Introduction
In the world of data engineering, there are several tools that play a crucial role in processing and managing large volumes of data. In this article, we will explore some of the popular data engineering tools including Apache Beam, Apache Flink, Apache NiFi, Apache Kafka, and AWS Glue. These tools provide various capabilities for data ingestion, processing, transformation, and analysis. So, let’s dive in and understand what each of these tools has to offer.

Apache Beam
Apache Beam is an open-source unified programming model that allows you to write batch and streaming data processing pipelines. It provides a high-level API that abstracts the complexities of distributed data processing. With Apache Beam, you can write your data processing logic in a language-agnostic way and execute it on various execution engines such as Apache Flink, Apache Spark, and Google Cloud Dataflow. This flexibility makes Apache Beam a powerful tool for building scalable and portable data pipelines.
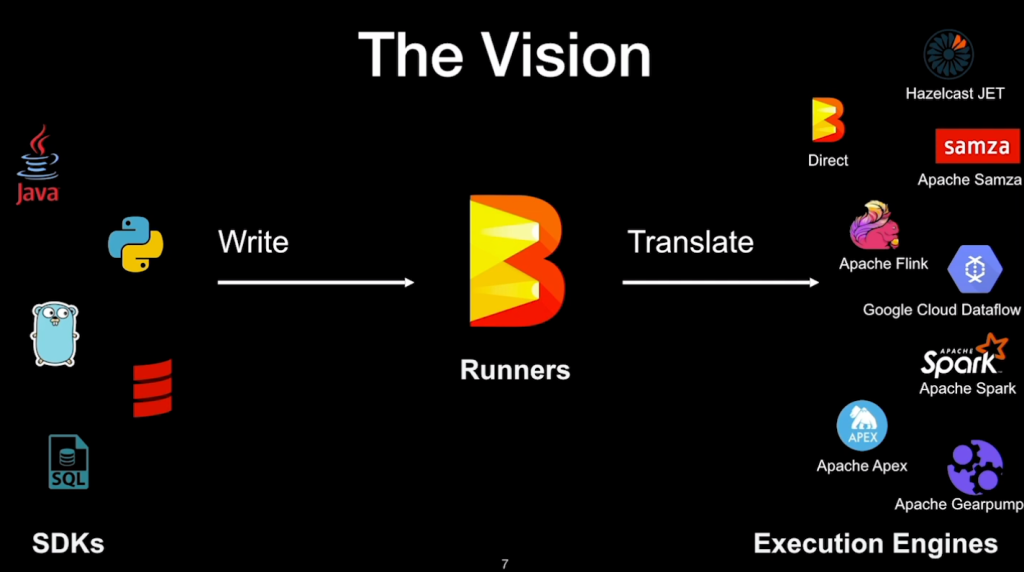
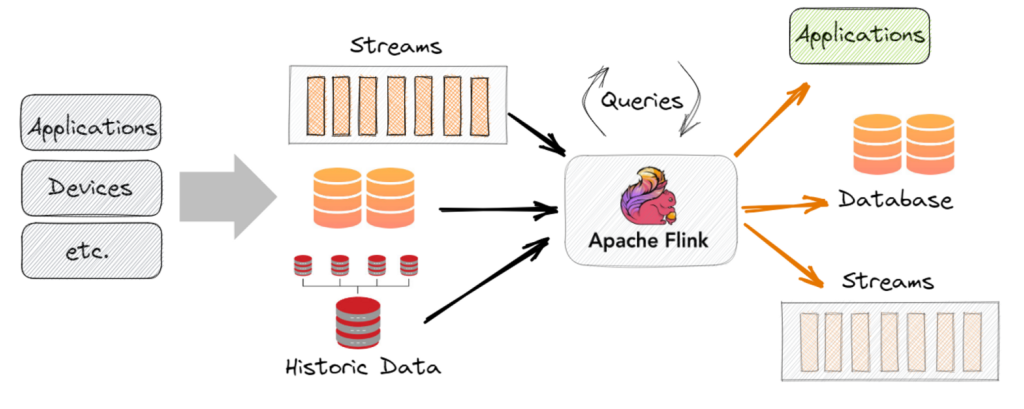
Apache Flink
Apache Flink is a powerful stream processing framework that enables real-time data processing at scale. It provides support for both batch and stream processing, making it suitable for a wide range of use cases. Apache Flink offers fault-tolerance, exactly-once processing semantics, and low-latency processing, making it ideal for applications that require real-time insights from streaming data. Additionally, it has a rich set of APIs and libraries for complex event processing, state management, and advanced analytics.
Apache NiFi
Apache NiFi is a data integration and data flow management tool that provides a visual interface for designing and managing data flows. It allows you to easily create, monitor, and modify data flows using a drag-and-drop interface. Apache NiFi supports a wide range of data sources and destinations, including databases, message queues, APIs, and file systems. It also provides data provenance tracking, data encryption, and fine-grained access control, making it a secure and reliable tool for data integration and processing.
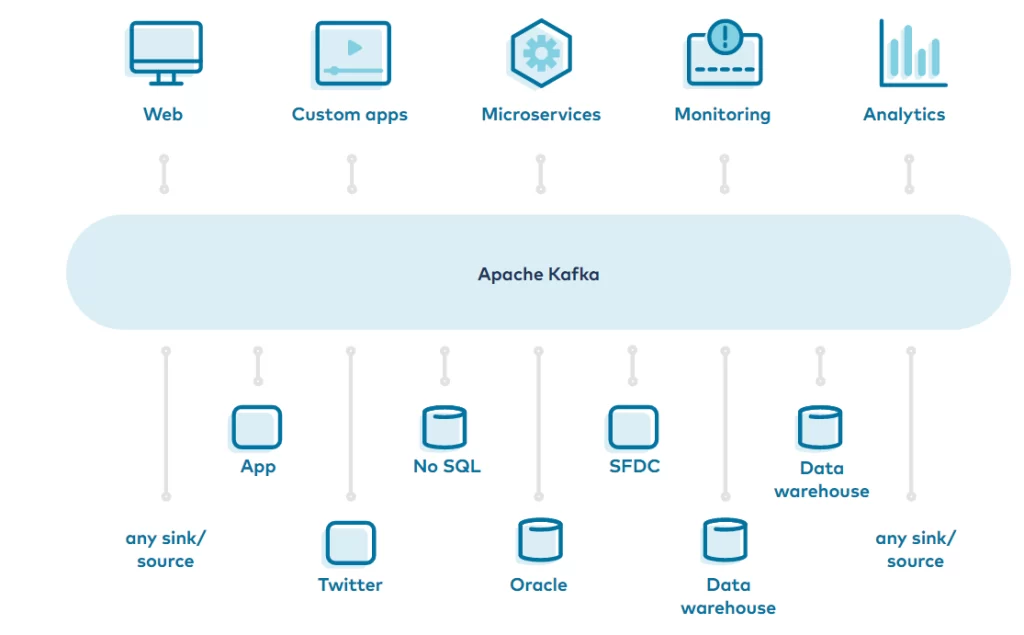
Apache Kafka
Apache Kafka is a distributed streaming platform that provides a scalable, fault-tolerant, and high-throughput messaging system. It is designed to handle large volumes of real-time data streams from various sources and make them available for processing and analysis. Apache Kafka uses a publish-subscribe model, where producers send messages to topics, and consumers subscribe to those topics to receive the messages. It provides durability, fault tolerance, and strong ordering guarantees, making it a popular choice for building real-time data pipelines.
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service provided by Amazon Web Services. It makes it easy to prepare and load data for analytics using a serverless architecture. AWS Glue automatically discovers, catalogs, and transforms your data, making it available for analysis in various AWS services such as Amazon Redshift, Amazon S3, and Amazon Athena. It provides a visual interface for creating ETL jobs and supports a wide range of data sources, including databases, data lakes, and streaming data.
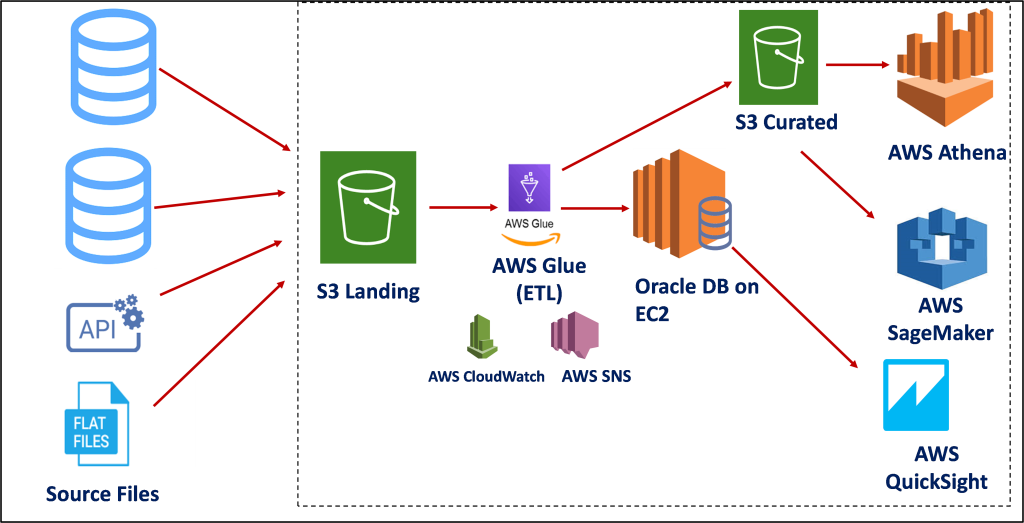
Conclusion
In this article, we have explored some of the popular data engineering tools including Apache Beam, Apache Flink, Apache NiFi, Apache Kafka, and AWS Glue. These tools offer a wide range of capabilities for data ingestion, processing, transformation, and analysis. Whether you need real-time stream processing, batch processing, data integration, or data preparation for analytics, these tools provide the necessary features to meet your data engineering needs. So, choose the right tool based on your requirements and leverage the power of data engineering to unlock valuable insights from your data.