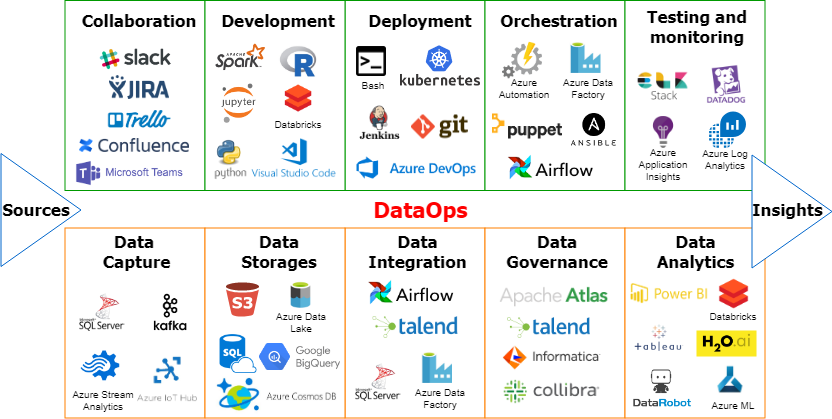
Have you ever heard of DataOps tools? If not, don’t worry, you’re not alone! DataOps is a relatively new concept that combines data engineering, data integration, and DevOps principles to create a streamlined and automated data pipeline. In this article, we’ll dive into what DataOps is and explore some of the most popular tools used in the industry.
What is DataOps?
DataOps is a methodology that aims to improve the speed and quality of data analytics by using automation and collaboration. It’s a combination of data engineering, data integration, and DevOps principles. The goal of DataOps is to create a streamlined and automated data pipeline that allows data analysts and scientists to access high-quality data quickly and easily.
Why is DataOps important?
As the amount of data that organizations collect and process continues to grow, it’s becoming increasingly important to have an efficient and reliable data pipeline. A well-designed DataOps process can help organizations:
- Improve the speed and accuracy of data analytics
- Reduce the risk of errors and inconsistencies in data
- Increase collaboration and communication between teams
- Improve the scalability and flexibility of data infrastructure
Popular DataOps Tools
There are many tools available in the market that can help organizations implement a DataOps process. Let’s take a look at some of the most popular ones.
Apache Airflow
Apache Airflow is an open-source platform that allows organizations to create, schedule, and monitor data workflows. It’s based on the idea of Directed Acyclic Graphs (DAGs), which allows users to define a series of tasks and dependencies between them. Airflow supports a wide range of integrations and plugins, making it a versatile tool for data pipeline automation.
Jenkins
Jenkins is a well-known open-source automation server that’s primarily used for continuous integration and continuous delivery (CI/CD) pipelines. However, it can also be used for DataOps workflows. Jenkins supports a wide range of plugins and integrations, making it a flexible and customizable tool for data pipeline automation.
Databricks
Databricks is a cloud-based platform that provides a unified data analytics platform for data engineering, data science, and business analytics. It’s built on top of Apache Spark and provides a collaborative workspace for teams to work on data projects. Databricks supports a wide range of integrations and connectors, making it a powerful tool for DataOps workflows.
AWS Glue
AWS Glue is a fully-managed ETL (extract, transform, load) service that makes it easy to move data between data stores. It supports a wide range of data sources and provides a variety of tools for data transformation and mapping. AWS Glue also integrates with other AWS services, making it a popular choice for organizations that use AWS as their cloud provider.
DataKitchen
DataKitchen is a DataOps platform that provides a suite of tools for data pipeline automation and management. It’s designed to be easy to use and provides a visual interface for creating and managing workflows. DataKitchen also provides a variety of tools for testing and monitoring data pipelines, making it a comprehensive tool for DataOps workflows.
Conclusion
DataOps is a methodology that combines data engineering, data integration, and DevOps principles to create a streamlined and automated data pipeline. There are many tools available in the market that can help organizations implement a DataOps process, including Apache Airflow, Jenkins, Databricks, AWS Glue, and DataKitchen. By using these tools, organizations can improve the speed and quality of data analytics while reducing the risk of errors and inconsistencies in data.