Data pipeline tools are software solutions designed to facilitate the movement and processing of data between different systems and applications. These tools automate the data flow, enabling organizations to efficiently extract, transform, and load (ETL) data from various sources to their desired destinations, such as data warehouses, data lakes, databases, or cloud storage platforms. Data pipeline tools play a crucial role in data integration, data migration, data synchronization, and data processing tasks.
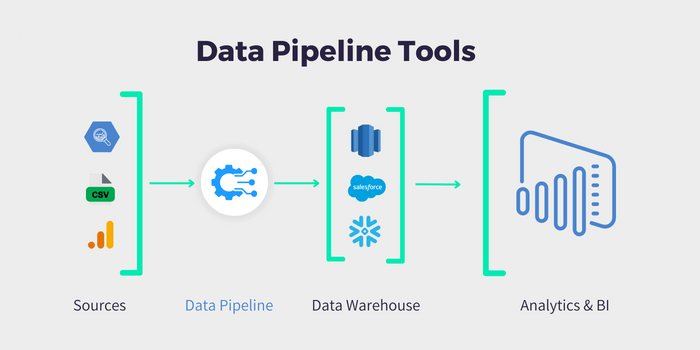
Key Features of Data Pipeline Tools:
- Data Connectivity: Data pipeline tools provide connectors and adapters to connect to diverse data sources, including databases, flat files, cloud services, web services, APIs, and big data platforms.
- Data Transformation: These tools offer data transformation capabilities to cleanse, enrich, and manipulate data during the data flow process. They support various data transformation operations and functions.
- Workflow Automation: Data pipeline tools allow users to design and automate data integration workflows or pipelines. They provide job scheduling and workflow orchestration features to manage the data flow process efficiently.
Popular Data Pipeline Tools:
- AWS Data Pipeline
- Apache Airflow
- Confluent
- Talend Pipeline Designer
- StreamSets Data Collector
1. AWS Data Pipeline
AWS Data Pipeline is a web service provided by Amazon Web Services (AWS) that allows users to automate the movement and processing of data between different AWS services and on-premises data sources. It enables organizations to create and manage complex data workflows, often referred to as data pipelines, to efficiently orchestrate data processing and data movement tasks.
Key Features of AWS Data Pipeline:
- Data Encryption: AWS Data Pipeline supports data encryption during data movement and data storage, ensuring data security and compliance with data privacy regulations.
- Scalability: Data Pipeline automatically scales resources to handle large volumes of data and process data efficiently.
- Cross-Region and Cross-Account Data Movement: AWS Data Pipeline supports data movement across AWS regions and AWS accounts, enabling data integration across different environments.
2. Apache Airflow
Apache Airflow is an open-source platform used for orchestrating and scheduling complex data workflows. It enables users to define, schedule, and monitor data pipelines, which are sequences of tasks that process and move data from various sources to desired destinations. Airflow is highly scalable, extensible, and easy to use, making it a popular choice for data engineers and data scientists to manage their data workflows.
Key Features of Apache Airflow:
- Directed Acyclic Graphs (DAGs): Airflow represents data workflows as DAGs, where each node in the graph represents a task, and the edges define the dependencies between tasks. This allows for easy visualization and management of complex workflows.
- Dynamic Task Generation: Airflow supports dynamic task generation, allowing tasks to be created programmatically or based on parameters, making it flexible for handling varying data processing requirements.
- Task Dependency and Scheduling: Airflow allows users to define task dependencies, specifying the order in which tasks should be executed. It also provides flexible scheduling options, supporting various schedules like cron expressions or specific time intervals.
3. Confluent
Confluent is a company that was founded by the creators of Apache Kafka, a popular open-source distributed streaming platform. The company provides a commercial platform and services built around Kafka to help organizations effectively manage and harness the power of real-time data streaming.
Key Components and Offerings of Confluent:
- Confluent Platform: The Confluent Platform is an enterprise-grade distribution of Apache Kafka, which includes additional tools, management capabilities, and features to simplify Kafka deployment, monitoring, and operation.
- Confluent Cloud: Confluent Cloud is a fully managed cloud service that offers Apache Kafka as a service. It allows users to quickly provision and scale Kafka clusters in the cloud without the need to manage infrastructure.
- Confluent for Kubernetes: Confluent provides a Kubernetes operator to facilitate the deployment and management of Kafka clusters within Kubernetes environments, making it easier to run Kafka on container orchestration platforms.
4. Talend Pipeline Designer
Talend Pipeline Designer is a cloud-based data integration tool provided by Talend, a leading data integration and ETL (Extract, Transform, Load) software vendor. Talend Pipeline Designer is part of the Talend Data Fabric platform, and it enables users to design and run data integration pipelines in the cloud.
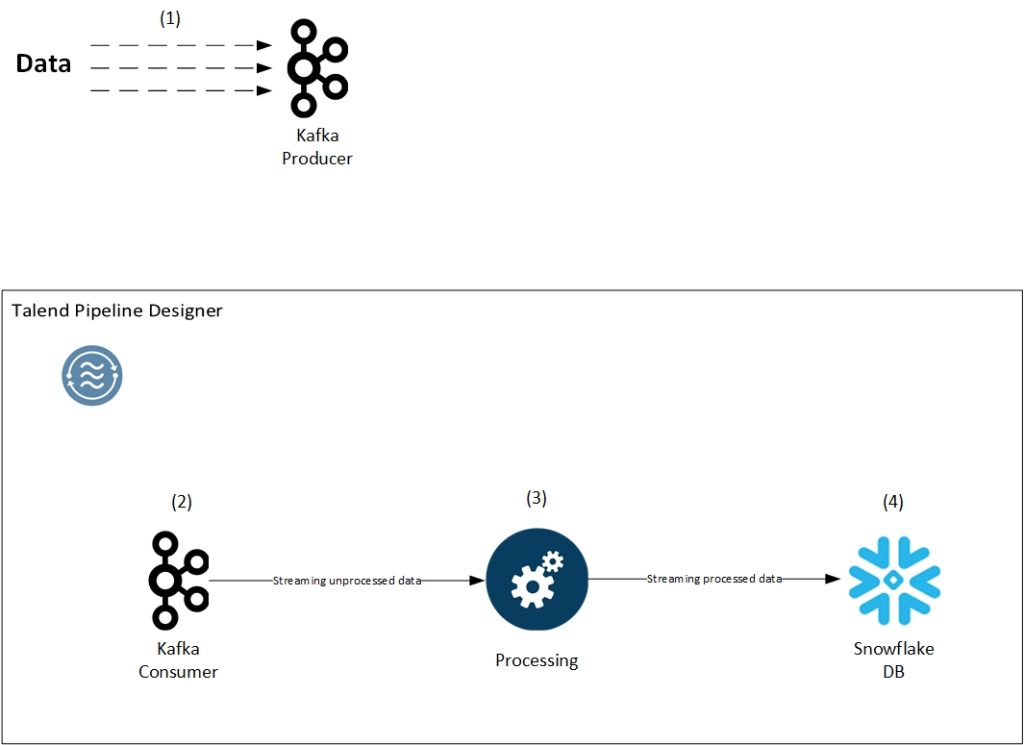
Key Features of Talend Pipeline Designer:
- Cloud-Native: Talend Pipeline Designer is a fully cloud-native solution, which means it runs on cloud infrastructure and allows users to create and manage data pipelines in the cloud environment.
- Data Connectivity: The tool supports connectivity to a wide range of data sources and applications, allowing users to extract data from various sources, including databases, cloud services, files, APIs, and more.
- Data Transformation: Talend Pipeline Designer provides a visual interface for designing data transformation operations. Users can easily configure data transformations such as data cleansing, data enrichment, data aggregation, and more.
5. StreamSets Data Collector
StreamSets Data Collector is an open-source data integration tool designed to ingest, process, and deliver data from various sources to different destinations. It is part of the StreamSets DataOps platform and is widely used for building data pipelines and streamlining data operations.
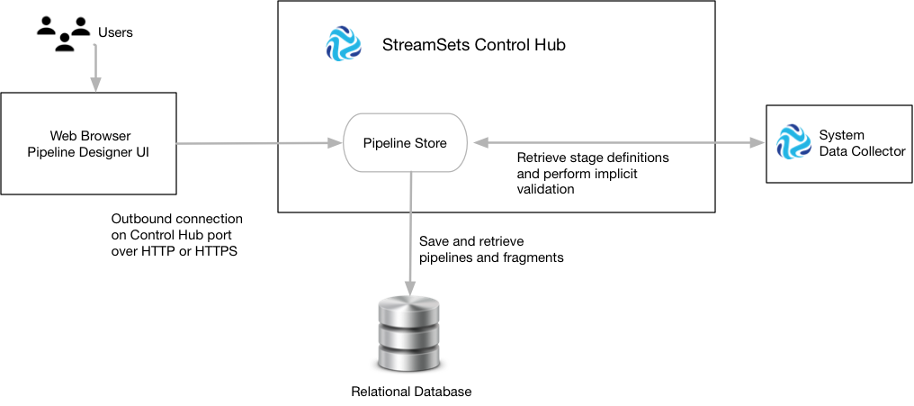
Key Features of StreamSets Data Collector:
- Data Connectivity: StreamSets Data Collector supports connectivity to a broad range of data sources, including databases, cloud services, web services, files, IoT devices, and more.
- Data Ingestion: The tool facilitates data ingestion from disparate sources and can handle real-time streaming data as well as batch data.
- Data Transformation: StreamSets Data Collector offers a visual interface for designing data transformation pipelines. Users can easily define data transformations, data cleansing, data enrichment, and data validation rules.
StreamSets Data Collector is designed to be easy to use, flexible, and reliable, making it a popular choice for data integration and data pipeline projects. It is widely used in modern data architectures to efficiently handle data movement and data processing tasks, especially in scenarios where real-time data processing is crucial. As an open-source tool, it benefits from an active community that continuously contributes to its improvement and enhancement.