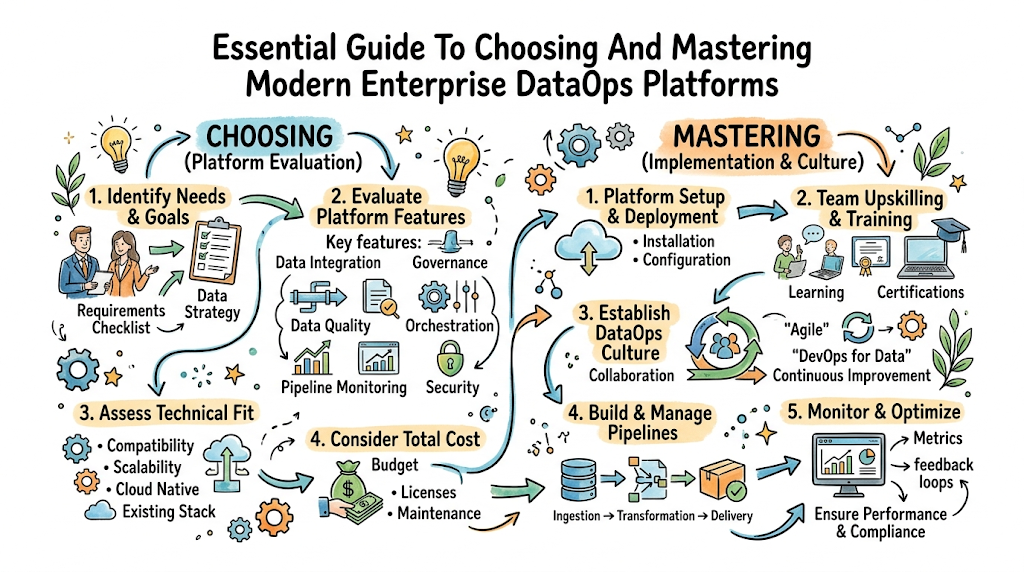
Introduction
DataOps platforms represent the modern standard for orchestrating the entire data lifecycle, from initial ingestion to final analytics delivery. By applying agile engineering and automated DevOps principles to data management, these systems eliminate traditional silos, significantly reducing the “cycle time” between an idea and a production-ready insight. Through the expert frameworks and professional certifications provided by TheDataOps organizations can master the industrialization of data delivery, transforming raw, disconnected information into a high-quality, reliable asset that powers faster and more accurate business decision-making.
The Origin of Modern Data Operations
Early Challenges in Data Management
Traditionally, data lived in isolated silos. Analysts relied on custom scripts to move information from transactional systems into spreadsheets or basic reporting tools. If a field changed, the entire report would break, leading to hours of manual debugging.
Transition from Manual Analytics to Automated Pipelines
As storage became cheaper and data volumes exploded, manual management reached a breaking point. Organizations began shifting toward automated workflows. Engineers started writing code to manage data movement, treating data pipelines like software products rather than one-off tasks.
Enterprise Adoption of DataOps Platforms
Enterprises adopted DataOps to handle the complexity of multi-cloud environments. The goal was to provide a reliable data supply chain that could scale with the business. Today, DataOps platforms serve as the foundation for both business intelligence and advanced machine learning initiatives.
Defining Modern DataOps Platforms
The Core Architecture of DataOps Systems
DataOps platforms consist of four primary pillars: ingestion to bring data in, orchestration to schedule the work, transformation to clean it, and observability to monitor it. These components work in unison to provide a consistent data flow.
Daily Responsibilities of DataOps Engineers
A DataOps engineer spends the day building and testing pipelines. They configure alerts for potential failures, manage data access controls, and optimize infrastructure costs. Their primary focus is maintaining system health and ensuring that data reaches analysts on time.
Pipeline Monitoring vs. Data Observability
Monitoring tells you if a system is up or down. Data Observability tells you if the data itself is accurate, complete, and trustworthy. It looks deep into the data quality rather than just checking if the server is running.
The Continuous Data Delivery Mindset
This mindset treats data as a product. It emphasizes short development cycles, frequent testing, and constant feedback loops. By automating the path from source to dashboard, teams eliminate bottlenecks and reduce the risk of downtime.
The 7 Core Principles of How TheDataOps.org Explains Top DataOps Platforms
1. Continuous Data Integration
Data integration involves moving data from various sources into a central warehouse or lake. Modern pipelines do this continuously, ensuring that analysts always have access to the latest information without waiting for batch processes to run.
2. Automated Testing and Validation
Every data change must be validated. If a source system changes a data type, automated tests should catch this immediately. This ensures that downstream reports never contain bad data.
3. Pipeline Orchestration and Scheduling
Orchestration is the traffic control of your data environment. It manages dependencies, ensuring that data is transformed only after it is successfully loaded, saving time and compute resources.
4. Data Observability and Monitoring
Tracking freshness and lineage is vital. If a dashboard is empty, you need to know exactly which transformation step failed and why. This allows engineers to fix issues before the users ever see them.
5. Automation Over Manual Data Handling
Manual steps are error-prone. By automating environment provisioning and code deployment, teams reduce human error. Automation allows a small team to manage thousands of complex data tables.
6. Scalable Cloud-Native Data Infrastructure
Modern data environments must handle spikes in traffic. Cloud-native platforms provide the flexibility to add compute power during busy periods and scale down when the demand decreases.
7. Collaboration Between Data Teams
DataOps breaks down walls between data engineers, data scientists, and business analysts. Everyone works from the same source of truth, using shared tools and common operational language.
Key DataOps Concepts Every Beginner Must Know
DataOps vs. DevOps vs. MLOps — Explained Simply
- DevOps focuses on software development and deployment cycles.
- DataOps focuses on the reliability and speed of data pipelines.
- MLOps focuses on the lifecycle of machine learning models and training data.
ETL vs. ELT Pipelines
ETL (Extract, Transform, Load) cleans data before it enters the warehouse. ELT (Extract, Load, Transform) moves raw data first and transforms it inside the warehouse, which is often faster for cloud-scale operations.
Data Lineage — The Backbone of Data Reliability
Data lineage is the map of your data. It shows you the origin of a dataset and every transformation it has gone through. Without it, debugging a wrong number is nearly impossible.
Data Quality and Observability
In simple terms, quality means the data is correct. Observability means you have the tools to know when it is incorrect. Together, they form the safety net for your analytics.
Incident Management for Data Pipelines
When a pipeline fails, you need a process. This includes automated alerting, ticket creation, and a quick pathway to revert bad code, just like you would with software applications.
The Four Pillars of Modern Data Operations
- Orchestration: Managing the flow.
- Observability: Watching the health.
- Automation: Reducing manual toil.
- Governance: Managing access and standards.
Traditional Data Management vs. DataOps — What’s the Real Difference?
The Philosophy Difference
Traditional management is reactive, often waiting for a user to report a missing report. DataOps is proactive, detecting and fixing issues before they reach the consumer.
Roles & Responsibilities Compared
- Traditional: Manual testing, one-off script maintenance, firefighting, siloed workflows.
- DataOps: Infrastructure-as-code, automated CI/CD, pipeline monitoring, cross-functional collaboration.
Can Traditional Data Warehousing and DataOps Work Together?
Yes, many companies run a hybrid model. You can bring DataOps practices into a legacy warehouse to improve its reliability while you plan a transition to a modern cloud stack.
Which Operational Model Should Organizations Adopt?
If your team is small and the data is static, manual management might work. However, if your data volume grows and decision-makers rely on real-time insights, DataOps is the necessary evolution.
Real-World Use Cases of Modern DataOps Platforms
Real-Time Analytics for Enterprises
Enterprises use these systems to track customer behavior as it happens. This allows for instant personalization in applications or real-time inventory adjustments.
Data Quality Monitoring at Scale
Large retailers use automated quality checks to ensure that inventory levels across thousands of stores remain accurate throughout the business day.
Multi-Cloud Data Operations
Teams often store data in different cloud providers. DataOps platforms provide a unified interface to orchestrate and monitor these distributed environments from one location.
DataOps in Financial and Healthcare Systems
In highly regulated industries, you must prove where data came from and who accessed it. DataOps provides the lineage and audit trails required for compliance.
Lightweight DataOps for Startups
Startups can use open-source orchestrators and cloud tools to build efficient, automated pipelines without a massive initial investment in proprietary software.
Common Mistakes in DataOps Implementation
Mistake 1 — Treating DataOps as Only ETL Automation
DataOps is not just a tool; it is a way of working. Focus on culture, documentation, and communication as much as you focus on the software you install.
Mistake 2 — Ignoring Data Quality Validation
If you focus only on the speed of the pipeline, you might end up moving bad data into your warehouse faster. Never deploy a pipeline without automated quality tests.
Mistake 3 — Poor Pipeline Documentation
When a pipeline is undocumented, only the person who built it can fix it. This creates a single point of failure that can hurt your business during staff turnover.
Mistake 4 — Overlooking Monitoring and Observability
The biggest risk is being blind to your data health. Always invest in monitoring tools that provide a complete view of pipeline performance and data quality.
Mistake 5 — Scaling Pipelines Without Governance
Without clear roles and access controls, a massive data environment becomes chaotic. Establish clear governance rules to keep your infrastructure secure and organized.
Mistake 6 — Delaying Automation Across Data Teams
Waiting to automate is a recipe for technical debt. Every manual step you leave in place becomes harder to fix as your data volume grows over time.
Essential DataOps Tools & Technologies
Pipeline Orchestration Platforms
Tools like Apache Airflow and Prefect provide the engine to schedule and coordinate your complex data workflows.
Data Transformation Tools
dbt has become the industry standard for transforming data directly within a warehouse using SQL, making it accessible to analysts and engineers alike.
Data Observability Platforms
Tools that automatically monitor your data for anomalies, schema changes, and freshness issues before they cause business problems.
Streaming & Real-Time Data Technologies
Technologies like Apache Kafka are essential for moving data in real-time, feeding live analytics systems.
Cloud Data Platforms
Snowflake and Databricks offer the compute power and storage capacity required to support modern, high-speed data operations.
Becoming a DataOps Professional — Career Roadmap
Essential Skills Every DataOps Engineer Needs
- Proficiency in SQL and Python.
- Knowledge of cloud platforms like AWS, Azure, or GCP.
- Experience with orchestration tools.
- Understanding of data observability and testing.
- Ability to work in a collaborative, team-based environment.
Step-by-Step Professional Learning Path
- Learn the basics of data modeling and SQL.
- Master an orchestration tool to schedule simple tasks.
- Dive into data transformation workflows and testing.
- Study cloud infrastructure and containerization.
- Focus on observability and enterprise-grade data management.
Certifications Worth Pursuing
Cloud certifications are highly valued. Focus on data engineering or specialty tracks offered by your chosen cloud provider, as these provide a solid foundation for any DataOps career.
Educational Resources with [TheDataOps]
TheDataOps is an excellent resource for those looking to expand their knowledge. Explore their guides to understand the nuances of various platforms and to sharpen your engineering skills.
The Future of DataOps Platforms
AI-Driven Data Operations
We are moving toward systems where AI helps write the code for your pipelines and automatically suggests fixes for failed jobs.
Self-Service Analytics Infrastructure
Companies are building internal platforms where analysts can provision their own data tools, protected by automated governance and operational guardrails.
DataOps in Cloud-Native Ecosystems
As infrastructure becomes more ephemeral, DataOps will become even more focused on managing dynamic environments that spin up and down based on demand.
Emerging Skills That Will Define Future Data Teams
The future belongs to those who understand both the data and the infrastructure. Being able to explain the financial impact of your pipeline architecture will be a key differentiator.
FAQ Section
- What is the most important skill for a data operations professional?
The ability to bridge the gap between technical infrastructure and business needs is crucial. While you must understand code and orchestration, explaining how your work enables better business decisions is what truly makes you a senior-level engineer. - How does DataOps differ from standard data engineering?
Data engineering is about building the pipelines. DataOps is about the operations surrounding those pipelines—testing, monitoring, governance, and the culture of continuous delivery that keeps those pipelines healthy over time. - Is a degree required to start a career in this field?
Not necessarily. The industry values practical experience and the ability to demonstrate your work. A strong portfolio showing how you have built and maintained reliable data pipelines is often worth more than formal credentials. - What is the expected salary growth for these roles?
Roles that combine data expertise with operational skills are in high demand across all industries. Because these engineers directly impact how quickly a company can make decisions, they are generally among the best-compensated professionals in the data space. - How can a beginner get practical experience without a massive budget?
Use open-source tools and free tiers provided by major cloud platforms. Many organizations allow you to build personal projects using public datasets, which provides the perfect environment to learn orchestration and data quality testing. - What does the future look like for data reliability?
The industry is moving toward “self-healing” pipelines. As observability tools become more sophisticated, we expect to see systems that can automatically detect, isolate, and fix common data failures without any human intervention.
Conclusion
Modern data operations are the backbone of any successful enterprise. By adopting DataOps principles, you ensure that your data is not just a collection of numbers, but a reliable asset that drives business growth. Through careful orchestration, deep observability, and a commitment to automation, you can eliminate the manual toil that slows down your team.
Focus on building robust, observable, and scalable pipelines to transform how your organization handles information. Start your path toward operational excellence today by exploring the professional resources and community guidance available at TheDataOps.