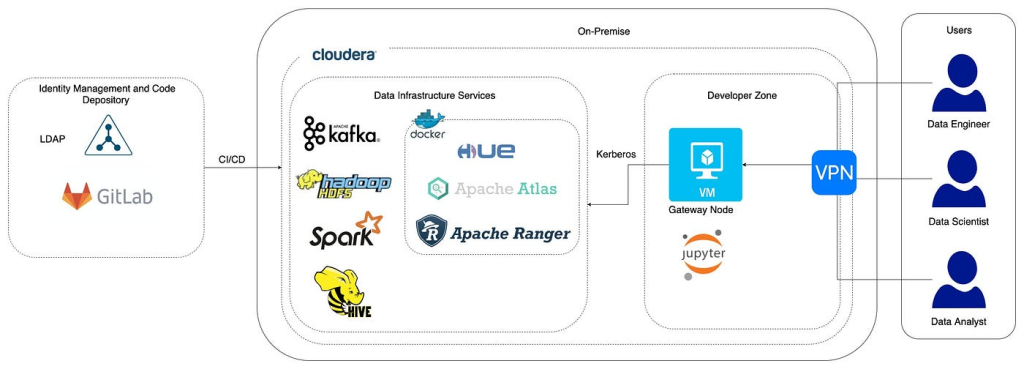
Are you struggling to manage your data operations efficiently? Do you want to learn how to use Kubernetes to streamline your DataOps process? Look no further! In this blog post, we will guide you through the steps to implement DataOps using Kubernetes.
What is DataOps?
DataOps is a methodology that combines data management and operations to provide faster, more reliable access to data for analysis and decision-making. The aim of DataOps is to improve the speed and quality of data delivery, reduce errors, and increase collaboration among teams working with data.
Why Use Kubernetes for DataOps?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Kubernetes provides a reliable, scalable, and secure infrastructure for running data-intensive workloads.
Kubernetes can help streamline the DataOps process by providing a platform to manage data pipelines, automate data workflows, and enable collaboration across teams. Kubernetes also provides tools for monitoring and troubleshooting data pipelines, ensuring that they are functioning optimally.
Steps to Implement DataOps Using Kubernetes
Step 1: Define Your Data Pipeline
The first step in implementing DataOps using Kubernetes is to define your data pipeline. A data pipeline is a set of processes that move data from one system to another, transforming it along the way. Your data pipeline should define the data sources, the transformations, and the destinations.
Step 2: Containerize Your Data Pipeline
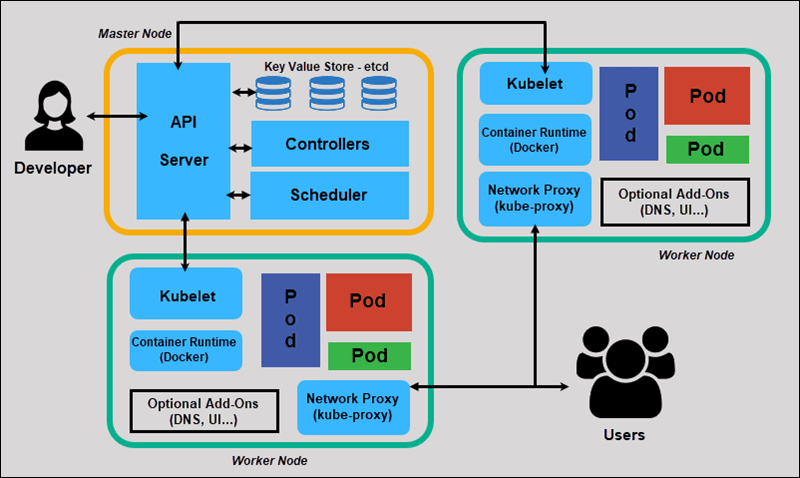
The next step is to containerize your data pipeline. Containerization is the process of packaging an application and its dependencies into a single container. Containerization allows you to deploy your data pipeline as a single unit, making it easier to manage.
Step 3: Deploy Your Data Pipeline on Kubernetes
Once you have containerized your data pipeline, the next step is to deploy it on Kubernetes. Kubernetes provides a platform for deploying and managing containerized applications. Kubernetes ensures that your data pipeline is running smoothly and provides tools for scaling and monitoring your data pipeline.
Step 4: Automate Your Data Pipeline
The next step is to automate your data pipeline. Automation allows you to streamline your DataOps process by reducing the need for manual intervention. Kubernetes provides tools for automating your data pipeline, such as scheduling jobs and triggering workflows.
Step 5: Monitor and Troubleshoot Your Data Pipeline
The final step is to monitor and troubleshoot your data pipeline. Kubernetes provides tools for monitoring and troubleshooting your data pipeline, such as logs and metrics. Monitoring and troubleshooting your data pipeline ensures that it is running optimally and that errors are quickly identified and resolved.
Conclusion
Implementing DataOps using Kubernetes can help you streamline your data operations and improve the speed and quality of your data delivery. By following the steps outlined in this blog post, you can containerize, deploy, automate, and monitor your data pipeline using Kubernetes. So, what are you waiting for? Start implementing DataOps using Kubernetes today!