Introduction
In the current landscape of artificial intelligence, building a model is only the beginning. The real challenge for enterprise teams lies in the transition from a local experiment to a production-ready system. As complexity grows, data scientists and engineers often find themselves struggling with fragmented workflows, unreliable data, and deployment bottlenecks. This is where the integration of DataOps and MLOps becomes critical. While DataOps focuses on the speed and quality of data delivery, MLOps ensures that machine learning models are managed effectively through their lifecycle. Combining these two disciplines creates a seamless bridge from raw data to actionable insights. At TheDataOps, we emphasize that automation is the backbone of this transition. Without structured pipelines, organizations face technical debt and stalled AI initiatives. Understanding how to align these workflows is essential for any professional working in the modern analytics space.
What Are DataOps and MLOps?
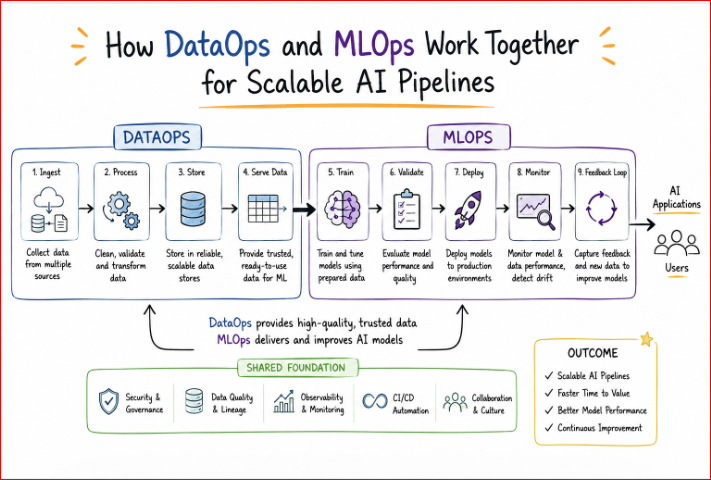
DataOps is a collaborative practice focused on improving the quality and reducing the cycle time of data analytics. It applies principles from agile development and DevOps to data engineering, ensuring that data flows reliably from source to destination. MLOps, or machine learning operations, extends these principles to the machine learning lifecycle. It focuses on the deployment, monitoring, and maintenance of ML models in production. The relationship between them is symbiotic. You cannot have a robust ML model without high-quality data. By combining them, organizations move beyond manual, error-prone processes toward automated, reproducible systems. This evolution transforms how companies handle everything from streaming telemetry to batch processing for predictive modeling.
Why DataOps Integration Matters in MLOps
Integrating DataOps into MLOps is not just about convenience; it is about survival in a competitive market. When data pipelines are treated as second-class citizens, model drift becomes inevitable.
- Faster Deployment: Integrated pipelines allow models to move from development to production without manual data wrangling.
- Data Quality Assurance: Automated testing ensures that only high-quality, validated data reaches the model training phase.
- Pipeline Automation: End-to-end automation reduces human error, making the entire workflow more predictable.
- Improved Collaboration: Data engineers and ML engineers share a common language and set of tools, breaking down departmental silos.
For instance, a predictive maintenance system in manufacturing requires constant streams of sensor data. If the DataOps workflow is disjointed, the ML model will fail to recognize new failure patterns, leading to system downtime.
Core Principles of DataOps and MLOps Integration
Data Pipeline Automation
Automation is the heart of the operation. By using workflow orchestration, teams can ensure that data extraction, transformation, and loading (ETL) happen predictably without intervention.
Continuous Integration for ML Workflows
Just as code needs testing, ML pipelines need continuous integration (CI) to validate that code changes do not break model training or data ingestion processes.
Data Quality Monitoring
Monitoring is not just for models. Teams must monitor the health, schema, and statistical properties of incoming data to prevent “garbage in, garbage out” scenarios.
Model Lifecycle Management
This involves versioning models, tracking training runs, and managing the transition from development to staging and finally to production.
Workflow Orchestration
Orchestration tools act as the conductor, ensuring that tasks occur in the correct sequence, handling retries, and managing dependencies across the entire lifecycle.
Observability and Monitoring
Full-stack observability allows engineers to see exactly where a process failed—whether in the data layer or the model layer—minimizing mean time to recovery (MTTR).
Governance and Compliance
Integrated systems provide audit trails for data lineage and model versioning, which are essential for industries with strict regulatory requirements.
DataOps + MLOps Workflow Explained
The modern AI workflow is a continuous loop rather than a straight line:
- Data Collection: Gathering raw data from diverse sources.
- Data Preprocessing: Cleaning and structuring data.
- Feature Engineering: Extracting relevant variables for model training.
- Model Training: Running experiments and tuning hyperparameters.
- Model Validation: Testing model performance against holdout data.
- Deployment Pipelines: Automating the push to production.
- Monitoring and Retraining: Detecting performance drops and triggering new training cycles automatically.
- Feedback Loops: Incorporating real-world performance data back into the start of the cycle.
Popular Tools Used in DataOps and MLOps
| Tool | Purpose | Difficulty Level | Common Usage |
| Apache Airflow | Workflow Orchestration | Moderate | Scheduling complex pipelines |
| Kubeflow | ML Workflow Platform | Advanced | Running ML on Kubernetes |
| MLflow | Model Lifecycle | Moderate | Experiment tracking and model registry |
| Databricks | Unified Data/ML | Moderate | Collaborative data engineering |
| Jenkins | CI/CD | Moderate | Automating deployment tasks |
| Kubernetes | Container Management | Advanced | Scaling AI services |
| TFX | ML Pipeline Platform | Advanced | Large-scale production pipelines |
| Apache Kafka | Data Streaming | Advanced | Handling real-time data ingestion |
Architecture of Modern AI Operations
Modern AI architecture is cloud-native and modular. It relies on a decoupled design where data storage, processing engines, and model serving layers interact through standardized APIs. By using containerization, teams ensure that the environment used for training is identical to the one used for serving, eliminating the “it works on my machine” problem.
Roles and Responsibilities in DataOps & MLOps
- Data Engineer: Focuses on the infrastructure of data pipelines and storage.
- ML Engineer: Concentrates on model architecture, training, and optimization.
- MLOps Engineer: Bridges the gap by building the infrastructure that hosts and serves models.
- DataOps Engineer: Optimizes data delivery, quality testing, and pipeline reliability.
- AI Infrastructure Engineer: Manages the underlying compute and cloud resources.
- Cloud Data Architect: Designs the high-level system topology for scalable AI.
Beginner Roadmap for Learning DataOps & MLOps
- Linux/CLI: Master the command line for system interactions.
- Python: Develop proficiency in data manipulation libraries.
- SQL: Become an expert in querying relational databases.
- Data Engineering: Understand ETL, data warehousing, and storage.
- ML Fundamentals: Learn how models are trained and evaluated.
- Cloud Basics: Familiarize yourself with AWS, Azure, or GCP.
- CI/CD: Learn to automate testing and deployment.
- Kubernetes/Docker: Understand containerization for portability.
- Orchestration: Practice with Airflow or similar tools.
- Observability: Learn to monitor systems effectively.
Certifications & Learning Resources
| Certification | Level | Best For | Skills Covered |
| Google Professional ML Engineer | Advanced | ML Experts | End-to-end ML production |
| AWS Certified Data Engineer | Intermediate | Data Professionals | Data pipelines and storage |
| CKAD (Kubernetes) | Advanced | Cloud Engineers | Container orchestration |
| TheDataOps Courses | All | Beginners to Pro | Holistic DataOps workflows |
Real-World Use Cases of DataOps & MLOps
In Healthcare, automated pipelines ensure patient data remains consistent while models predict health outcomes in real-time. In E-commerce, recommendation engines rely on DataOps to refresh product catalogs and MLOps to serve personalized suggestions to millions of users simultaneously. Financial platforms utilize these integrated workflows for fraud detection, where the speed of data processing directly impacts the ability to block unauthorized transactions.
Benefits of Integrating DataOps With MLOps
The primary benefit is stability. By integrating these fields, you create a system that is not only faster but also more resilient. When data quality is automated, developers spend less time fixing broken pipelines and more time building innovative features. This scalability is what allows startups to compete with industry giants.
Common Challenges in DataOps & MLOps Integration
- Poor Data Quality: Often ignored until the model fails. Solution: Implement data contracts and automated quality gates.
- Workflow Complexity: Too many tools create noise. Solution: Standardize on a core stack and limit fragmentation.
- Governance: Compliance is hard in decentralized systems. Solution: Maintain a central data lineage record.
- Skill Shortage: These roles require broad knowledge. Solution: Invest in cross-training existing teams.
Common Beginner Mistakes
- Trying to learn every tool at once rather than understanding the underlying architecture.
- Focusing solely on the model accuracy while ignoring the data pipeline performance.
- Neglecting documentation for pipelines, which leads to knowledge silos.
- Skipping hands-on projects; theory alone is insufficient for this field.
Best Practices for DataOps and MLOps
Always automate tasks that you perform more than twice. Use version control for everything—not just code, but also data and model parameters. Maintain a culture of observability where you monitor the data’s health as closely as the model’s performance. Finally, ensure that your infrastructure is documented so that new team members can onboard quickly.
Future of DataOps & MLOps
The future points toward “Autonomous AI Pipelines,” where systems use self-healing mechanisms to fix data quality issues or retrain models based on real-time performance signals. As AI matures, the focus will shift from building models to managing the “intelligence supply chain” that supports them.
FAQs
- What is the fundamental difference between DataOps and MLOps?
DataOps focuses on the reliability and speed of the data supply chain, while MLOps extends those principles to manage the end-to-end lifecycle of machine learning models. Together, they ensure that high-quality data reaches the model for accurate production results. - Can a beginner learn DataOps and MLOps simultaneously?
It is possible, but I suggest mastering basic data engineering and SQL first to understand the data flow. Once you are comfortable, layer in MLOps concepts like model deployment and containerization to avoid feeling overwhelmed by the toolsets. - Does an MLOps role require deep programming knowledge?
Yes, you need proficiency in Python and shell scripting to automate pipelines and interact with APIs. You do not need to be a full-stack developer, but you must be able to debug code and manage infrastructure logic. - Which tools should I prioritize for building ML workflows?
Start with one core tool per category, such as Apache Airflow for orchestration and Docker for containerization. Mastering these foundational tools makes learning other specialized technologies significantly easier as your career progresses. - Why is data quality the most critical factor in AI systems?
AI models are essentially reflections of the data they consume, meaning poor data input leads to unreliable or biased outputs. DataOps mitigates this by implementing automated quality gates that validate data before it ever reaches the training pipeline. - Is Kubernetes absolutely necessary for modern MLOps?
While not mandatory for small projects, Kubernetes is the industry standard for scaling AI services in production. It provides the robust orchestration needed to manage large-scale containerized applications effectively across enterprise environments. - What are the primary career paths within DataOps and MLOps?
Common roles include Data Engineer, MLOps Engineer, and AI Infrastructure Strategist. Each role focuses on different parts of the pipeline, from data ingestion and storage to model serving and system scalability. - How long does it realistically take to become proficient in these workflows?
With consistent hands-on practice, you can build functional pipelines within 3 to 6 months. Achieving true proficiency in designing and maintaining complex, production-grade systems typically requires about a year of dedicated project work. - How does DataOps help with regulatory compliance?
DataOps creates audit trails by tracking data lineage and every transformation step taken in the pipeline. This transparency is essential for industries like finance and healthcare that must adhere to strict data privacy and governance standards. - What is the most effective way to practice these skills?
The best approach is to build an end-to-end project, from raw data collection to model deployment. Documenting your work and learning to debug your own automated pipelines provides more practical experience than any theoretical course.
Conclusion
The integration of DataOps and MLOps is the bridge between a simple prototype and a scalable, production-ready AI product. To succeed in this field, prioritize learning the underlying architectural principles—automation, observability, and data quality—rather than just memorizing a list of tools. By building end-to-end pipelines and focusing on reliability, you will position yourself as a valuable asset capable of transforming raw data into high-performing, real-world AI systems.