Introduction
Modern enterprises run on data, yet managing the underlying infrastructure remains a massive operational challenge. Historically, data workflows were handled manually. Data engineers wrote custom scripts, manually triggered extract, transform, and load (ETL) packages, and constantly reacted to broken tables, missing values, or silent data failures. As data volumes grew exponentially, these brittle, manual processes created severe bottlenecks, stalling business intelligence and delaying critical decisions.
To master these workflows, professionals utilize educational resources like TheDataOps, an enterprise-grade platform located at thedataops.org that provides comprehensive training on continuous data integration and workflow orchestration. For instance, consider a major financial institution pulling transactional data from legacy mainframes into an analytical cloud warehouse. Without automated orchestration, a single schema change or network blip could halt morning reporting, costing millions in unhedged market risks. DataOps automation prevents these failures by automatically isolating bad records, alerting on-call squads, and scaling up compute resources to keep pipelines running smoothly.
What Are DataOps Automation Tools?
DataOps automation tools are software platforms designed to manage, monitor, and automate the end-to-end lifecycle of data engineering pipelines. Rather than treating a data pipeline as a series of disconnected scripts, these tools treat data workflows as a unified production line. They handle automated data ingestion, transformation testing, environment provisioning, and error recovery.
The evolution of DataOps stems directly from the limitations of traditional data workflows. In conventional architectures, data management was static, slow, and deeply siloed. Software teams updated applications weekly, but data teams required months to modify data warehouse models. Pipeline automation became essential when corporate survival began to rely on real-time dashboards and machine learning models.
| Operational Aspect | Traditional Data Workflows | DataOps Workflows |
| Deployment Frequency | Monthly or quarterly manual releases | Continuous automated deployments via CI/CD |
| Error Detection | Reactive (discovered by business users) | Proactive (caught by automated testing frameworks) |
| Infrastructure Management | Fixed, manually configured hardware | Programmable, cloud-native infrastructure as code |
| Team Collaboration | Siloed engineers, analysts, and QA teams | Unified, agile cross-functional teams |
Why DataOps Automation Matters in Modern Enterprises
In production environments, manual intervention is the primary cause of pipeline instability and data corruption. Automated data pipelines remove human error from repetitive tasks, ensuring that data moves smoothly from raw source systems to analytical environments without breaking downstream applications.
Faster analytics delivery is a direct business benefit of this automated approach. When a data pipeline is fully automated, analytics engineers and data scientists can query freshly updated data within minutes of ingestion instead of waiting for overnight batch processing. This continuous data integration supports real-time analytics, enabling companies to track user behavior, adjust supply chains, or catch fraudulent activity as it happens.
Consider a large e-commerce platform processing millions of checkouts per hour. During high-traffic events, manual infrastructure provisioning fails instantly. By deploying automated orchestration tools, the platform can dynamically spin up containerized data ingestion tasks to handle sudden traffic spikes, run inline validation to filter out corrupted payloads, and deliver clean telemetry to real-time marketing dashboards. This level of automation efficiency reduces manual operations overhead, improves overall data quality, and drastically accelerates business intelligence engines.
Core Concepts of DataOps Automation
ETL & ELT Automation
Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) automation processes shift raw data into structured data warehouses or data lakes automatically. Instead of engineers manually starting batch loading scripts, automated data engineering systems listen for file creation events, database log changes, or API calls to extract data instantly, load it into scalable repositories, and apply transformations using optimized compute layers.
Workflow Orchestration
Workflow orchestration is the brain of the DataOps pipeline. It manages complex dependency graphs, ensuring that transformation tasks do not execute until the required ingestion jobs complete successfully. If an upstream task fails, the orchestration engine stops downstream execution, logs the precise point of failure, and runs pre-configured retry logic.
Continuous Data Delivery
Continuous data delivery ensures that analytical databases and production machine learning models always display the freshest state of business operations. By utilizing streaming architectures or micro-batch schedules, automated systems provide a steady, uninterrupted flow of validated data to downstream business users.
Data Observability
Data observability goes beyond standard infrastructure uptime monitoring. It checks the health of the data running through the system, tracking metric anomalies, volume drops, and schema mutations. For instance, if a source system unexpectedly starts sending strings instead of integers, observability tools flag the deviation before the corrupted data breaks downstream reporting.
Pipeline Monitoring
Pipeline monitoring focuses on system performance metrics like CPU consumption, memory allocation, network latency, and execution duration. This operational visibility helps teams optimize cloud spend, identify slow-running transformation queries, and prevent resource exhaustion before it causes pipeline delays.
Data Quality Management
Automated data quality management runs validation checks directly inside the pipeline. Before raw data reaches production tables, automated testing rules verify that critical fields are not null, primary keys remain unique, and financial totals sit within expected historical parameters.
Metadata Management
Metadata management captures structural data about your data assets. It automatically tracks data lineage—showing exactly where a specific dashboard metric originated, which pipelines transformed it, and which source tables provided the raw inputs. This clear visibility simplifies regulatory compliance and speeds up root-cause analysis during data incidents.
Real-Time Analytics
Real-time analytics relies on continuous processing engines that ingest, validate, and analyze data events within milliseconds of creation. This capability requires tight integration between automated stream processing layers and real-time storage engines to support live monitoring use cases.
CI/CD for Data Pipelines
Continuous Integration and Continuous Delivery (CI/CD) for data pipelines allows engineers to commit code changes, like an updated SQL transformation, to version control systems and have them tested automatically in an isolated staging environment. Once validated, the code safely deploys to production without disrupting active data streams.
Infrastructure Automation
Infrastructure automation utilizes code to provision and manage servers, data warehouses, and networking layers. Instead of configuring databases manually through a web console, teams use declarative configuration files to set up complete, identical data environments automatically.
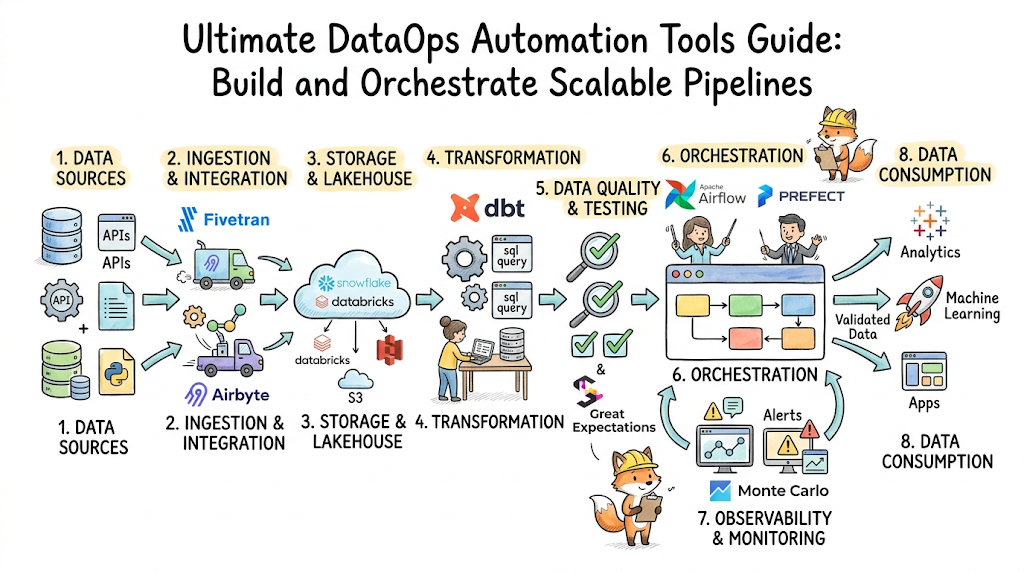
DataOps Architecture & Workflow
An enterprise DataOps architecture is constructed from modular layers that work together to turn raw data into actionable insights safely and reliably.
1. Data Ingestion Systems
The architecture begins at the ingestion layer, where automated tools connect to transactional databases, SaaS applications, and IoT streaming endpoints. These tools read raw events via change data capture (CDC) or event buses, streaming them directly into object storage or cloud staging zones without impacting the performance of production applications.
2. Pipeline Orchestration
Once data hits the staging area, the orchestration engine takes control. This layer manages the execution path, scheduling tasks, checking prerequisites, passing operational variables, and handling errors across cloud services.
3. Data Transformation Layer
The transformation layer cleanses, reshapes, and structures raw data into optimized analytical models. Typically following an ELT approach, this layer utilizes the highly scalable compute power of modern cloud data warehouses to execute programmatic transformations while enforcing strict formatting rules.
4. Analytics Processing
Structured data is then processed for downstream business applications. This layer aggregates granular log data into high-performance reporting tables, optimizes query paths, and feeds updated features directly into machine learning feature stores.
5. Monitoring Systems
Operating horizontally across the entire pipeline, the monitoring layer tracks both system health and data integrity. It measures resource utilization and queries data profiles at every stage, providing immediate visibility through centralized engineering dashboards.
6. Data Governance Workflows
The data governance layer ensures that data handling complies with security policies and regulatory frameworks. It manages role-based access control, flags personally identifiable information (PII), logs access audits, and preserves historical data lineage automatically.
7. Cloud-Native Data Infrastructure
The foundation of the entire architecture is built on flexible cloud-native components. Storage and compute are separated, allowing the system to scale up automatically during heavy workloads and scale down when idle to control operational costs.
DataOps Pipeline Lifecycle
The lifecycle of a DataOps pipeline moves data through structured stages, converting raw inputs into reliable business assets.
| Stage | Purpose | Technologies Used | Real-World Outcome |
| Data Collection | Capture raw data from applications, logs, and external APIs | Kafka, AWS Kinesis, Debezium | Unprocessed raw event logs saved into secure staging areas |
| Data Ingestion | Move captured data efficiently into centralized cloud storage | Fivetran, Airbyte, custom API connectors | Centralized landing zones filled with raw corporate datasets |
| Data Transformation | Clean, join, and structure raw data into analytical tables | dbt, Apache Spark, Snowflake | Normalized, high-performance data models ready for business analysis |
| Validation & Testing | Verify data quality and schema compliance against rules | Great Expectations, Soda, dbt test | Faulty data isolated automatically before breaking downstream systems |
| Orchestration | Manage task dependencies, schedules, and error handling | Apache Airflow, Prefect, Dagster | Smooth, automated pipeline execution with clear error reporting |
| Analytics Processing | Aggregation of structured metrics for consumption | BigQuery, Databricks, Redshift | Sub-second query performance for active business intelligence users |
| Monitoring | Track performance, execution times, and data health | Datadog, Prometheus, Monte Carlo | Instant alerts sent to engineering squads before users notice issues |
| Continuous Optimization | Refine query structures, index configurations, and compute sizes | Infrastructure as Code, custom auto-scaling | Reduced cloud platform costs and faster pipeline execution times |
Best DataOps Automation Tools
Workflow Orchestration Tools
Orchestration systems coordinate task dependencies, schedule execution paths, and handle error management across enterprise data environments. Modern options include:
- Apache Airflow: The open-source industry standard that defines workflows as Directed Acyclic Graphs (DAGs) using Python code.
- Prefect: A modern orchestrator designed for dynamic, loop-based workflows with native asynchronous support.
- Dagster: An orchestration engine focused on data assets rather than just tasks, featuring built-in data profiling and native testing capabilities.
ETL/ELT Platforms
These platforms focus on extracting data from varied sources and loading it into analytical destinations. Key tools include:
- dbt (Data Build Tool): A widely adopted transformation framework that lets analytics engineers write transformations using SQL and software engineering best practices like version control and testing.
- Fivetran: A fully managed ELT platform providing pre-built connectors to automate data ingestion from SaaS apps and production databases.
- Airbyte: An open-source data integration engine that offers highly customizable connectors for diverse data movement needs.
Data Observability Tools
Observability tools provide deep visibility into data quality, volume trends, and structural schema changes. Notable platforms include:
- Monte Carlo: An enterprise data observability platform that uses machine learning to automatically flag data anomalies and trace end-to-end data lineage.
- Great Expectations: An open-source python framework used for validating, documenting, and profiling data inside active pipelines.
Comparison Tables
| Tool | Purpose | Difficulty | Enterprise Usage |
| Apache Airflow | Workflow Orchestration | Moderate to High | Core orchestrator for scheduling large, complex pipelines |
| dbt | Data Transformation | Low to Moderate | Modular SQL transformations and pipeline testing |
| Fivetran | Managed Data Ingestion | Low | Automated, zero-maintenance SaaS and database syncing |
| Monte Carlo | Data Observability | Moderate | End-to-end anomaly detection and data lineage tracking |
| Airbyte | Open-Source Ingestion | Low to Moderate | Custom data integration and cost-effective data moving |
Real-World Use Cases of DataOps Automation
Banking & Finance
Financial institutions use DataOps automation to ingest millions of global transactions securely, validate account data for fraud patterns, and generate compliance reports. Automated pipelines isolate anomalous records instantly, ensuring that fraud models receive fresh, clean data while maintaining continuous regulatory reporting.
Healthcare Analytics
Healthcare networks apply DataOps workflows to consolidate electronic health records, pharmacy inventories, and patient monitoring streams. These automated pipelines process sensitive data under strict privacy rules, anonymizing PII before updating research databases and clinical dashboards.
E-Commerce Platforms
Online retailers utilize automated pipelines to combine user clickstreams, inventory counts, and payment data. This unified data lets recommendation engines dynamically adjust product suggestions and gives supply chain managers real-time views into inventory levels.
SaaS Companies
Software-as-a-Service firms deploy DataOps automation to track application usage telemetry, subscription lifecycles, and customer success interactions. This centralized data powers product usage analysis, helps predict customer churn, and drives automated feature-adoption campaigns.
Benefits of DataOps Automation Tools
Implementing professional DataOps automation tools transforms how data engineering teams operate, delivering measurable improvements to both technical systems and business outcomes.
- Faster Pipeline Deployment: Engineers can test and deploy pipeline changes through automated CI/CD workflows in minutes, eliminating manual staging setups.
- Improved Data Reliability: Inline testing frameworks catch schema mutations and missing values early, preventing bad data from corrupting downstream dashboards.
- Better Collaboration: Version-controlled code and shared repository structures remove siloes, aligning data engineers, analysts, and business owners.
- Reduced Operational Cost: Automated resource management spins down idle database servers and compute clusters when pipelines finish, preventing unnecessary cloud spend.
- Scalable Analytics Infrastructure: Cloud-native tools scale up compute power automatically to process massive data spikes without manual server provisioning.
Challenges & Limitations
While DataOps automation provides massive operational advantages, enterprise deployment presents clear technical hurdles that teams must navigate carefully.
Complex Integrations
Connecting legacy internal databases, third-party cloud applications, and diverse storage environments can create complex architectural webs that are difficult to debug.
Solution: Use standard, open-source integration frameworks and follow strict architectural design patterns to keep pipelines uniform and maintainable.
Data Quality Issues
Automated pipelines process data rapidly, meaning that unvalidated errors at the ingestion source can quickly spread throughout downstream analytical environments.
Solution: Build automated testing rules directly into the ingestion phase to isolate bad data before it reaches production environments.
Skill Shortages
Designing, building, and maintaining modern distributed orchestration environments requires deep expertise across cloud infrastructure, software engineering, and traditional database design.
Solution: Invest in structured team training programs and utilize accessible platforms like TheDataOps to upskill existing analysts and engineers.
DataOps Career Opportunities
The massive corporate shift toward automated data pipelines has created a highly competitive job market for professionals skilled in DataOps principles.
Key Professional Roles
- DataOps Engineer: Focuses on pipeline infrastructure, CI/CD automation pipelines, cluster management, and monitoring stacks.
- Data Engineer: Builds data collection architectures, designs robust transformation workflows, and optimizes data schemas.
- Analytics Engineer: Works at the intersection of data engineering and business analysis, transforming clean datasets into production-ready analytical models.
- Data Platform Engineer: Develops internal tooling, manages large-scale cloud data warehouses, and ensures platform governance.
Skills and Salaries
To excel in these roles, professionals need strong SQL fundamentals, proficiency in Python scripting, hands-on experience with orchestration engines like Airflow, and a solid understanding of cloud-native architectures. Daily responsibilities include reviewing pipeline performance, writing infrastructure-as-code templates, and fixing data validation failures.
The surging demand for these skills reflects directly in compensation. In major global technology hubs and across India’s enterprise tech centers, DataOps specialists command significant salary premiums over traditional database administrators, making it one of the fastest-growing and most rewarding paths in the cloud infrastructure sector.
Beginner Roadmap for Learning DataOps
Breaking into the DataOps space requires a step-by-step learning approach that builds solid technical fundamentals before moving on to complex cloud orchestration.
1. Core Prerequisites
Start by mastering SQL and Python fundamentals. You must be able to write complex multi-table joins, use window functions, and write clean, modular Python scripts that interact with web APIs and local file systems.
2. Systems & Version Control
Learn standard Linux command-line operations and Git version control. You need to know how to navigate server file systems, manage system permissions, write basic bash utility scripts, and handle Git branching workflows comfortably.
3. Data Engineering Fundamentals
Understand the core principles of database modeling, storage structures, and the functional differences between transactional databases and analytical warehouses. Practice building local ETL pipelines that extract raw CSV logs and load them into a database.
4. Workflow Orchestration
Learn to manage automated dependencies using open-source tools like Apache Airflow or Prefect. Start by writing simple Directed Acyclic Graphs (DAGs) that execute sequential processing scripts on local cron-style schedules.
5. Cloud Architectures & Observability
Deploy your workflows onto modern cloud platforms like AWS, GCP, or Azure. Learn to use containerization tools like Docker to package your pipelines cleanly, and set up automated data validation testing using frameworks like Great Expectations to ensure end-to-end data health.
Certifications & Training
Validating your practical skills through structured training and industry-recognized certifications can help you stand out to enterprise recruiters.
| Certification | Level | Best For | Skills Covered |
| TheDataOps Certified Associate | Beginner | Early-career engineers and data analysts | Core pipeline automation, basic orchestration, and data testing |
| Astronomer Certified Airflow Fundamentals | Intermediate | Data engineers and pipeline developers | DAG development, task scheduling, and Airflow orchestration |
| AWS Certified Data Engineer – Associate | Intermediate | Cloud engineers and platform architects | Cloud data ingestion, storage optimization, and secure infrastructure |
| dbt Analytics Engineering Certification | Intermediate | Analytics engineers and BI developers | Modular SQL modeling, version control, and data validation testing |
Common Beginner Mistakes
- Ignoring Data Quality: Beginners often focus solely on moving data quickly, neglecting to write automated testing steps until corrupted records break downstream reporting models.
- Learning Too Many Tools Together: Trying to master Airflow, Prefect, Dagster, and dbt all at once leads to confusion. Focus on building deep competence with one core tool stack first.
- Skipping SQL Fundamentals: Relying entirely on visual tools or drag-and-drop ingestion engines without understanding underlying SQL query optimization leads to slow, expensive production pipelines.
- Lack of Hands-on Projects: Memorizing video lectures and theoretical frameworks won’t prepare you for production incidents. Build and deploy real, functioning pipelines using open-source tools.
- Ignoring Monitoring and Governance: Forscripts often omit error logging and data access audits, making them dangerous to deploy inside regulated enterprise environments.
Best Practices for DataOps Automation
Following established industry engineering standards prevents production downtime and keeps enterprise data platforms maintainable as teams scale.
Automation-First Mindset
Never perform a pipeline task manually if it needs to run more than once. Every infrastructure update, database schema modification, and data ingestion stream should be declared as code, version-controlled, and executed through automated pipelines.
Continuous Testing
Run automated quality validation checks at every step of your workflow. Test incoming data at the ingestion layer, run schema checks during transformation steps, and confirm metric distributions before publishing datasets to business teams.
Version Control for Data
Keep all pipeline code, infrastructure configurations, and transformation models stored safely inside unified Git repositories. This practice ensures that every modification is clearly logged, peer-reviewed, and easily revertible if a production incident occurs.
Observability Implementation
Go beyond basic system uptime alerts by tracking data-specific telemetry. Monitor your pipelines for data freshness delays, unexpected volume drops, and schema mutations so your team can catch data incidents before business users do.
Future of DataOps Automation
The data industry is moving quickly toward autonomous data ecosystems that require minimal manual configuration and tuning.
Future platforms will feature AI-driven analytics automation, where metadata collection layers dynamically optimize indexing structures, rewrite slow-running transformation queries, and scale cloud infrastructure sizes based on historical usage patterns.
Real-time DataOps will expand significantly, moving away from batch architectures toward continuous stream processing as the standard framework for enterprise operations. Data observability systems will evolve from simple alerting tools into intelligent, self-healing orchestration engines capable of automatically correcting validation errors and routing corrupted data into isolation zones without human intervention. This shift underscores why gaining hands-on pipeline experience today ensures long-term career growth as these automated architectures become standard across the globe.
FAQs
1. What are DataOps automation tools?
DataOps automation tools are software technologies designed to automate the ingestion, transformation, scheduling, and monitoring of enterprise data workflows. They replace manual scripting by treating data pipelines as continuous production lines with built-in version control and automated testing.
2. How is DataOps different from DevOps?
DevOps focuses on automating code deployments, application stability, and server management for software products. DataOps applies similar agile and CI/CD principles specifically to data management, focusing on data quality, processing pipelines, and analytical data freshness.
3. Which tools are best for DataOps pipelines?
The ideal tool stack depends on your architecture, but industry standard options include Apache Airflow or Prefect for workflow orchestration, dbt for SQL data transformations, Fivetran or Airbyte for data ingestion, and Monte Carlo or Great Expectations for data quality validation.
4. Is coding required for DataOps?
Yes, technical proficiency is required. While some tools offer drag-and-drop data integration options, managing enterprise pipelines effectively requires a solid understanding of SQL for data transformation, Python for writing orchestration logic, and bash scripting for server management.
5. What is workflow orchestration?
Workflow orchestration is the automated management of dependencies and execution paths across data engineering tasks. It schedules jobs, passes variable states between pipelines, runs retry logic on failures, and ensures steps occur in the correct sequence.
6. Can beginners learn DataOps?
Yes, beginners can certainly learn DataOps if they follow a structured roadmap. Start by building deep competence in SQL and Python basics, then practice building simple data pipelines using open-source tools before moving on to complex cloud orchestration platforms.
7. Which cloud platform is best for DataOps?
All major cloud environments—AWS, Google Cloud Platform, and Microsoft Azure—provide excellent, comprehensive suites of cloud-native data tools. Choose the cloud platform that aligns with your organization’s existing production application infrastructure.
8. How long does it take to learn DataOps?
With dedicated daily study and hands-on practice, a beginner with basic tech literacy can learn foundational DataOps concepts and build working pipelines within six to nine months. Gaining master-level architectural expertise generally requires a few years of managing real-world production incidents.
9. What is data observability?
Data observability is the proactive monitoring of data health across pipelines. It tracks data volume shifts, data freshness delays, and schema mutations to catch data processing errors automatically before they break downstream reporting dashboards.
10. What is dbt and why is it popular?
dbt (Data Build Tool) is a transformation framework that lets analytics engineers write data cleanup transformations using standard SQL queries. It is highly popular because it brings software engineering best practices like version control, modular testing, and automated documentation directly to data analysts.
11. Why is data lineage important?
Data lineage maps the entire journey of your data assets, showing exactly where a specific metric originated and how it was modified. This clear visibility speeds up debugging during pipeline failures and simplifies regulatory data compliance audits.
12. How do data lakes differ from data warehouses?
Data lakes store raw, unstructured data in its native format at low cost, making them ideal for data science exploration. Data warehouses store clean, highly structured data optimized for fast SQL queries, making them ideal for corporate business intelligence.
13. What is Change Data Capture (CDC)?
Change Data Capture is an automated ingestion technique that monitors source database transaction logs and streams updates—such as row inserts, edits, or deletes—instantly into data warehouses without placing heavy strain on production apps.
14. What is continuous data integration?
Continuous data integration is the ongoing practice of automatically extracting data from source applications, validating its schema, testing its quality, and merging it into analytical systems to ensure corporate dashboards reflect real-time business operations.
15. How does DataOps control cloud computing costs?
DataOps controls expenses through infrastructure automation, allowing systems to provision computing power dynamically when pipelines run and shut down cloud database instances automatically when processing tasks complete.
Final Thoughts
The demand for fully automated data infrastructure continues to expand rapidly across the global technology landscape. As companies move away from brittle, manual data management workflows, the ability to build and orchestrate scalable pipelines has become a foundational requirement for modern data engineering teams.
To succeed in this evolving space, prioritize hands-on project experience above theoretical reading. Build real pipelines, break them intentionally to understand their failure points, and learn how to implement automated monitoring frameworks to catch errors early. Investing time into learning these automated architectures today positions you for long-term career growth as data automation continues to transform enterprise business intelligence.