycle time required to design, test, and push a new analytical report or feature live to business users.
- Data Quality Score: The percentage of data rows that successfully pass all automated validation tests and corporate schema requirements.
- Dashboard Availability: The overall uptime percentage of customer- and executive-facing reporting platforms within defined service level agreements (SLAs).
- Mean Time to Recovery (MTTR): The average time it takes for data engineering specialists to identify, fix, and resolve a pipeline failure after an alert triggers.
Career Opportunities in the DataOps Space
The rapid expansion of DataOps-driven analytics has generated high demand for skilled technical professionals.
DataOps Engineer
A specialized systems engineer who designs and maintains CI/CD infrastructure, automated testing frameworks, and orchestrators for corporate data architectures.
Analytics Engineer
A modern data professional sitting between data engineering and business intelligence. They write modular, tested transformation code in dbt and manage clean semantic layers.
Data Engineer
The structural architect who constructs scalable data pipelines, implements ingestion logic, and manages enterprise lakehouse storage platforms.
Business Intelligence Engineer
An expert focused on modeling enterprise data assets, building performant analytical schemas, and delivering interactive reporting solutions for business strategies.
Data Platform Engineer
An engineering specialist dedicated to maintaining the health, performance optimization, and scale of cloud computing storage environments and data frameworks.
Cloud Data Architect
A senior technology strategist who designs the end-to-end cloud ecosystem, selecting appropriate tool integration pathways and ensuring governance.
Future of DataOps Analytics
As data scale accelerates, the core principles of DataOps continue to evolve alongside cutting-edge infrastructure trends.
AI-Assisted Analytics
Generative AI copilots are transforming data analysis, enabling business teams to explore data catalogs and auto-generate report syntax using natural language interfaces.
Intelligent Data Pipelines
Modern platforms leverage embedded machine learning algorithms to automatically detect incoming schema drift, optimize query execution, and flag unique anomalies without requiring manual threshold settings.
Real-Time Analytics
The industry is shifting from daily batch intervals toward constant event-stream processing. This real-time visibility allows enterprise systems to calculate risk and adjust pricing dynamics within milliseconds.
Autonomous Data Operations
Advanced pipelines can now independently resolve basic quality incidents. If an ingestion batch fails, the system pauses the affected pipeline segment, re-fetches data from the source application, and resumes processing without human intervention.
Self-Service Analytics Platforms
By combining a robust semantic layer with automated metadata indexing, business professionals can discover datasets and build compliant visualizations independently, removing old engineering bottlenecks.
Common Misconceptions About DataOps
- DataOps Is Only for Large Enterprises: While massive corporations gain clear benefits from automation, mid-sized teams face identical data quality challenges. Implementing basic version control and simple testing saves time regardless of organization size.
- DataOps Is Just Another ETL Tool: DataOps is an overall methodology combining human culture, iterative processes, and automation software. It cannot be bought off the shelf as a single application.
- Automation Eliminates Human Expertise: Automation simply clears out boring, repetitive maintenance tasks like manual validation checking. This allows engineers to dedicate their energy to strategic platform development.
- Analytics Quality Depends Only on Dashboards: A dashboard is merely a mirror reflecting your underlying data asset. If your collection, staging, and transformation stages lack automated testing, the most beautiful visualization tool will still present bad information.
FAQ Section
- What is the difference between DevOps and DataOps?
DevOps focuses on optimizing the development, deployment, and testing of software application code. DataOps adapts those exact principles but applies them specifically to data flows, data pipeline code, and continuous data quality monitoring across analytics ecosystems. - Does implementing DataOps require replacing all our current data tools?
Not at all. DataOps is an operational framework that prioritizes automation, testing, and collaboration. You can implement DataOps practices by introducing tools like dbt for transformation or Great Expectations for quality control directly into your existing infrastructure. - Why is data testing so important in a DataOps workflow?
Data testing ensures that anomalies, broken values, and structural schema changes are caught automatically at the ingestion boundary. This prevents corrupted data from entering downstream processing tables where it could ruin your dashboard calculations. - What role does Apache Airflow play in analytics delivery?
Apache Airflow acts as the centralized brain for pipeline orchestration. It maps out complex workflow execution orders, manages step dependencies, tracks process logs, and fires off automated alerts if an integration task encounters an issue. - How does DataOps help non-technical business users?
DataOps ensures that the dashboards and reporting tools used by business teams are constantly fresh, accurate, and available. By eliminating pipeline downtime and bad data rows, it builds trust and enables true self-service data discovery. - What is an analytics engineer, and how do they fit into DataOps?
An analytics engineer acts as a bridge between traditional data engineers and business analysts. They use version-controlled environments and modern frameworks like dbt to write clean, modular transformation code and maintain accurate semantic layers. - Can DataOps assist with data governance and regulatory compliance?
Yes. DataOps platforms automate metadata tracking and provide end-to-end data lineage maps. This makes it easy to audit exactly how a metric was created, mask sensitive data points, and guarantee consistent security policy enforcement. - What is data pipeline cycle time?
Cycle time represents the total duration required to design, test, and deploy a brand-new data pipeline change or report from its initial concept into a live production environment. A core goal of DataOps is to safely reduce this cycle time. - How do automated rollbacks protect production dashboards?
If a newly deployed data transformation query introduces an unexpected error in production, DataOps deployment tools can instantly revert the pipeline code to the previous stable state, minimizing reporting downtime. - Where can our data team learn more about implementing DataOps best practices?
Data professionals can use comprehensive educational platforms like TheDataOps.org to study deep methodology frameworks, explore modern architectural designs, and learn how to implement automated engineering workflows.
Final Summary
Adopting DataOps is the most reliable way for modern organizations to maximize the value of their analytical investments. By replacing brittle, manual data processes with automated pipelines, continuous quality testing, and robust orchestration tools, companies protect their reporting environments from unexpected downtime and bad data. A mature DataOps framework scales effortlessly alongside exploding cloud data volumes, allowing data engineering teams to spend less time fixing broken code and more time building high-value solutions. As your team begins this transition, utilizing structured learning platforms is essential for mastering these automated engineering workflows.