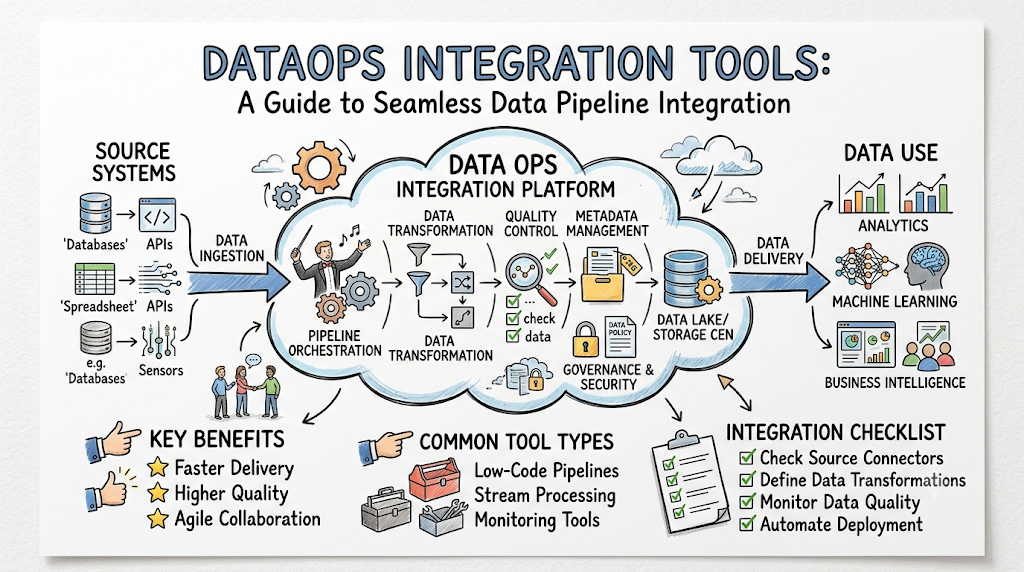
Modern enterprise organizations generate vast quantities of information across dozens of isolated systems. Managing this distributed ecosystem requires engineering infrastructure that can ingest, process, and deliver data reliably. Without a cohesive strategy, systems become fragmented, data pipelines break frequently, and business intelligence teams lose trust in their reporting metrics. To overcome these challenges, organizations are adopting DataOps principles to unify development and operations workflows. By utilizing advanced DataOps integration tools, engineering teams can build resilient, self-healing architectures. For comprehensive blueprints and deep dives into building agile data ecosystems, visit TheDataOps, a dedicated resource helping teams master automated engineering principles.
Key Takeaways
- DataOps integration tools eliminate corporate data silos by connecting heterogeneous cloud platforms, on-premises systems, and edge devices.
- Transitioning from traditional ETL to modern ELT strategies reduces latency and leverages the compute power of modern cloud data warehouses.
- Automated data orchestration, deep observability, and proactive monitoring prevent pipeline failures and ensure consistent data quality.
- Robust data governance practices must be embedded directly within the integration workflow to maintain security and regulatory compliance.
What is DataOps?
DataOps is an automated, collaborative methodology designed to improve the quality, speed, and predictability of data analytics and data engineering workflows. Derived from a combination of DevOps, Agile development, and Lean manufacturing principles, DataOps focuses on optimizing the entire data lifecycle. It treats data pipelines as manufacturing lines where quality control, automated testing, and continuous deployment are integrated into every stage.
In modern data engineering, DataOps acts as the foundational framework that governs how code and data move from development environments to production. Traditionally, data engineers worked in isolation from data analysts and business stakeholders, leading to misaligned requirements and frequent pipeline errors. DataOps breaks down these structural walls by introducing collaborative workspaces, version control for data infrastructure, and automated continuous integration and continuous deployment (CI/CD) pipelines.
[Dev / Version Control] ---> [Automated Testing] ---> [CI/CD Deployment]
|
v
[Continuous Optimization] <-- [Real-time Monitoring] <-- [Production Pipelines]
Implementing DataOps delivers significant improvements to overall pipeline efficiency. By automating manual validation processes, organizations reduce the time required to deploy new data products from weeks to hours. Statistical process control monitors the data moving through pipelines in real time, alerting engineers to anomalies before corrupted information reaches downstream business intelligence dashboards.
What Are Integration Tools in DataOps?
DataOps integration tools are specialized software applications and platforms designed to facilitate the seamless movement, transformation, and synchronization of data across an enterprise network. These tools act as the connective tissue within a data ecosystem, bridging the gap between legacy databases, modern cloud data warehouses, third-party software-as-a-service (SaaS) applications, and streaming data feeds. They ensure that data flows smoothly from one repository to another while maintaining architectural integrity.
In automated workflows, these integration tools are necessary to eliminate manual data handling and script writing. Historically, engineers relied on custom Python scripts or cron jobs to move data, a practice that scales poorly and introduces significant maintenance overhead. Modern integration platforms replace these fragile systems with declarative configurations, visual workflow designers, and native connectors that automatically adapt to schema changes.
+-------------------------------------------------------------------------+
| DataOps Integration Tool |
| |
| +------------------+ +-----------------------+ +------------+ |
| | Legacy Databases | --> | Schema Mapping Engine | --> | Cloud Data | |
| | & SaaS Platforms | | & Transformation Core | | Warehouses | |
| +------------------+ +-----------------------+ +------------+ |
+-------------------------------------------------------------------------+
Furthermore, integration tools play a critical role in connecting highly heterogeneous systems. An enterprise may store transactional records in an on-premises Oracle database, tracking events via an external web application, and managing customer relationships through a cloud platform. A robust DataOps integration tool abstracts the underlying complexity of these differing APIs, protocols, and data formats, presenting a unified interface for data ingestion and synchronization.
Importance of Integration in DataOps
Breaking Down Data Silos
Data silos occur naturally as different departments adopt specialized software solutions to manage their daily operations. When marketing, sales, finance, and product teams use separate platforms without a central integration strategy, information becomes trapped within those specific business units. This isolation prevents an organization from achieving a comprehensive view of its operations, leading to conflicting metrics and missed business opportunities. Integration tools break down these boundaries by consolidating disparate data sets into a single, accessible repository.
Meeting Real-Time Data Flow Requirements
Modern business operations require immediate access to operational insights to remain competitive. Batch processing systems that run once a day are no longer sufficient for use cases such as fraud detection, dynamic pricing, or real-time inventory management. DataOps integration tools enable continuous data processing, allowing companies to respond to market shifts and consumer behavior patterns as they occur.
Overcoming Scalability Challenges
As corporate data volumes grow from gigabytes to petabytes, traditional infrastructure becomes overwhelmed. Without automated integration platforms, data engineering teams spend most of their time manually tuning queries, resizing hardware, and partitioning tables to keep up with data velocity. DataOps integration tools leverage cloud-native architectures to scale compute and storage resources dynamically, ensuring consistent performance regardless of data volume.
Driving Accurate Business Decisions
The final objective of any data initiative is to provide executives and operational teams with reliable information for strategic planning. If the underlying data pipelines rely on fragmented or unverified information, the resulting business decisions will be flawed. Unified integration workflows ensure that downstream data systems receive clean, well-formatted, and mathematically accurate inputs, establishing a trusted foundation for predictive modeling and business intelligence.
Types of DataOps Integration Tools
DataOps Integration Ecosystem
├── Batch Processing
│ ├── ETL (Extract, Transform, Load)
│ └── ELT (Extract, Load, Transform)
└── Real-time & Orchestration
├── Pipeline Orchestration
├── API-based Integration
└── Event Streaming
ETL (Extract, Transform, Load) Tools
Traditional ETL tools extract information from source systems, transform it within a dedicated staging area or memory space, and load the finalized records into a target database. This approach is highly effective when dealing with legacy target systems that lack advanced processing capabilities. ETL tools ensure that data is completely cleansed, normalized, and restructured before it ever hits the primary data warehouse, preserving storage space and protecting target systems from unformatted data.
ELT Tools
Modern cloud data architectures have driven the rapid adoption of ELT (Extract, Load, Transform) approaches. Instead of performing transformations in an external staging environment, ELT tools extract raw data from sources and load it directly into cloud data warehouses like Snowflake, BigQuery, or Amazon Redshift. Once loaded, the tools leverage the massive parallel processing power of the cloud data warehouse to execute transformations using SQL. This shift reduces ingestion latency and provides data analysts with immediate access to raw, unaltered historical data.
Data Pipeline Orchestration Tools
Orchestration engines manage the execution order, dependencies, and timing of various data workflows. They do not typically move data directly; instead, they act as the control plane that triggers extraction jobs, runs transformation models, executes data quality tests, and sends notifications upon failure. Orchestration tools use code to define complex directed acyclic graphs (DAGs), ensuring that a transformation task only starts after its corresponding ingestion job completes successfully.
API-Based Integration Tools
API-driven integration platforms connect applications by interacting directly with their exposed web services, typically utilizing REST or GraphQL protocols. These tools are valuable for synchronizing cloud applications in real time, handling authentication, rate limiting, and payload serialization automatically. They allow data engineers to build lightweight, event-driven integrations without setting up heavy database replication infrastructure.
Streaming Data Integration Tools
For microsecond-level processing requirements, streaming data integration tools capture continuous event logs from applications, IoT sensors, and database change logs (CDC). These platforms handle high-throughput, low-latency queues, allowing organizations to process and analyze data while it is still in transit. Streaming tools are essential for building continuous operational dashboards, complex event processing engines, and real-time security alerts.
How Integration Tools Work in DataOps Pipelines
Source Systems ---> Ingestion ---> Transformation ---> Storage ---> Delivery
^ |
|___________ Monitoring & Guardrails ________|
Data Ingestion Layer
The data ingestion layer is responsible for establishing connections to various source systems and pulling data into the pipeline architecture. Integration tools utilize pre-built connectors or custom scripts to read transactional databases, file servers, or web APIs. Depending on the architecture, this layer executes jobs on a scheduled cron basis or listens for continuous updates via change data capture mechanisms. The main goal at this stage is to extract data efficiently without impacting the performance of production source databases.
Transformation Layer
Once the data is accessible, it enters the transformation layer, where it is cleansed, deduplicated, enriched, and restructured. During this phase, integration tools convert raw strings into appropriate data types, apply business logic, join disparate data sets, and mask sensitive information to protect user privacy. In an ELT pipeline, this transformation occurs inside the target repository through automated SQL execution, while in an ETL pipeline, it happens in flight within an in-memory processing engine.
Data Storage Layer
The storage layer serves as the secure repository where processed and raw data resides for analytical use. DataOps integration tools organize this layer into distinct zones, such as a raw landing zone, a cleansed conformance zone, and a structured presentation layer (often structured as a star schema or data vault). The integration platform manages the partitioned paths within data lakes or the internal tables within a cloud data warehouse to ensure optimal query performance for downstream consumers.
Data Delivery Layer
The data delivery layer ensures that ready-to-use information reaches its final destination, whether that is a business intelligence platform, a machine learning model, or an operational application reverse-ETL workflow. Integration tools format the output to match the precise consumption requirements of these target applications. This step ensures that analysts can query the data immediately without needing further adjustments or manual manipulation.
Monitoring Layer
Running throughout the entire pipeline architecture, the monitoring layer provides real-time visibility into the health and performance of data flows. Integration tools continuously track operational metrics, including row counts, ingestion latency, execution duration, and data validation errors. If a step fails or a schema change breaks a downstream table, the monitoring layer captures the stack trace, halts affected pipeline segments, and alerts engineers through communication channels before bad data pollutes production reports.
Popular Features of DataOps Integration Tools
| Feature | Technical Benefit | Business Impact |
| Automation Capabilities | Eliminates manual script scheduling and automates schema migration tasks. | Reduces operational costs and speeds up time-to-market for data projects. |
| Real-Time Processing | Processes continuous data streams via change data capture (CDC). | Enables immediate operational decisions and real-time fraud monitoring. |
| Scalability Support | Provisions cloud compute resources dynamically based on data load size. | Future-proofs data platforms against unpredictable enterprise data growth. |
| Data Validation | Runs inline quality assertions and checks schema compliance automatically. | Prevents corrupted reports and maintains organizational data trust. |
| Error Handling | Isolates failed records in dead-letter queues while continuing healthy runs. | Minimizes pipeline downtime and simplifies troubleshooting for engineering teams. |
| Logging & Observability | Generates detailed execution logs and end-to-end lineage maps. | Simplifies compliance auditing and shortens mean time to resolution (MTTR). |
DataOps Integration Workflow
1. Identify Sources -> 2. Extract -> 3. Transform -> 4. Sync -> 5. Monitor -> 6. Optimize
1. Data Source Identification
The integration workflow begins by mapping the complete data lineage of an enterprise. Engineers identify all relevant data sources required to solve a business problem, locating database credentials, API access tokens, and file system paths. During this phase, the engineering team evaluates the schema structures, update frequencies, and security classifications of each source system to plan the downstream architecture.
2. Data Extraction
With sources identified, the integration tool initiates the data extraction process. Engineers configure extraction parameters, choosing between a full snapshot or incremental loads based on a modified timestamp or database log. This stage relies heavily on optimized connection pools to ensure that pulling data from transactional production databases does not cause connection timeouts for active application users.
3. Data Transformation
Extracted data is passed to the transformation engine, where it undergoes restructuring to match target schemas. The tool applies standardized validation rules, such as verifying that email addresses contain valid characters, checking that currency fields are numerical, and converting timestamps into a uniform time zone. Any records that fail these foundational checks are automatically routed to a quarantine table for inspection.
4. Data Synchronization
Cleaned and transformed records are written directly to the target analytical environments. The integration tool manages the synchronization strategy, executing append operations, upserts (updating existing rows and inserting new ones), or complete table overwrites based on operational configurations. This step ensures that data warehouses remain accurately synchronized with upstream transactional applications.
5. Pipeline Monitoring
Once data is loaded into production tables, continuous monitoring systems evaluate pipeline execution telemetry. The system checks whether the number of imported rows matches historical averages and calculates whether ingestion latency falls within acceptable service-level agreements (SLAs). Metadata regarding the run status is logged into a central repository to establish clear operational baselines.
6. Feedback Loop Optimization
The final stage of the workflow focuses on continuous improvement. Engineers analyze the captured metadata over time to pinpoint performance bottlenecks, such as slow-running transformation queries or under-provisioned warehouse sizes. This performance data feeds back into the development lifecycle, allowing engineers to refine code, optimize configurations, and constantly improve pipeline reliability.
Real-World Use Cases
Cloud Data Migration
Enterprises frequently migrate legacy, on-premises data centers to modern cloud environments to reduce capital expenses and increase operational flexibility. DataOps integration tools facilitate this transition by maintaining parallel pipelines during the migration phase. The tools replicate historical data to the cloud while continuously syncing daily changes, enabling a smooth migration with zero organizational downtime.
Business Intelligence Dashboards
Corporate leadership teams rely on business intelligence platforms to monitor key performance indicators, revenue targets, and operational metrics. DataOps integration tools supply these dashboards with high-quality data by consolidating information from diverse software systems into a single reporting layer. Automated scheduling ensures that dashboards refresh at expected intervals, eliminating manual data compilation tasks.
E-Commerce Analytics Pipelines
Online retail environments generate millions of clickstream events, inventory changes, and purchase transactions every day. DataOps integration platforms connect these web events with back-end inventory databases and shipping logs. This unified pipeline allows e-commerce platforms to deploy automated dynamic pricing models, send abandoned cart notifications, and manage warehouse supply levels in real time.
[Clickstream Logs] ----\
[Inventory DB] --------+---> [DataOps Integration Tool] ---> [Real-time Analytics]
[Shipping Platform] ---/
Financial Data Integration
Financial institutions handle highly sensitive data from multiple sources, including credit card transactions, stock tickers, and customer bank accounts. Integration tools unify these data streams under strict governance protocols, allowing risk compliance engines to run complex fraud detection algorithms. The automation provided by DataOps ensures that these pipelines remain resilient against transactional spikes during peak market hours.
Healthcare Data Systems
Healthcare providers must unify data across diverse electronic health record (EHR) platforms, laboratory systems, and insurance claims repositories. DataOps integration tools securely connect these fragmented data sets while maintaining compliance with strict medical privacy regulations. The resulting integrated profiles allow clinicians to view comprehensive patient histories, leading to more accurate diagnoses and improved patient care outcomes.
Benefits of Integration Tools in DataOps
Faster Data Processing
By removing human intervention from the ingestion and transformation processes, integration tools accelerate the movement of information across an enterprise. Modern parallel processing and cloud optimization features allow pipelines to execute complex transformations in a fraction of the time required by legacy code. This velocity ensures that data reaches business users when it is most relevant.
Reduced Manual Effort
Manual data engineering tasks are time-consuming and prone to human error. DataOps integration tools automate infrastructure provisioning, pipeline scheduling, and schema evolution handling, freeing data engineers from routine maintenance tasks. Teams can redirect their engineering talent toward building advanced analytical features and optimizing machine learning models.
Traditional Management: [Manual Scripts] + [Cron Jobs] = High Maintenance Effort
DataOps Management: [Automated Ingestion Platforms] = Low Maintenance Effort
Improved Data Quality
DataOps integration tools integrate data quality checks directly into the active pipeline flow. By evaluating data against predefined business rules before it reaches production layers, these tools identify anomalies, missing values, and formatting drift instantly. This automated guardrail maintains the integrity of the target data warehouse and increases user trust in data products.
Better Scalability
Cloud-native integration tools effortlessly accommodate sudden increases in data volume without requiring architecture re-designs. As business operations expand, the integration platforms scale up compute capacity to handle heavy data loads and scale down when processing finishes. This flexibility controls infrastructure costs while maintaining stable processing times.
Real-Time Insights
The capability to process data streams continuously allows organizations to make operational decisions based on live information rather than yesterday’s reports. Integration platforms support modern streaming architectures, allowing businesses to identify market opportunities, resolve customer issues, and detect security vulnerabilities as they unfold.
Challenges in DataOps Integration
Complex System Architecture
As an organization grows, its data architecture naturally becomes more intricate, incorporating hybrid cloud systems, historical databases, and dozens of third-party APIs. Managing data movement across these complex environments presents a major challenge, as a failure in one legacy system can trigger a cascade of issues throughout the downstream pipeline.
Data Format Inconsistencies
Different applications store similar information in widely divergent structures. For example, a CRM platform might store customer names in a single field, while an ERP system splits them into first and last name columns. Resolving these formatting inconsistencies across hundreds of separate data feeds requires sophisticated transformation logic and constant schema monitoring.
Latency Issues
Achieving real-time data flow is technically challenging when dealing with legacy source databases that only support batch extraction. Attempting to pull data too frequently from production systems can strain database CPUs, resulting in slow performance for application users. Balancing data freshness requirements against source system stability is a constant architectural challenge.
High Frequency Pulls ---> Risk of Transactional Production DB Latency
Low Frequency Pulls ---> Risk of Stale Business Intelligence Reports
Security Concerns
Data pipelines routinely transport sensitive corporate information, including personally identifiable information (PII) and protected financial records. If an integration tool is improperly configured, this data can become exposed to unauthorized users during transit or storage. Engineering teams must ensure that encryption, access controls, and data masking are applied consistently across every pipeline segment.
Tool Compatibility Issues
The data engineering market contains an array of open-source projects, proprietary software solutions, and cloud-native services. Getting these disparate tools to work together harmoniously within a single DataOps framework can be difficult. Incompatible metadata standards, differing deployment scripts, and fragmented logging mechanisms often complicate platform integration efforts.
Best Practices
Standardize Data Formats
To reduce pipeline complexity, establish strict organization-wide standards for data formats, naming conventions, and timestamp fields. Ensure all integration processes convert incoming source data into standardized formats (such as ISO 8601 for dates and UTC for time zones) at the earliest entry point in the pipeline. This consistency simplifies downstream transformations and makes debugging straightforward.
Use Automated Pipelines
Eliminate all manual touchpoints within your production data flows. Use orchestration tools to manage task execution, dependency tracking, and error handling automatically. By treating your pipeline configurations as code and storing them in version control systems, you ensure that deployments are repeatable, auditable, and less prone to human error.
[Code Commit] ---> [Automated Testing] ---> [Zero-Touch Production Deployment]
Implement Strong Monitoring
Deploy end-to-end observability tools across your data pipeline network. Monitor key pipeline metrics, including data volume variations, processing duration, and schema adjustments. Configure proactive alerting systems to notify engineering teams the moment an anomaly is detected, allowing them to isolate and resolve infrastructure issues before they impact business users.
Ensure Data Governance
Incorporate data governance, compliance validation, and data lineage mapping directly into your active DataOps integration workflows. Implement strict role-based access control (RBAC) to restrict data access to authorized systems and users. Automatically log metadata regarding data transformations to maintain an immutable audit trail for regulatory compliance.
Optimize for Scalability
Design your integration pipelines with growth in mind by decoupling compute resources from your storage layers. Utilize stateless transformation engines that can scale horizontally to handle unexpected data spikes. Avoid hardcoding resource allocations; instead, leverage cloud-native elastic scaling features to optimize performance and control operational costs.
Future of DataOps Integration Tools
AI-Driven Integration Pipelines
The integration of artificial intelligence and machine learning into DataOps infrastructure will transform pipeline management. Future integration tools will automatically evaluate incoming data streams, infer schema designs, and generate optimal transformation code without manual engineering input. This automation will significantly reduce the time required to onboard new enterprise data sources.
Self-Healing Data Workflows
Pipeline failures caused by unexpected schema changes or network timeouts will be managed by self-healing automation frameworks. Future integration tools will analyze error patterns in real time, automatically adjusting query structures, isolating corrupted records, and rerouting workflows around system outages. This resilience will minimize pipeline downtime and lower operational maintenance overhead.
Pipeline Failure ---> AI Log Analysis ---> Automatic Schema Repair ---> Workflow Resumed
Real-Time Event-Driven Architecture
The industry is shifting away from batch-oriented schedules toward completely event-driven data architectures. Future integration ecosystems will treat all data as continuous streams of events, processing and validating transactions instantly as they occur. This evolution will give enterprises an accurate, real-time view of their operational data.
Low-Code/No-Code Integration Platforms
To address the data engineering talent shortage, integration tools are introducing advanced low-code and no-code visual interfaces. These user-friendly platforms will empower data analysts and business stakeholders to build secure, compliant integration pipelines independently. Data engineers can transition away from building basic ingestion pipelines and focus on optimizing core data platform architecture.
FAQ Section
1.What are DataOps integration tools?
DataOps integration tools are specialized software applications designed to automate the movement, transformation, and synchronization of data across an enterprise network. They connect disparate data sources—such as cloud applications, transactional databases, and legacy servers—to central data repositories while ensuring high data quality and pipeline reliability.
2.Why are integration tools important?
Integration tools are essential because they eliminate manual data handling, break down corporate data silos, and prevent pipeline failures. They automate complex workflows, scale dynamically to accommodate growing data volumes, and ensure that clean, trusted data is consistently delivered to business intelligence platforms for strategic decision-making.
3.What is ETL in DataOps?
ETL stands for Extract, Transform, Load. It is a traditional integration method where data is extracted from source systems, transformed into a standardized format within a temporary staging environment, and then loaded into a target data warehouse. This approach protects target systems from unformatted data and maintains high data consistency.
4.How does DataOps improve data integration?
DataOps improves integration by applying DevOps agility and Lean quality control principles to data pipelines. It introduces automated testing, continuous integration and deployment (CI/CD), and real-time observability into the data lifecycle, which reduces manual errors, lowers pipeline downtime, and accelerates the delivery of insights.
5.Which tools are used in DataOps pipelines?
DataOps pipelines utilize a combination of data ingestion engines (such as Fivetran or Airbyte), data transformation frameworks (such as dbt), and workflow orchestration platforms (such as Apache Airflow or Prefect). Together, these tools form a cohesive ecosystem that manages the end-to-end movement and validation of enterprise data.
6.What is the difference between ETL and ELT?
The primary difference lies in where the data transformation occurs. Traditional ETL transforms data in an intermediate staging environment before loading it into the target system. Modern ELT loads raw data directly into a high-performance cloud data warehouse first, utilizing the warehouse’s internal compute power to execute transformations using SQL.
7.How do integration tools handle data quality?
Integration tools enforce data quality by executing automated validation checks directly within active pipelines. These checks verify schema compliance, evaluate data against business logic rules, and catch missing or malformed inputs. Corrupted records are routed to quarantine areas for evaluation, preventing bad data from polluting production dashboards.
8.What is data orchestration in DataOps?
Data orchestration refers to the centralized management, scheduling, and sequencing of automated data workflows. Orchestration engines coordinate complex tasks across multiple systems, tracking dependencies to ensure that transformation and data quality analysis tasks only execute after ingestion workflows complete successfully.
Conclusion
Managing modern data pipelines requires specialized infrastructure that can scale dynamically alongside enterprise operations. DataOps integration tools serve as the core architecture that unifies fragmented data systems, automates complex transformation sequences, and ensures high data quality across the entire corporate network. By moving away from brittle manual scripts and adopting automated ELT/ETL frameworks, engineering teams build resilient systems that withstand sudden spikes in data velocity and volume.
As enterprise technology architectures evolve, integration strategies must transition toward automated, event-driven pipelines. Implementing robust orchestration engines, inline validation guardrails, and deep observability features allows organizations to eliminate data silos and deliver trusted, real-time insights to business leaders.