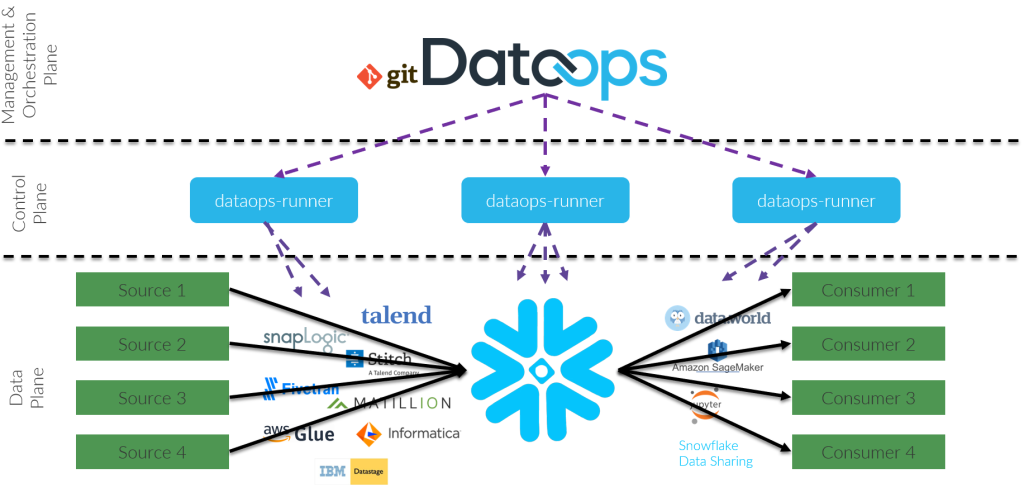
Are you tired of hearing about DevOps and wondering what DataOps is all about? Well, you’ve come to the right place! In this blog post, we’ll be diving deep into the world of DataOps and exploring its architecture.
Understanding DataOps
Before we get into the architecture, let’s take a moment to understand what DataOps is. Simply put, DataOps is the practice of bringing together data engineers, data scientists, and other stakeholders to streamline the data pipeline process.
DataOps emerged as a response to the challenges of managing and processing large amounts of data. By breaking down silos and promoting collaboration, DataOps aims to make the data pipeline process faster, more efficient, and more reliable.
The DataOps Architecture
So, what exactly does the DataOps architecture look like? Well, it’s a bit complex, but we’ll do our best to break it down for you.
Layer 1: Data Ingestion
The first layer of the DataOps architecture is data ingestion. This layer is responsible for bringing in data from various sources, such as databases, APIs, and streaming platforms.
At this layer, data is collected, transformed, and validated to ensure that it meets the required standards. The data is then stored in a data lake or a data warehouse for further processing.
Layer 2: Data Processing
Once the data is ingested, it moves on to the data processing layer. At this layer, the data is transformed and enriched to prepare it for analysis.
Data processing involves tasks such as data cleaning, data integration, and data aggregation. This layer also involves the use of tools such as Apache Spark, Apache Kafka, and Apache Flink.
Layer 3: Data Analysis
After the data is processed, it moves on to the data analysis layer. This layer is responsible for analyzing the data to extract insights and make informed decisions.
Data analysis involves tasks such as data visualization, statistical modeling, and machine learning. This layer also involves the use of tools such as Jupyter Notebooks and Tableau.
Layer 4: Data Delivery
The final layer of the DataOps architecture is data delivery. This layer is responsible for delivering the insights and decisions made at the data analysis layer to the end-users.
Data delivery involves tasks such as report generation, dashboard creation, and API development. This layer also involves the use of tools such as Power BI and Looker.
The Benefits of DataOps Architecture
Now that we’ve explored the architecture of DataOps, let’s take a moment to discuss the benefits of implementing this architecture.
First and foremost, DataOps architecture promotes collaboration and breaks down silos. By bringing together data engineers, data scientists, and other stakeholders, DataOps ensures that everyone is working towards a common goal.
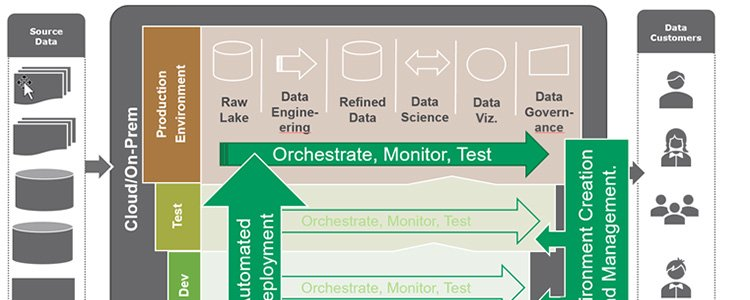
Secondly, DataOps architecture improves the efficiency of the data pipeline process. By streamlining the process, DataOps reduces the time it takes to extract insights from data.
Finally, DataOps architecture improves the reliability of the data pipeline process. By validating data at the ingestion layer and ensuring that it meets the required standards, DataOps reduces the risk of errors and inconsistencies.
Conclusion
In conclusion, DataOps architecture is a complex but effective approach to managing and processing large amounts of data. By breaking down silos, promoting collaboration, and streamlining the data pipeline process, DataOps ensures that insights can be extracted quickly and reliably.
So, if you’re looking to improve the efficiency and reliability of your data pipeline process, consider implementing the DataOps architecture. Your data engineers and data scientists will thank you for it!