Data Management Tools are software solutions designed to handle various aspects of data management throughout its lifecycle. These tools help organizations capture, store, process, analyze, protect, and govern their data effectively. They play a crucial role in ensuring data quality, security, and compliance while providing the ability to derive valuable insights from data.
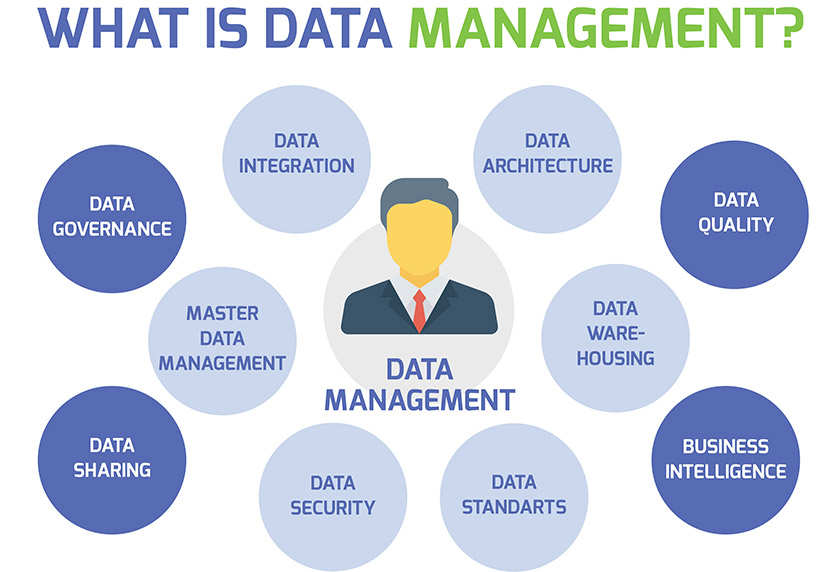
Key Features of Data Management Tools:
- Data Integration: Data management tools facilitate seamless data integration by connecting and consolidating data from multiple sources, such as databases, applications, APIs, cloud services, and more.
- Data Storage and Warehousing: These tools provide capabilities for data storage and warehousing, allowing organizations to store large volumes of structured and unstructured data in a structured manner.
- Data Quality Management: Data management tools include features for data profiling, cleansing, standardization, and enrichment to ensure data accuracy and consistency.
- Data Governance: Data governance features enable organizations to define and enforce data policies, access controls, and data ownership. This helps in maintaining data compliance and data security.
- Master Data Management (MDM): Data management tools with MDM capabilities help establish and manage a single, authoritative version of master data, ensuring consistency across the organization.
- Data Security and Privacy: These tools provide features to secure data at rest and in transit, implement encryption, and enforce data access controls to protect sensitive information.
- Data Backup and Recovery: Data management tools often include backup and recovery functionalities to safeguard data from loss due to system failures or accidental deletions.
- Data Analytics and Reporting: These tools may offer built-in or integrated analytics and reporting capabilities to derive insights from data and generate visualizations and reports.
- Data Migration: Data management tools aid in the smooth and efficient migration of data from one system or storage location to another, ensuring data integrity throughout the process.
- Data Lineage and Auditability: Data management tools maintain data lineage, allowing users to trace the origin, transformations, and usage of data. They also provide auditing features for compliance and accountability.
List of Data Management Tools
1. Apache Hadoop
Apache Hadoop is an open-source distributed computing framework designed to store, process, and analyze large datasets in a distributed and scalable manner. It was inspired by Google’s MapReduce and Google File System (GFS) papers and is one of the key technologies behind the big data revolution. Hadoop allows organizations to efficiently process massive amounts of data across clusters of commodity hardware.
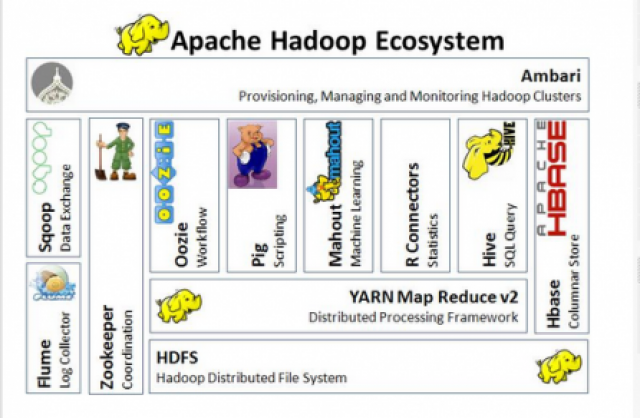
Key Features of Apache Hadoop:
Distributed File System (HDFS): Hadoop includes HDFS, a distributed file system that can store massive volumes of data across multiple nodes in a Hadoop cluster. It provides fault tolerance, data replication, and high throughput data access.
MapReduce Processing: Hadoop utilizes the MapReduce programming model to process and analyze data in parallel across the Hadoop cluster. MapReduce enables scalable and distributed data processing.
Scalability: Hadoop’s distributed nature allows it to scale horizontally by adding more nodes to the cluster, enabling organizations to handle ever-growing volumes of data.
Apache Hadoop has revolutionized the way organizations handle big data challenges. Its distributed and scalable architecture, coupled with the rich ecosystem of data processing tools, has made it a go-to solution for processing and analyzing massive datasets across various industries.
2. Apache Spark
Apache Spark is an open-source distributed computing framework designed for fast and efficient processing of large-scale data. It provides an in-memory computing engine, enabling real-time data processing and iterative algorithms. Spark is built for ease of use, scalability, and high performance, making it a popular choice for big data processing and analytics.
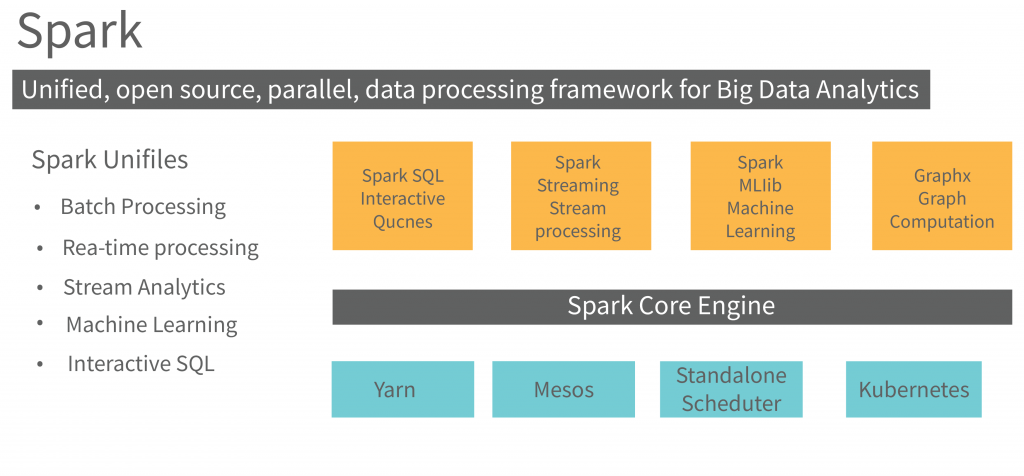
Key Features of Apache Spark:
In-Memory Processing: Spark stores data in memory, which allows for faster data access and processing compared to traditional disk-based systems. It minimizes data movement across the cluster, leading to significant performance improvements.
Distributed Data Processing: Spark can distribute data across a cluster of machines and perform parallel processing. This distributed nature ensures scalability and high throughput.
Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structures in Spark. They are fault-tolerant, immutable collections of data that can be processed in parallel. RDDs provide the basis for distributed data processing in Spark.
Apache Spark’s versatility, speed, and ability to handle diverse data processing tasks have made it a preferred choice for big data processing, analytics, and machine learning across industries and use cases.
3. Apache Kafka
Apache Kafka is an open-source distributed streaming platform developed by the Apache Software Foundation. It is designed to handle real-time data streams and allows for the scalable, fault-tolerant, and high-throughput processing of streaming data. Kafka is commonly used for building event-driven architectures and ingesting, storing, and processing large volumes of data streams.
Key Features of Apache Kafka:
Publish-Subscribe Model: Kafka follows a publish-subscribe messaging model, where data is produced by producers and consumed by consumers. Producers publish data to Kafka topics, and consumers subscribe to these topics to receive the data.
High Throughput: Kafka is known for its high throughput and low-latency data processing capabilities. It can handle millions of messages per second with low processing overhead.
Stream Processing: Kafka Streams is a feature of Kafka that allows for real-time stream processing. It enables developers to write applications that process data directly within Kafka without the need for external processing frameworks.
Apache Kafka’s combination of scalability, fault tolerance, and real-time data processing capabilities has made it a popular choice for building event-driven architectures, real-time analytics, log aggregation, and streaming data processing solutions in various industries.
4. Cloudera
Cloudera is a software company that provides an enterprise data cloud platform based on open-source technologies, including Apache Hadoop, Apache Spark, Apache Kafka, and more. Cloudera’s platform is designed to help organizations store, process, and analyze large volumes of data in a scalable and efficient manner. It offers a comprehensive suite of data management and analytics tools to address a wide range of big data challenges.
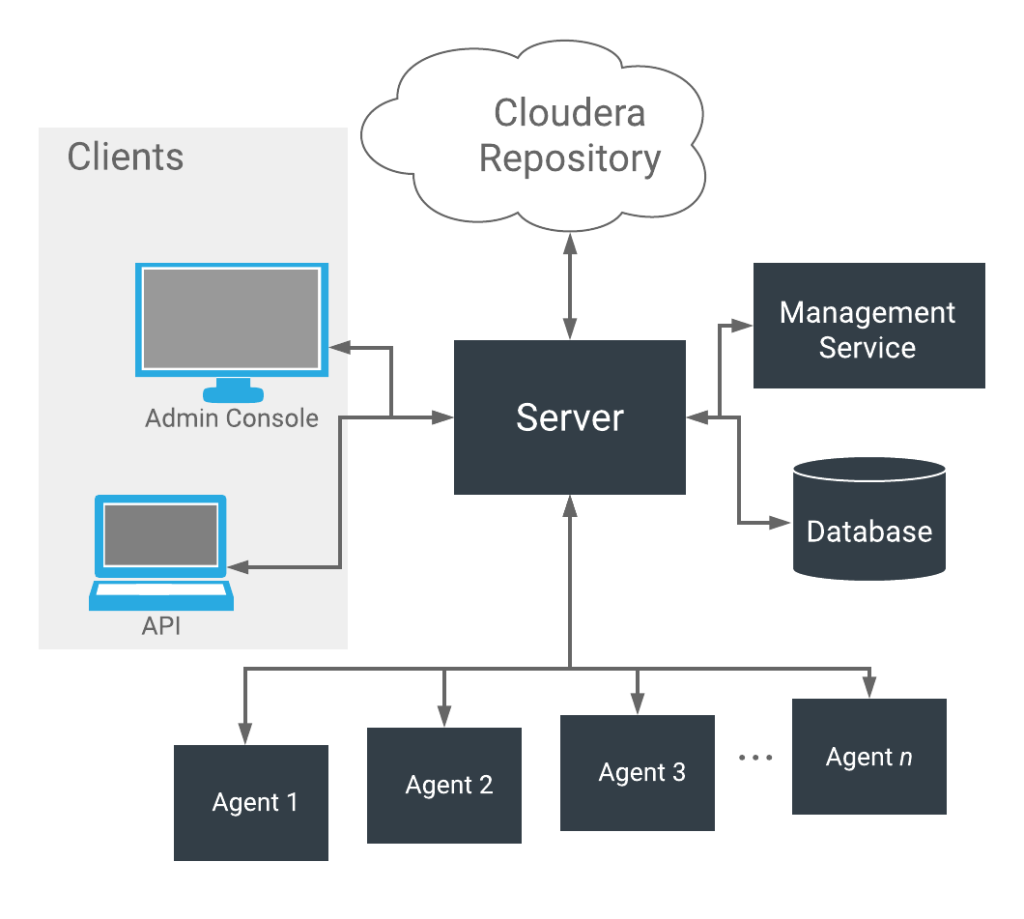
Key Features of Cloudera’s Enterprise Data Cloud Platform:
Data Storage: Cloudera offers a distributed data storage solution based on Apache Hadoop’s Hadoop Distributed File System (HDFS). It allows organizations to store and manage large volumes of structured and unstructured data across a cluster of nodes.
Data Integration: Cloudera provides data integration capabilities to ingest data from various sources, including databases, cloud services, IoT devices, and more. It supports data movement through its Apache NiFi-based DataFlow technology.
Data Security and Governance: Cloudera provides robust data security features, including data encryption, access controls, and auditing capabilities. It also supports data governance to ensure compliance and data quality.
Cloudera’s Enterprise Data Cloud Platform is widely used by organizations to harness the power of big data, enabling them to gain valuable insights, make data-driven decisions, and drive innovation across various industries.
5. Hortonworks
Hortonworks was a software company that provided an open-source data platform based on Apache Hadoop and related big data technologies. In 2019, Hortonworks merged with Cloudera, another leading company in the big data space, to create a unified platform for enterprise data management and analytics.
Before the merger, Hortonworks offered the Hortonworks Data Platform (HDP), which was designed to help organizations store, process, and analyze large-scale data. While the standalone Hortonworks brand is no longer active, many of its technologies and features have been integrated into the Cloudera Data Platform (CDP), which is the unified platform resulting from the Cloudera-Hortonworks merger.
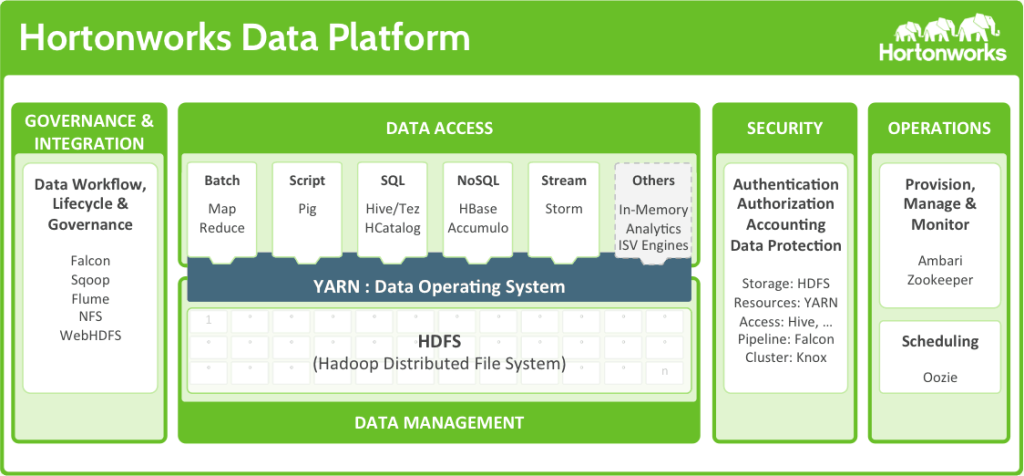
Key Features of the Hortonworks Data Platform (HDP) and Cloudera Data Platform (CDP):
Data Storage: Hortonworks Data Platform and Cloudera Data Platform both offer distributed data storage using Hadoop Distributed File System (HDFS), allowing organizations to store and manage large volumes of structured and unstructured data across a cluster of nodes.
Data Security and Governance: Both platforms provide robust data security features, including data encryption, authentication, and authorization, to ensure data privacy and compliance with regulations. They also offer governance capabilities for data lineage and auditability.
Cloud and Hybrid Deployment: Hortonworks and Cloudera platforms offer deployment options on various cloud providers like AWS, Azure, and Google Cloud Platform. They also support hybrid data environments, allowing organizations to integrate on-premises and cloud resources.
By combining the strengths of Hortonworks and Cloudera, the Cloudera Data Platform (CDP) offers a unified, comprehensive solution for enterprise data management and analytics, enabling organizations to leverage the power of big data to make data-driven decisions and gain valuable insights.
6. MapR
MapR was a software company that provided a data platform based on Apache Hadoop and other big data technologies. The platform was known for its distributed file system called MapR-FS, which offered unique features and performance enhancements compared to traditional Hadoop Distributed File System (HDFS). However, in early 2020, MapR faced financial difficulties and was acquired by Hewlett Packard Enterprise (HPE). The MapR products have since been integrated into HPE Ezmeral Data Fabric, and the standalone MapR brand is no longer active.
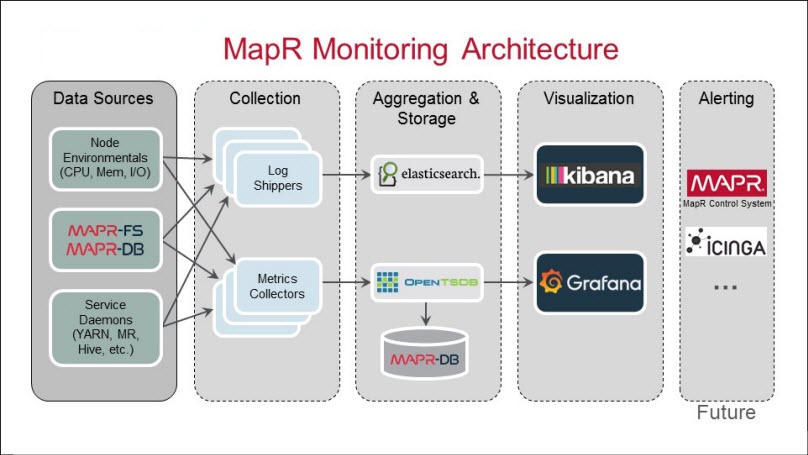
Key Features of MapR (Now Part of HPE Ezmeral Data Fabric):
MapR-FS: MapR-FS was a distributed file system that replaced HDFS in the MapR platform. It provided improved performance, data reliability, and scalability while maintaining HDFS compatibility. MapR-FS supported POSIX and NFS interfaces, making it easier to integrate with existing applications.
Global Namespace: MapR offered a global namespace, enabling users to access data from various locations through a single, unified view.
Management and Monitoring: MapR included a management and monitoring interface that allowed administrators to manage and monitor the MapR cluster and track performance metrics.
While the standalone MapR brand is no longer active, the MapR products and technologies have been integrated into HPE Ezmeral Data Fabric, which is now part of Hewlett Packard Enterprise’s portfolio. HPE Ezmeral Data Fabric continues to offer advanced data management and analytics capabilities to help organizations leverage big data effectively for their business needs.
[…] List of Data Management Tools […]