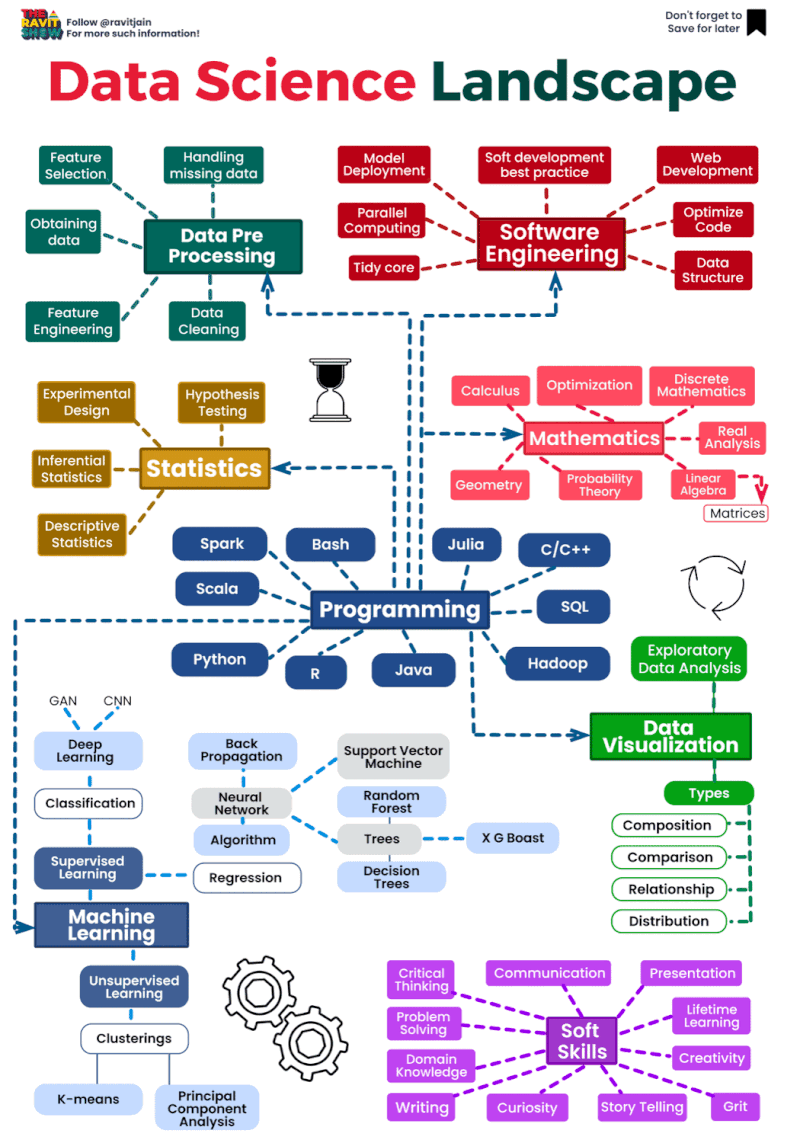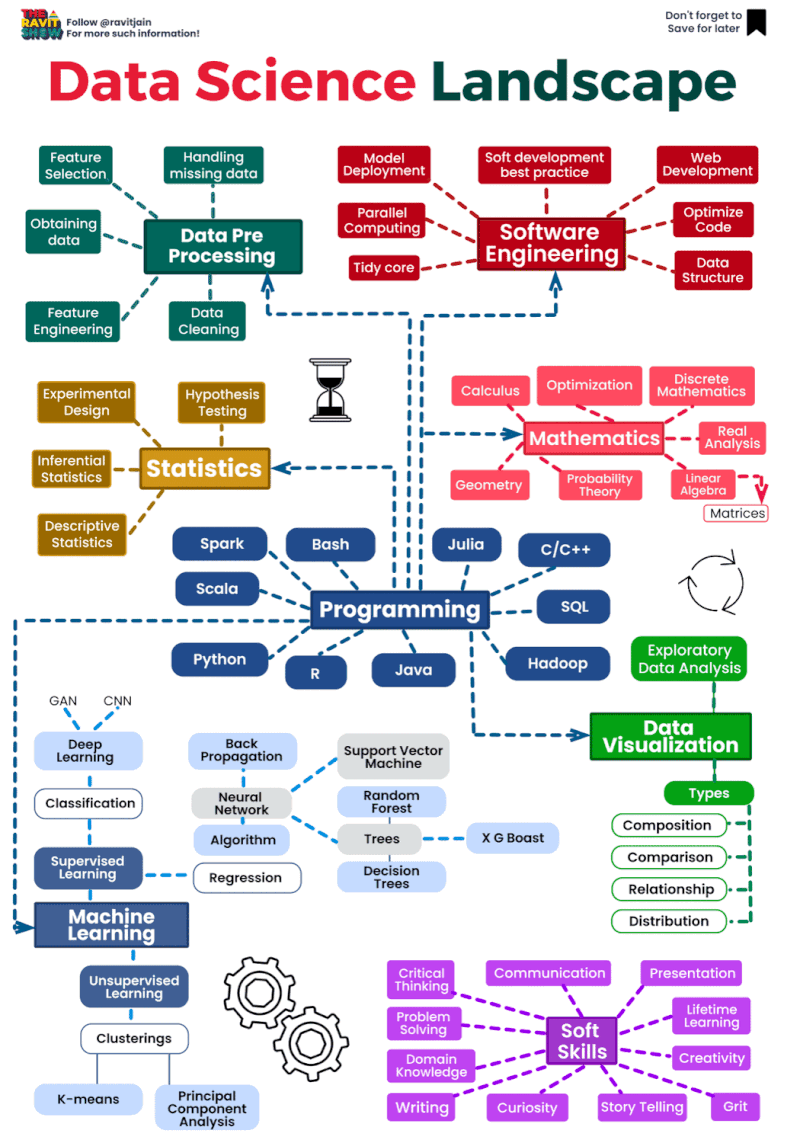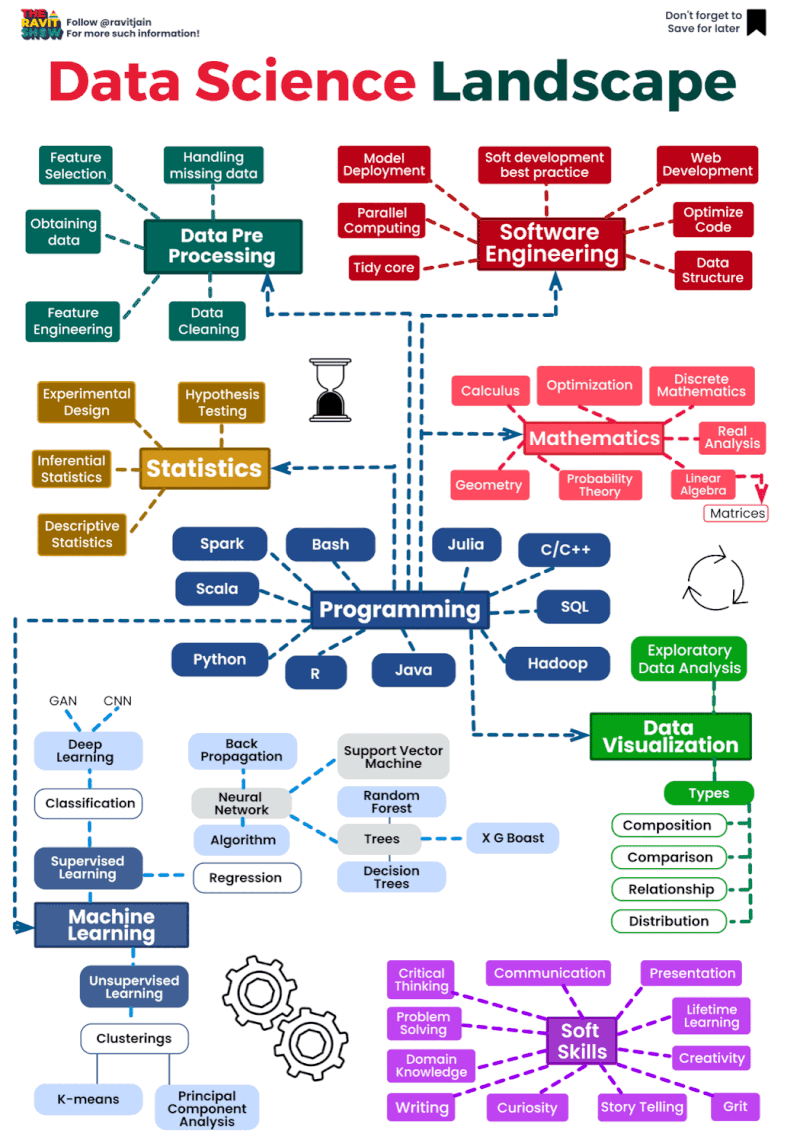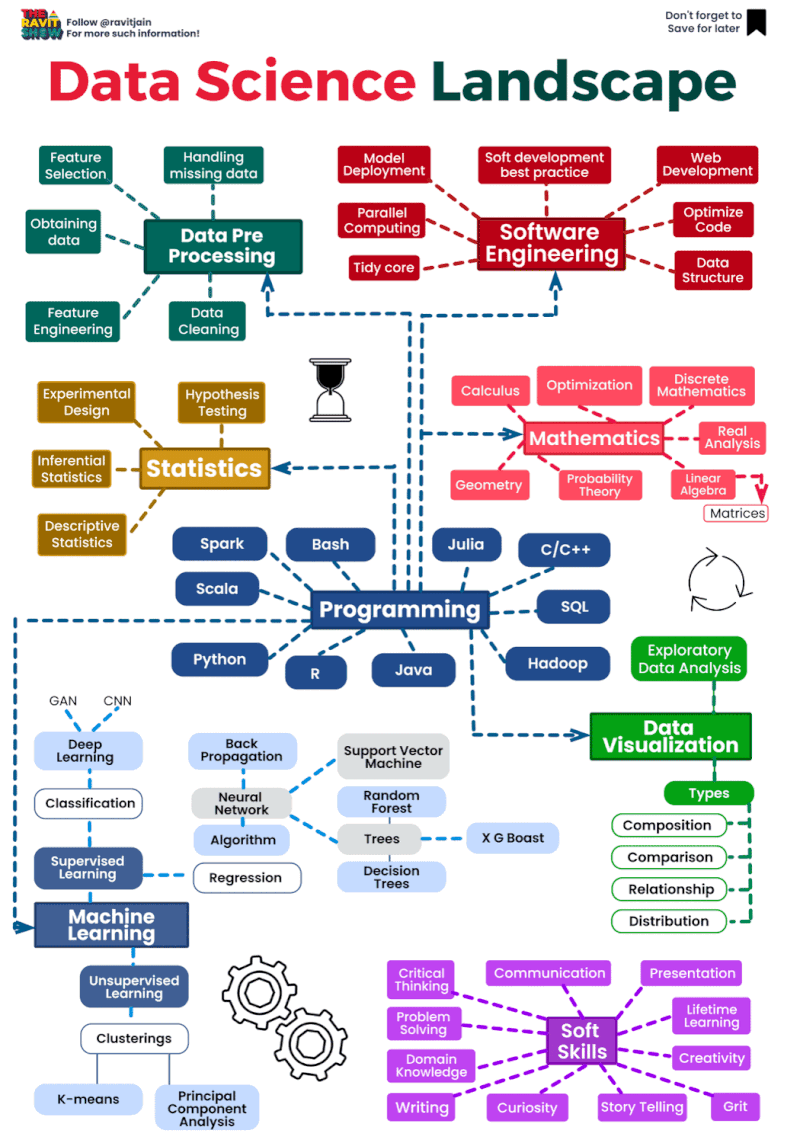
The data science landscape is constantly evolving, as new technologies and techniques emerge. However, there are a number of core areas that remain important for data scientists to have expertise in. These include:
- Statistics: Data scientists need to have a strong understanding of statistical concepts, such as probability, sampling, and hypothesis testing. This allows them to draw meaningful insights from data and to develop predictive models.
- Machine learning: Machine learning is a subfield of artificial intelligence that allows computers to learn without being explicitly programmed. Data scientists use machine learning to develop algorithms that can identify patterns in data and make predictions.
- Programming: Data scientists need to be able to program in order to develop and implement algorithms, and to analyze and visualize data. Popular programming languages used by data scientists include Python, R, and Scala.
- Cloud computing: Cloud computing platforms such as AWS, Azure, and GCP provide data scientists with access to powerful computing resources and tools. This allows them to scale their data science projects and to collaborate with other data scientists.
- Communication: Data scientists need to be able to communicate their findings to both technical and non-technical audiences. This is important for ensuring that their work is used to make informed decisions.
The data science landscape is a dynamic and rapidly evolving field that encompasses a wide range of techniques, tools, and technologies for extracting insights and knowledge from data. Here’s an overview of key components and trends within the data science landscape:
- Data Collection and Storage:
- Data Sources: Data scientists gather data from various sources, including databases, APIs, sensors, social media, and more.
- Data Warehouses: Data is often stored in data warehouses or data lakes, allowing for centralized storage and efficient retrieval.
- Data Preprocessing:
- Data Cleaning: This involves handling missing values, outliers, and inconsistencies in the data.
- Feature Engineering: Creating new features or transforming existing ones to improve model performance.
- Exploratory Data Analysis (EDA):
- Data Visualization: EDA involves creating visualizations to understand data patterns and relationships.
- Statistical Analysis: Data scientists use statistical methods to uncover insights and correlations in the data.
- Machine Learning and Modeling:
- Supervised Learning: Building models that make predictions based on labeled data.
- Unsupervised Learning: Discovering patterns and structures in unlabeled data.
- Deep Learning: Leveraging neural networks for complex tasks like image and natural language processing.
- Reinforcement Learning: Teaching agents to make sequential decisions through trial and error.
- Model Evaluation and Validation:
- Cross-Validation: Ensuring models generalize well to new data.
- Hyperparameter Tuning: Optimizing model parameters for better performance.
- Bias and Fairness Analysis: Checking for biases and ensuring fairness in models, especially in sensitive domains.
- Deployment and Productionization:
- Model Deployment: Taking trained models and integrating them into production systems.
- Monitoring: Continuously monitoring models for performance and drift.
- Scalability: Ensuring models can handle large-scale data and user traffic.
- Big Data Technologies:
- Hadoop: Distributed storage and processing framework.
- Spark: In-memory, distributed data processing.
- NoSQL Databases: Storing and retrieving unstructured or semi-structured data.
- Cloud Computing:
- Cloud platforms like AWS, Azure, and Google Cloud provide scalable infrastructure for data storage, processing, and analytics.
- Natural Language Processing (NLP):
- Analyzing and generating human language text, enabling chatbots, sentiment analysis, and language translation.
- Computer Vision:
- Using machine learning to interpret and understand images and videos, with applications in object recognition, image classification, and autonomous vehicles.
- AI Ethics and Responsible AI:
- Ensuring ethical use of AI and addressing issues related to bias, fairness, transparency, and privacy.
- Automated Machine Learning (AutoML):
- Tools and platforms that automate the process of selecting, training, and deploying machine learning models.
- IoT and Sensor Data:
- Analyzing data from Internet of Things (IoT) devices and sensors for applications like predictive maintenance and smart cities.
- Data Governance and Compliance:
- Managing data to ensure quality, security, and compliance with regulations like GDPR.
- Data Science Toolkits and Libraries:
- Python and R are popular programming languages for data science, and there are numerous libraries like scikit-learn, TensorFlow, and PyTorch for machine learning.
- Data Science Team Roles:
- Data scientists, data engineers, machine learning engineers, and data analysts collaborate to deliver data-driven solutions.
- Education and Skill Development:
- Ongoing learning and development are essential in this rapidly changing field.
- Interdisciplinary Applications:
- Data science is applied in various domains, including healthcare, finance, e-commerce, marketing, and more.